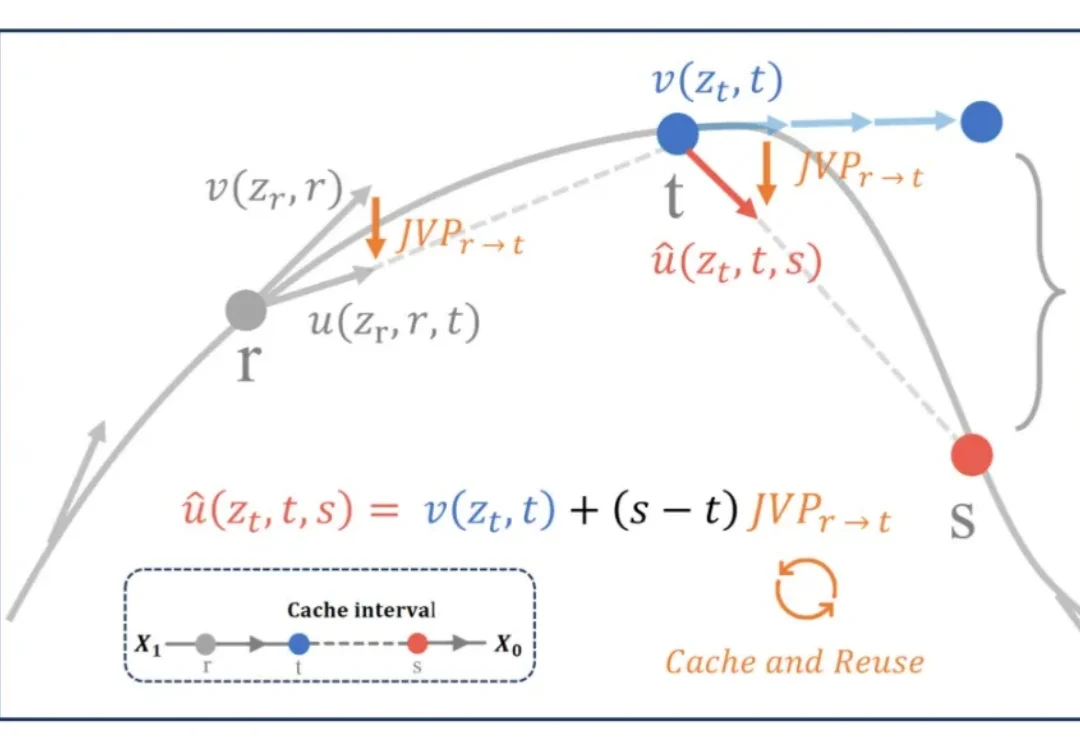
阿里首个世界模型:快乐…生蚝
阿里首个世界模型:快乐…生蚝就在刚刚,成立恰满一个月的阿里ATH(Alibaba Token Hub)事业群,发布全球首个主动式实时交互的世界模型产品。名也挺有趣的,叫HappyOyster(快乐生蚝)。HappyOyster搭载原生多模态架构,背后是支持多模态输入与音视频联合生成的流式生成世界模型,核心主打漫游(Wander)、导演(Direct)、创造(Create)、分享(Share)。
来自主题: AI资讯
8556 点击 2026-04-17 15:24