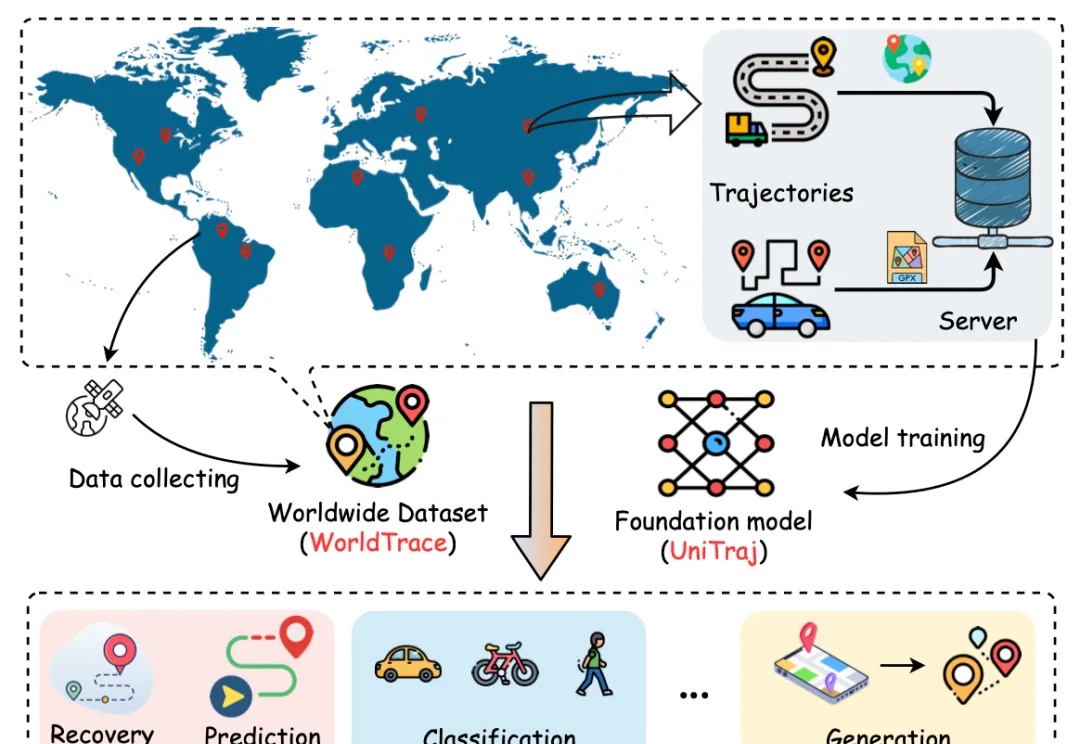
在智慧城市和大数据时代背景下,人类轨迹数据的分析对于交通优化、城市管理、物流配送等关键领域具有重要意义。然而,现有的轨迹相关模型往往受限于特定任务、区域依赖、轨迹数据规模和多样性困乏等问题,限制了模型的泛化能力和实际应用范围。
来自主题: AI技术研报
7717 点击 2024-11-22 17:21
 搜索
搜索
在智慧城市和大数据时代背景下,人类轨迹数据的分析对于交通优化、城市管理、物流配送等关键领域具有重要意义。然而,现有的轨迹相关模型往往受限于特定任务、区域依赖、轨迹数据规模和多样性困乏等问题,限制了模型的泛化能力和实际应用范围。
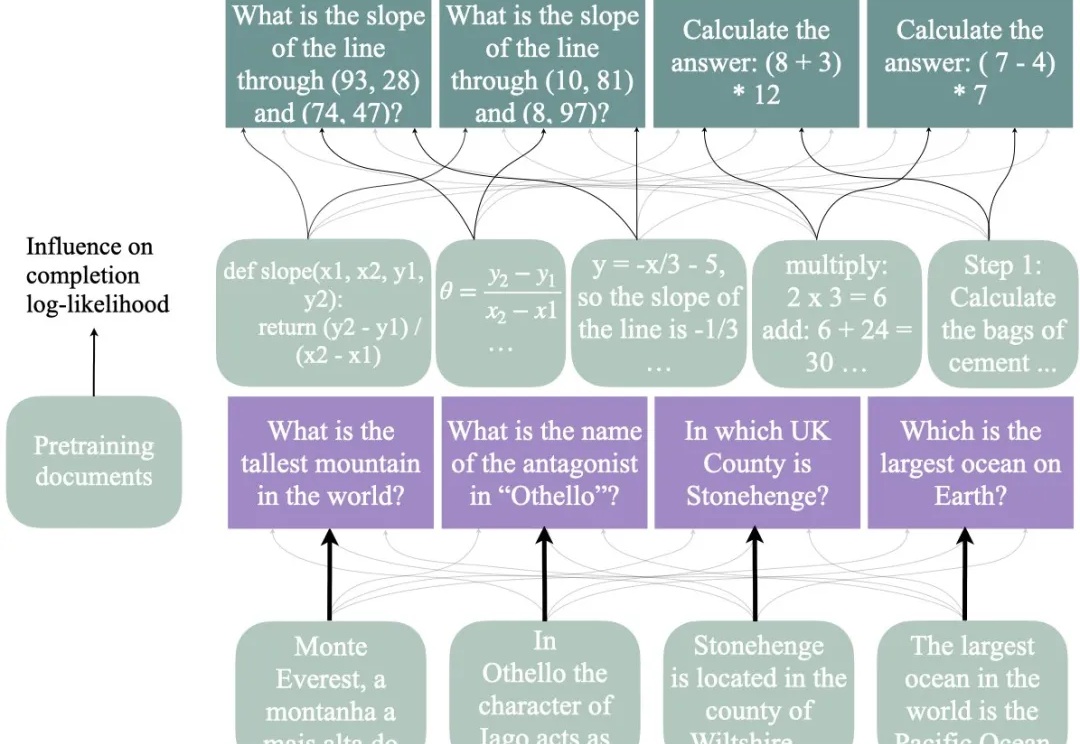
