# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

多模态AI是一种将不同形式的数据(如文本、图像、音频等)融合在一起的技术,旨在让模型从多个维度感知和理解信息。这种融合使得AI系统能够从每种模态中获取独特的但互补的信息,从而构建出更全面的世界观。例如,在一个自动驾驶场景中,图像数据可以帮助系统识别道路上的行人,而雷达数据则能够感知车距,两者结合能够显著提升决策准确性。
多模态AI的核心思想是突破单一模态的局限,通过多种模态的协同作用,提升模型的表现力和泛化能力。然而,融合这些异构数据带来了新的技术挑战:
1.模态之间的信息差异:不同模态的数据结构差异巨大。例如,文本是序列化的符号数据,而图像是二维的像素数据。如何有效地对不同模态进行表征,并找到合理的融合方式,是多模态AI的一个重要难题。通常,研究者会借助深度学习中的特征提取技术(如卷积神经网络用于图像、Transformer用于文本),为每种模态构建特征表示,再通过拼接、加权融合或注意力机制将它们结合在一起。
2.模态不一致性:在实际应用中,不同模态的数据可能并不总是齐全或一致。例如,自动驾驶车辆可能由于障碍物导致摄像头的部分数据丢失,或在某些医疗场景中,患者的部分病历记录不完整。这种情况下,AI系统需要具备应对模态缺失或不一致的能力,通过设计冗余机制或使用补全策略,确保模型在数据不完全的情况下仍能做出有效的决策。
因此,多模态AI不仅需要处理异构数据的融合问题,还要具备鲁棒性,以应对现实中可能出现的数据缺失和不一致情况。
多模态AI通过整合多种数据源,提升了AI系统对复杂任务的理解和处理能力,在各类行业中展现出了广泛的应用前景。
1.自动驾驶
自动驾驶技术高度依赖多模态数据的融合。自动驾驶车辆配备的摄像头捕捉道路图像,雷达提供距离和速度信息,激光雷达(LiDAR)生成3D点云用于精确建模周围环境。这些传感器采集的数据各具特点,图像数据擅长识别物体,而雷达和激光雷达则帮助测量距离和速度。通过融合这些不同模态的数据,自动驾驶系统能够准确感知环境,避免障碍物,并在复杂的驾驶场景中做出安全决策。
2.医疗诊断
多模态AI在医疗领域的应用极具潜力。结合医学影像(如X光、MRI扫描)和病历文本,AI系统可以从多方面对患者病情进行综合分析。影像数据有助于识别病灶和异常,文本数据则可以提供患者的症状、病史等背景信息。通过这种多模态的融合,AI不仅能够提升疾病检测的准确性,还能为医生提供诊断建议,助力个性化治疗方案的制定。
3.智能客服
现代智能客服系统不仅需要理解用户的语音和文本,还要对用户的情感和意图有准确的感知。多模态AI通过结合语音识别、自然语言处理和情感分析,能够为用户提供更加自然和个性化的交互体验。比如,当系统检测到用户在对话中的焦虑或不满时,它可以调整语言风格或策略,以更好地解决问题,提高用户满意度。
4.图像标注与生成
在内容创作和图像管理领域,多模态AI通过结合图像和文本数据,能够自动为图片生成标签或描述。这样的系统广泛应用于搜索引擎、社交媒体和电商平台。例如,当一张图片包含多个物体时,多模态AI可以生成详细的描述,如"一只狗在公园里跑步"。这不仅有助于图片的自动化管理和检索,还能为视觉内容生成提供新的创作工具。
多模态AI的广泛应用显示了它在处理复杂、真实世界任务中的强大潜力,通过将不同模态的数据有效融合,它为多个领域带来了创新性的解决方案。
1.数据预处理
多模态AI的首要步骤是对不同模态的数据进行标准化处理,以便模型能够有效地理解和操作这些数据。对于图像数据,通常使用卷积神经网络(CNN)来提取空间特征,而文本数据则可以通过循环神经网络(RNN)、长短期记忆网络(LSTM)或Transformer模型进行处理,来捕捉序列或上下文信息。音频、视频等其他模态也有专门的预处理方法,确保它们可以与其他模态无缝融合。
2.特征提取
在预处理后,每种模态的数据会通过专门的神经网络进行特征提取。图像数据通常采用预训练的CNN模型(如ResNet、VGG),这些模型可以有效提取高层次的图像特征。对于文本数据,BERT等预训练语言模型已经成为提取语义特征的标准工具,能够捕捉到复杂的上下文关系。音频数据通常采用卷积或递归网络提取时域或频域特征。使用预训练模型不仅可以加速训练,还能显著提升模型的表现。
3.模态融合
这是多模态AI的关键步骤,将来自不同模态的特征融合以形成联合表示。常见的融合方法包括:
(1)拼接:直接将不同模态的特征向量连接,形成一个长向量作为输入。
(2)加权平均:为每个模态的特征分配不同的权重,根据重要性来融合。
(3)注意力机制:通过注意力机制动态调整不同模态对最终决策的贡献,尤其适用于模态之间信息重要性不均衡的场景。
这些融合方法能有效结合各模态的特征,增强整体理解和表示能力。
4.联合表示学习
在完成模态融合之后,系统会基于融合后的特征进行进一步的学习。联合表示学习的目标是让多模态特征能够协同作用,互相补充,从而提高模型的泛化能力。通过联合表示学习,模型能够更好地捕捉不同模态之间的关联信息,并且在决策时利用这些多样化的信息源作出更智能的判断。这个过程通常通过深层神经网络来完成,如多层感知器(MLP)或带有注意力机制的Transformer网络。
通过数据预处理、特征提取、模态融合和联合表示学习,多模态AI系统能够从不同类型的数据中提取关键信息,实现多维度的智能决策。这一架构在复杂任务中展现了巨大的潜力。
接下来,我们用一个简单的例子展示如何结合图像和文本模态来进行多模态AI的建模。
1. 数据准备
我们将使用COCO数据集,它包含图像及其对应的文本描述。通过结合图像和文本特征,可以训练一个多模态模型来进行图像分类或描述生成。
2. 构建模型
我们将采用PyTorch框架,使用预训练的ResNet模型提取图像特征,用BERT模型提取文本特征,并将两者结合进行分类任务。

