来自主题: AI资讯
8654 点击 2024-09-04 23:19
 搜索
搜索
基于公司私有组件生成代码,这个问题的本质是:由于大模型的训练数据集不包含你公司的私有组件数据,因此不能够生成符合公司私有组件库的代码。

2024年,落地,无疑是大模型最重要的主题。
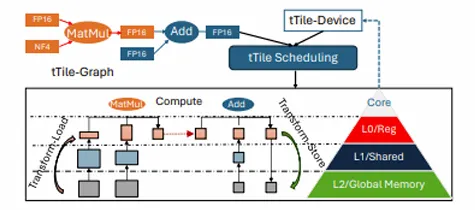
在人工智能领域,模型参数的增多往往意味着性能的提升。但随着模型规模的扩大,其对终端设备的算力与内存需求也日益增加。低比特量化技术,由于可以大幅降低存储和计算成本并提升推理效率,已成为实现大模型在资源受限设备上高效运行的关键技术之一。然而,如果硬件设备不支持低比特量化后的数据模式,那么低比特量化的优势将无法发挥。

有CPU就能跑大模型,性能甚至超过NPU/GPU!

单卡搞定Llama 3.1(405B),最新大模型压缩工具来了!
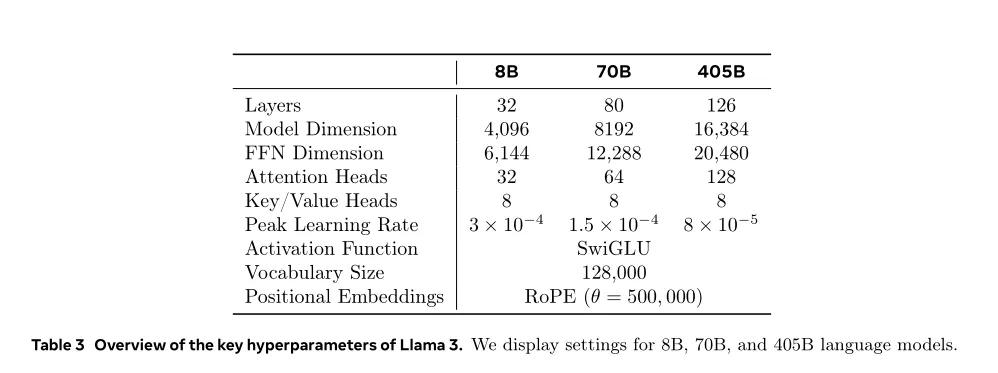
不同类型的数据配比如何配置:先通过小规模实验确定最优配比,然后将其应用到大模型的训练中。 Token配比结论:通用知识50%;数学与逻辑25%;代码17%;多语言8%。

千亿参数规模的大模型推理,服务器仅用4颗CPU就能实现!

英伟达NIM新升级,助力AI在多领域应用。
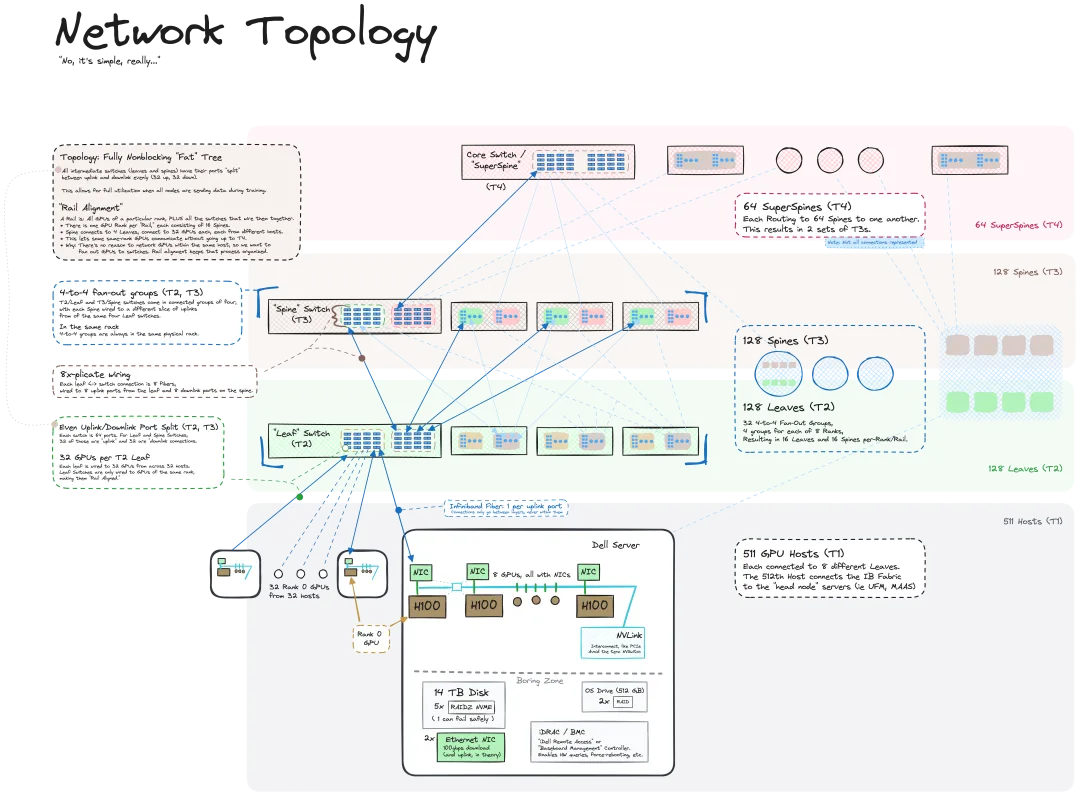
我们知道 LLM 是在大规模计算机集群上使用海量数据训练得到的,机器之心曾介绍过不少用于辅助和改进 LLM 训练流程的方法和技术。而今天,我们要分享的是一篇深入技术底层的文章,介绍如何将一堆连操作系统也没有的「裸机」变成用于训练 LLM 的计算机集群。