DeepSeek会说话了!只要2行代码,这家公司让任意大模型秒开口
DeepSeek会说话了!只要2行代码,这家公司让任意大模型秒开口在AI行业新诞生的「多模态交互」赛道上,声网发布的「对话式AI引擎」,让所有文本大模型秒变多模态,具备实时语音对话能力,补齐了大模型「失语」的短板。
来自主题: AI资讯
11487 点击 2025-02-26 14:46
 搜索
搜索
在AI行业新诞生的「多模态交互」赛道上,声网发布的「对话式AI引擎」,让所有文本大模型秒变多模态,具备实时语音对话能力,补齐了大模型「失语」的短板。
尽管多模态大语言模型(MLLMs)取得了显著的进展,但现有的先进模型仍然缺乏与人类偏好的充分对齐。这一差距的存在主要是因为现有的对齐研究多集中于某些特定领域(例如减少幻觉问题),是否与人类偏好对齐可以全面提升MLLM的各种能力仍是一个未知数。
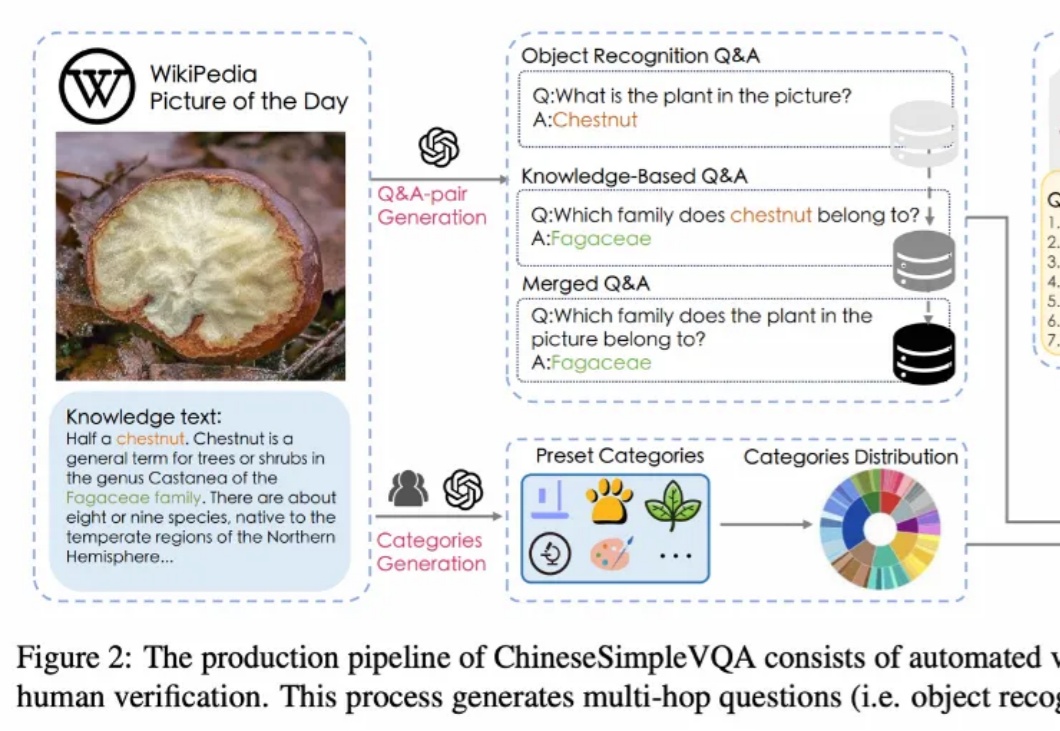
OpenAI o1视觉能力还是最强,模型们普遍“过于自信”!

回应DeepSeek,阶跃星辰亮出“三件套”:开源,多模态推理,AI Agent。

嘿,各位开发小伙伴,今天要给大家安利一个全新的开源项目 ——VLM-R1!它将 DeepSeek 的 R1 方法从纯文本领域成功迁移到了视觉语言领域,这意味着打开了对于多模态领域的想象空间!