3. 数据预处理
我们需要对图像和文本数据进行预处理,分别使用PyTorch的transform工具对图像进行标准化,使用BERT的tokenizer处理文本。
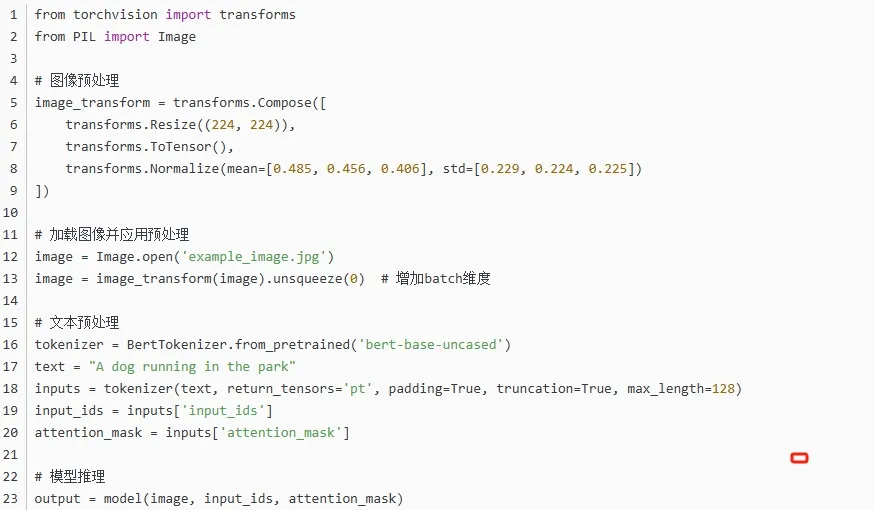
4. 模型训练
通过定义损失函数(如交叉熵损失)和优化器(如Adam),可以对多模态模型进行训练。

1.跨模态对话系统
未来的智能对话系统将不仅局限于文字和语音的理解,还将整合视觉、动作等多种模态,实现在复杂场景下的自然交互。比如,一个智能助理可以通过语音指令与用户对话,同时通过摄像头观察用户的表情或手势,理解其意图,从而提供更加精准的反馈和服务。这种多模态整合将大幅提升对话系统的智能性和用户体验。
2.多模态生成模型
生成对抗网络(GAN)和变分自编码器(VAE)的快速发展推动了多模态生成模型的进步。未来,基于这些技术的多模态AI不仅能生成与文本匹配的图片,还可以生成视频、音频等符合上下文的多种内容。这些生成模型将被广泛应用于内容创作、虚拟现实等领域,帮助创作者自动生成符合需求的多模态内容,带来前所未有的创作自由。
3.大规模预训练多模态模型
类似于GPT等大规模语言模型的成功,未来的多模态模型将通过大量跨模态数据进行预训练。随着计算能力的提升,这些模型将在处理海量图像、文本、音频等多模态数据时,表现出更强的泛化能力。通过大规模预训练,多模态AI将在跨模态理解、生成和推理任务中取得更广泛的应用,覆盖从智能问答到复杂环境感知的多样化任务。
多模态AI是未来智能系统的发展方向之一,通过融合不同类型的数据源,它让模型能够从多个维度理解和解决复杂问题,大幅提升了性能与智能化水平。无论是跨模态对话、多模态生成模型,还是大规模预训练技术,未来的多模态AI将在各个行业和应用场景中发挥更为重要的作用。随着研究的深入和技术的创新,多模态AI的应用范围将不断扩大,带来更智能和灵活的解决方案。
文章来自于“福建省信息技术人才协会”,作者“信息技术前沿咨询”。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
