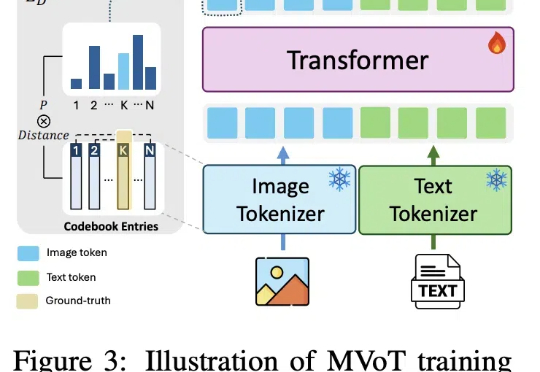
超越CoT!微软剑桥中科院提出MVoT,直接可视化多模态推理过程
超越CoT!微软剑桥中科院提出MVoT,直接可视化多模态推理过程近日,微软和剑桥大学公布推理新方法:多模态思维可视化MVoT。新方法可以边推理,边「想象」,同时利用文本和图像信息学习,在实验中比CoT拥有更好的可解释性和稳健性,复杂情况下甚至比CoT强20%。还可以与CoT组合,进一步提升模型性能。
来自主题: AI技术研报
7661 点击 2025-02-14 14:15
 搜索
搜索
近日,微软和剑桥大学公布推理新方法:多模态思维可视化MVoT。新方法可以边推理,边「想象」,同时利用文本和图像信息学习,在实验中比CoT拥有更好的可解释性和稳健性,复杂情况下甚至比CoT强20%。还可以与CoT组合,进一步提升模型性能。
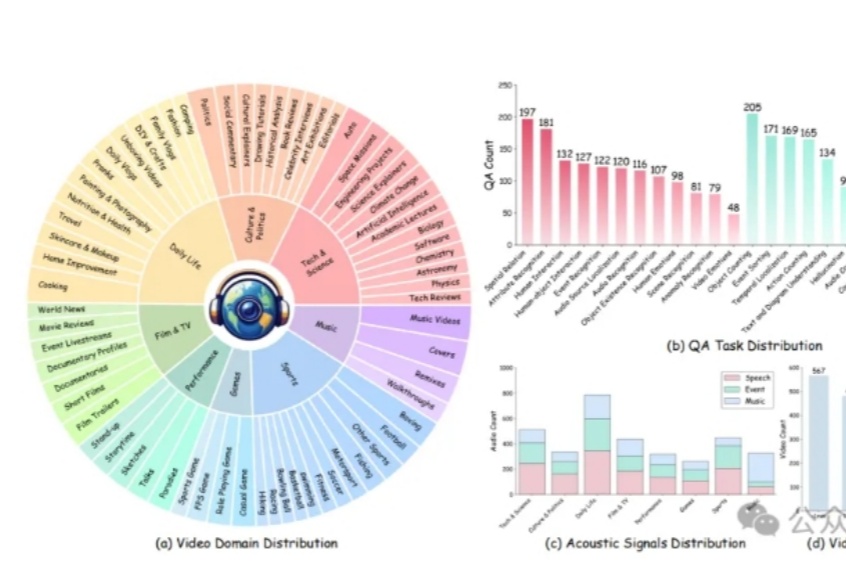
多模态大模型理解真实世界的水平到底如何?

人类通过课堂学习知识,并在实践中不断应用与创新。那么,多模态大模型(LMMs)能通过观看视频实现「课堂学习」吗?新加坡南洋理工大学S-Lab团队推出了Video-MMMU——全球首个评测视频知识获取能力的数据集,为AI迈向更高效的知识获取与应用开辟了新路径。
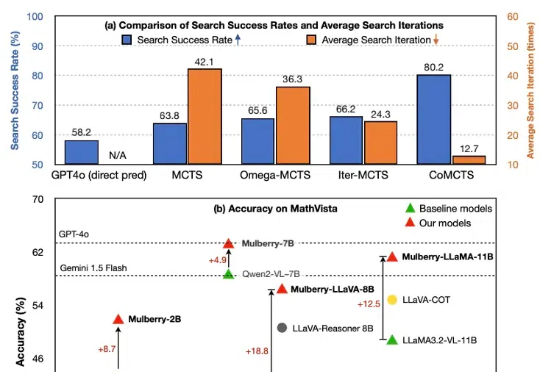
尽管多模态大语言模型(MLLM)在简单任务上最近取得了显著进展,但在复杂推理任务中表现仍然不佳。费曼的格言可能是这种现象的完美隐喻:只有掌握推理过程的每一步,才能真正解决问题。然而,当前的 MLLM 更擅长直接生成简短的最终答案,缺乏中间推理能力。本篇文章旨在开发一种通过学习创造推理过程中每个中间步骤直至最终答案的 MLLM,以实现问题的深入理解与解决。
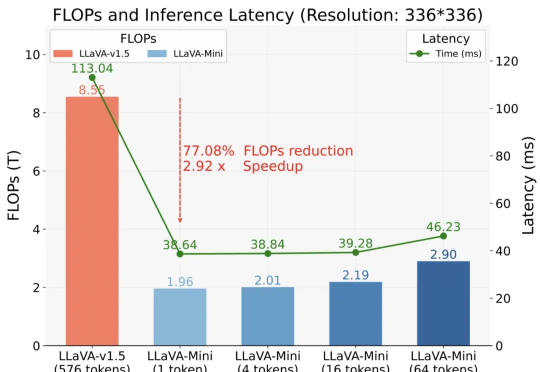
以 GPT-4o 为代表的实时交互多模态大模型(LMMs)引发了研究者对高效 LMM 的广泛关注。现有主流模型通过将视觉输入转化为大量视觉 tokens,并将其嵌入大语言模型(LLM)上下文来实现视觉信息理解。

还记得半年前在 X 上引起热议的肖像音频驱动技术 Loopy 吗?升级版技术方案来了,字节跳动数字人团队推出了新的多模态数字人方案 OmniHuman, 其可以对任意尺寸和人物占比的单张图片结合一段输入的音频进行视频生成,生成的人物视频效果生动,具有非常高的自然度。

记者从多方获悉,全球顶尖人工智能科学家许主洪教授(Steven Hoi)正式加入阿里巴巴,出任阿里集团副总裁,负责AI To C业务的多模态基础模型及Agents相关基础研究与应用解决方案。

在当前AI领域的快速发展中,“强推理慢思考”已经成为主要的发展动向之一,它们深刻影响着研发方向和投资决策。如何将强推理慢思考进一步推广到更多模态甚至是全模态场景,并且确保和人类的价值意图相一致,已成为一个极具前瞻性且至关重要的挑战。

2024年春节,我其实已经尝试过用AI的介入,来完成一些原本长辈需要我才能完成、但实际上并没有什么难度的问题。例如帮助长辈学习如何用提示词(Prompt),使用类似“什么问题+细节描述+发生场景+附加需求”这样的结构来获得更准确的回复,或是发掘一些AI App中自带的例如一键P图等功能。
就在除夕前的晚上(2025 年 1 月 27 日),Deepseek 发布了多模态模型 Janus-Pro-7B,该模型在图像生成和多模态理解方面都超过了OpenAI的DALL-E 3(虽然也一般般),我相信能文生图功能一定很优秀了,今天搞点特殊的,测试下图像理解能力对专业的医学影像有没有应用的可行性,以下是常见的五种医学影像测试。