2月19日,界面新闻记者获悉,阿里AI To C业务近期开启大规模人员招聘,开放招聘岗位达到数百个,其中AI技术、产品研发岗位占比达到90%,所招聘人员将重点投入到文本、多模态大模型、AI Agent等前沿技术与应用的相关工作中。

刚刚,阶跃星辰联合吉利汽车集团,开源了两款多模态大模型!新模型共2款:全球范围内参数量最大的开源视频生成模型Step-Video-T2V行业内首款产品级开源语音交互大模型Step-Audio多模态卷王开始开源多模态模型,其中Step-Video-T2V采用的还是最为开放宽松的MIT开源协议,可任意编辑和商业应用。
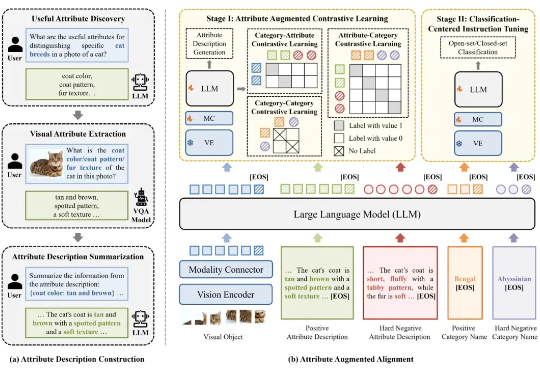
尽管多模态大模型在通用视觉理解任务中表现出色,但不具备细粒度视觉识别能力,这极大制约了多模态大模型的应用与发展。针对这一问题,北京大学彭宇新教授团队系统地分析了多模态大模型在细粒度视觉识别上所需的 3 项能力:对象信息提取能力、类别知识储备能力、对象 - 类别对齐能力,发现了「视觉对象与细粒度子类别未对齐」
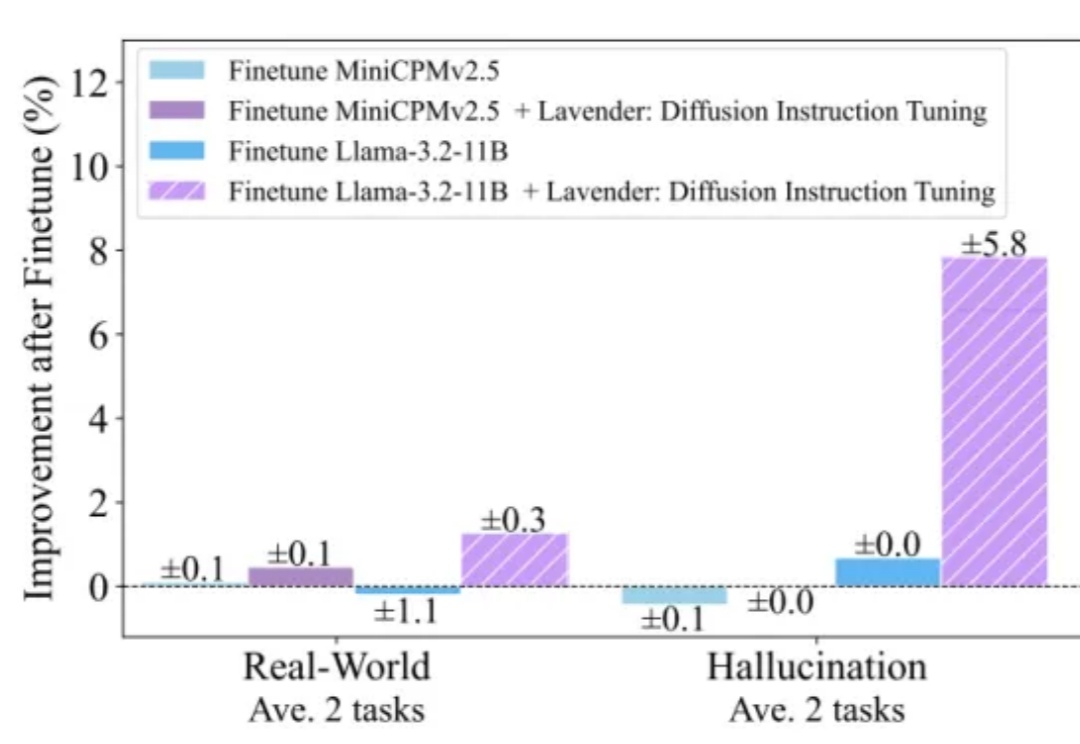
这次不是卷参数、卷算力,而是卷“跨界学习”——

近年来,多模态大模型(MLLM)在视觉理解领域突飞猛进,但如何让大语言模型(LLM)低成本掌握视觉生成能力仍是业界难题!