大模型不会照搬训练数据中的数学推理,回答事实问题和推理问题的「思路」也不一样。
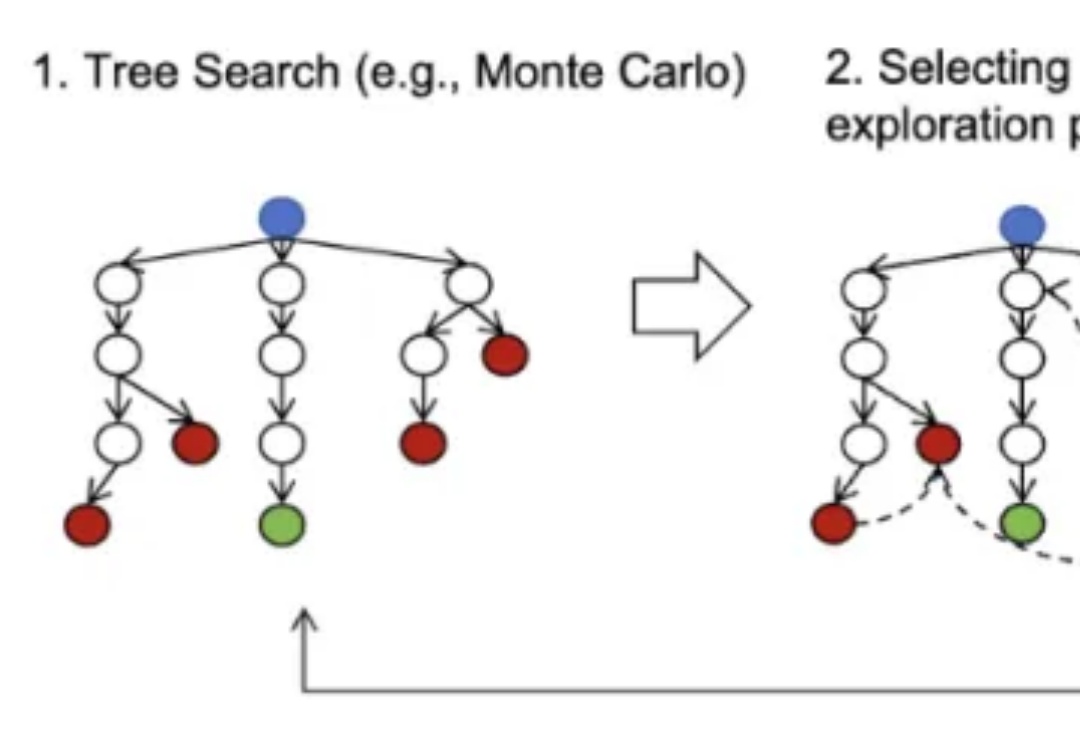
自从 OpenAI 发布展现出前所未有复杂推理能力的 o1 系列模型以来,全球掀起了一场 AI 能力 “复现” 竞赛。近日,上海交通大学 GAIR 研究团队在 o1 模型复现过程中取得新的突破,通过简单的知识蒸馏方法,团队成功使基础模型在数学推理能力上超越 o1-preview。
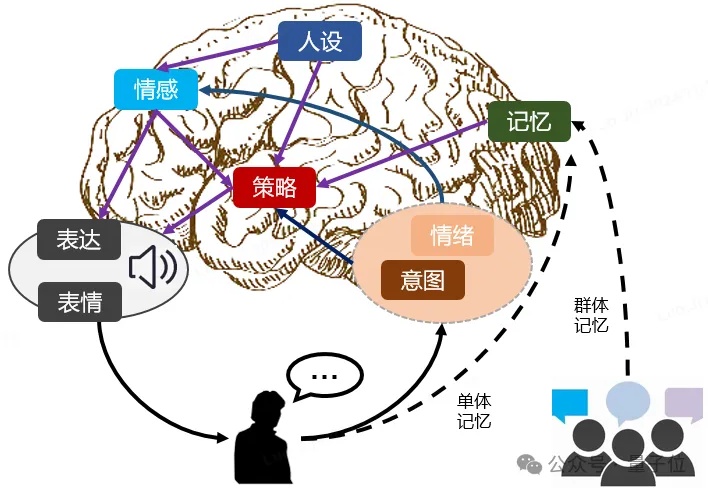
今天,如果你身边有这样一个对话大模型,它就像你身边的一个朋友,快言快语,风趣幽默,既会比喻,又会自嘲,偶尔跟你唱反调,你跟它的聊天欲望会不会更强一些呢?

人工智能虽然其提供了广泛的信息,却缺乏解决复杂问题所需的深入、结构化的推理能力,同时还存幻觉的局限。形式逻辑和相关数学工具为 AGI 的逻辑推理能力提供了必要的理论基础和技术支撑。

Scaling Law撞墙,扩展语言智能体的推理时计算实在太难了!破局之道,竟是使用LLM作为世界模型?OSU华人团队发现,使用GPT-4o作为世界模型来支持复杂环境中的规划,潜力巨大。
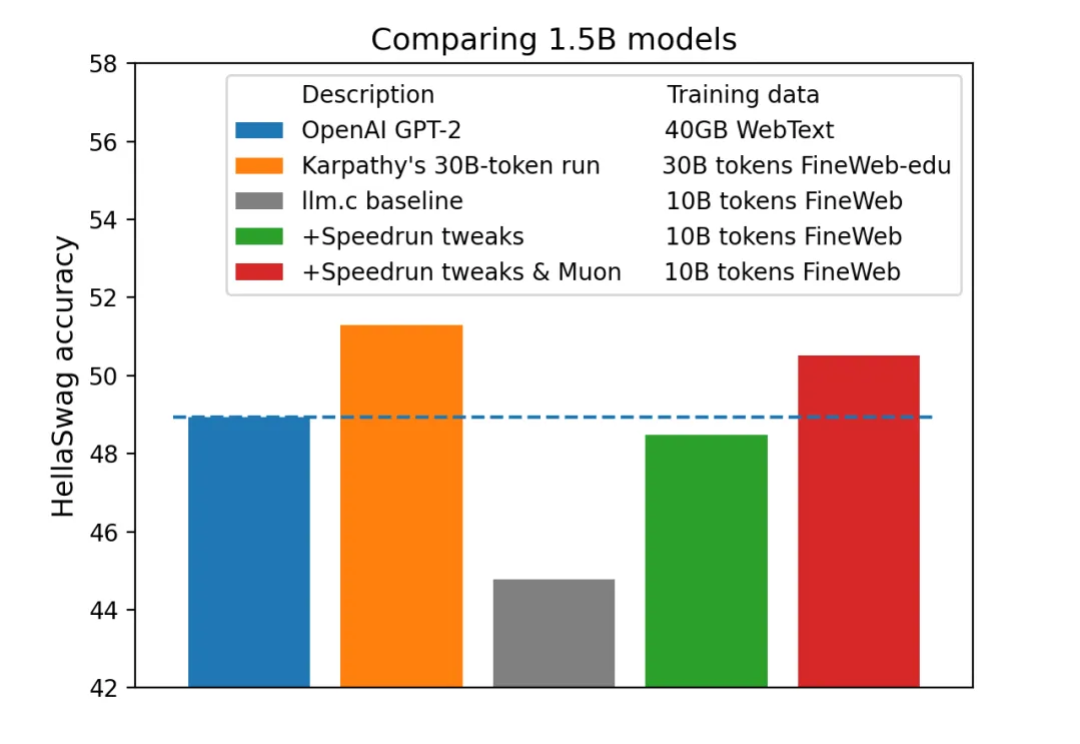
今年 4 月,AI 领域大牛 Karpathy 一个仅用 1000 行代码即可在 CPU/fp32 上实现 GPT-2 训练的项目「llm.c」曾经引发机器学习社区的热烈讨论。
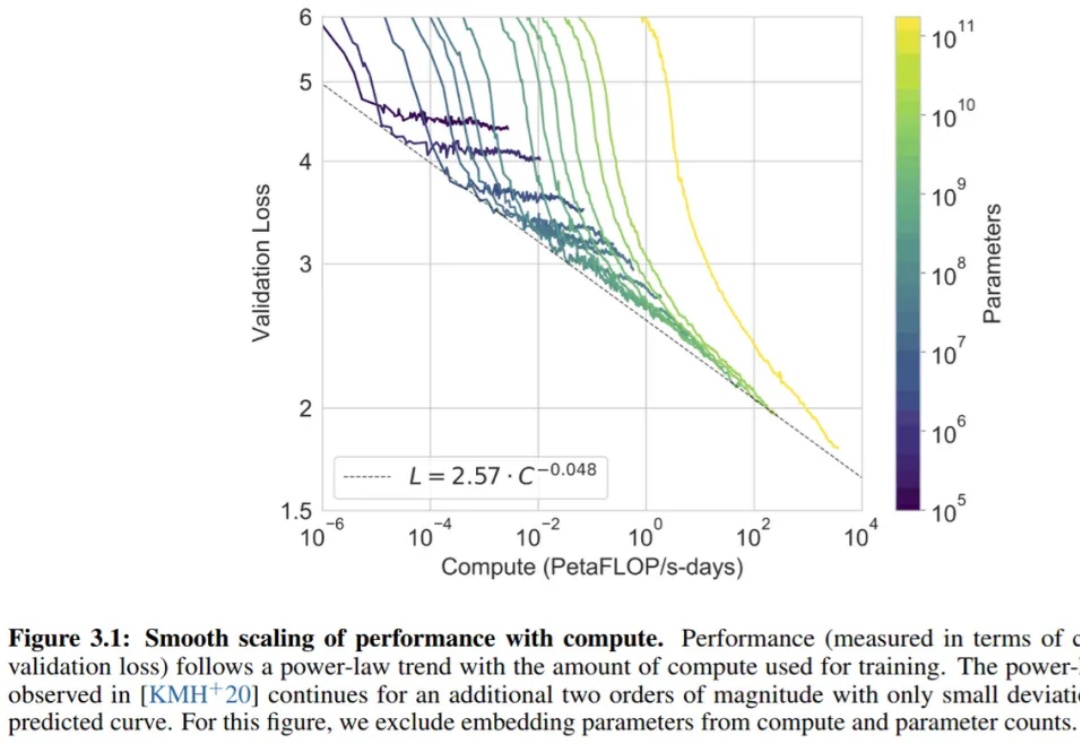
Powerful AI 预计会在 2026 年实现,足够强大的 AI 也能够将把一个世纪的科研进展压缩到 5-10 年实现(“Compressed 21st Century”),在他和 Lex Fridman 的最新对谈中,Dario 具体解释了自己对于 Powerful AI 可能带来的机会的理解,以及 scaling law、RL、Compute Use 等模型训练和产品的细节进行了分享
网上关于大模型的文章也很多,但是都不太容易看懂。小枣君今天试着写一篇,争取做到通俗易懂。
简单性可以扩展:PyTorch的成功源于其对研究人员简单性的关注,这种关注随后流向了生产环境。在Fireworks,他们在幕后拥抱了巨大的复杂性,以提供一个简单的API给开发者。这种方法让客户能够专注于创新和产品设计,而不是纠结于技术复杂性。