
结构化表格也成模态!浙大TableGPT2开源,最强表格AI问世
结构化表格也成模态!浙大TableGPT2开源,最强表格AI问世现在正是多模态大模型的时代,图像、视频、音频、3D、甚至气象运动都在纷纷与大型语言模型的原生文本模态组合。而浙江大学及其计算机创新技术研究院的一个数十人团队也将结构化数据(包括数据库、数仓、表格、json 等)视为了一种独立模态。
来自主题: AI技术研报
6531 点击 2024-11-07 17:45
 搜索
搜索
现在正是多模态大模型的时代,图像、视频、音频、3D、甚至气象运动都在纷纷与大型语言模型的原生文本模态组合。而浙江大学及其计算机创新技术研究院的一个数十人团队也将结构化数据(包括数据库、数仓、表格、json 等)视为了一种独立模态。

来自中科大等单位的研究团队共同提出了用来有效评估多模态大模型预训练质量的评估指标 Modality Integration Rate(MIR),能够快速准确地评估多模态预训练的模态对齐程度。

Ferret-UI 2 是苹果研究团队最新发表的一款先进的多模态大型语言模型(MLLM),旨在实现跨多个平台的通用用户界面(UI)理解。

GPT-4o 四月发布会掀起了视频理解的热潮,而开源领军者Qwen2也对视频毫不手软,在各个视频评测基准上狠狠秀了一把肌肉。
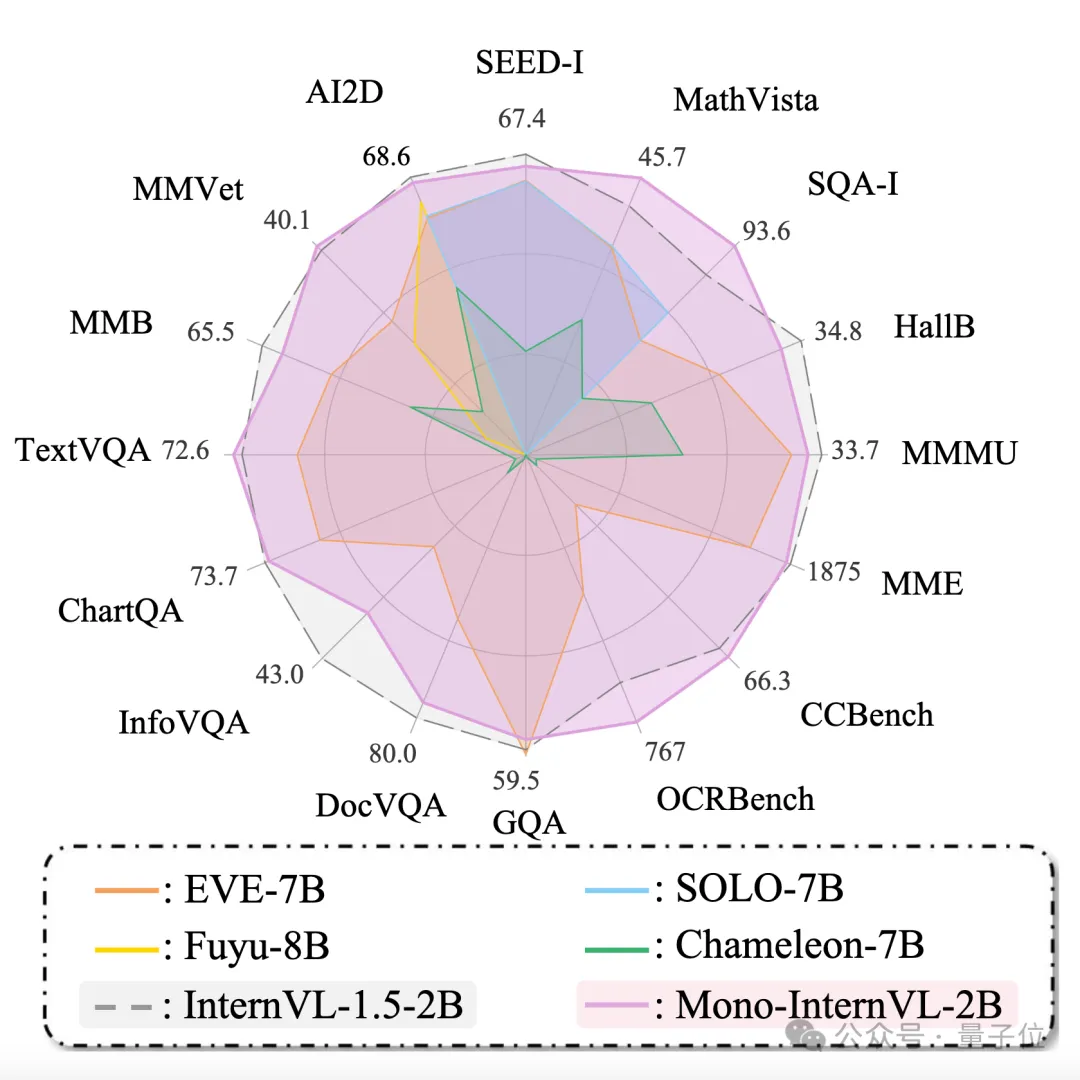
原生多模态大模型性能瓶颈,迎来新突破! 上海AI Lab代季峰老师团队,提出了全新的原生多模态大模型Mono-InternVL。 与非原生模型相比,该模型首个单词延迟最多降低67%,在多个评测数据集上均达到了SOTA水准。

视频多模态大模型(LMMs)的发展受限于从网络获取大量高质量视频数据。为解决这一问题,我们提出了一种替代方法,创建一个专为视频指令跟随任务设计的高质量合成数据集,名为 LLaVA-Video-178K。

随着对现有互联网数据的预训练逐渐成熟,研究的探索空间正由预训练转向后期训练(Post-training),OpenAI o1 的发布正彰显了这一点。

善智者,动于九天之上。

扩展多模态大语言模型(MLLMs)的长上下文能力对于视频理解、高分辨率图像理解以及多模态智能体至关重要。这涉及一系列系统性的优化,包括模型架构、数据构建和训练策略,尤其要解决诸如随着图像增多性能下降以及高计算成本等挑战。
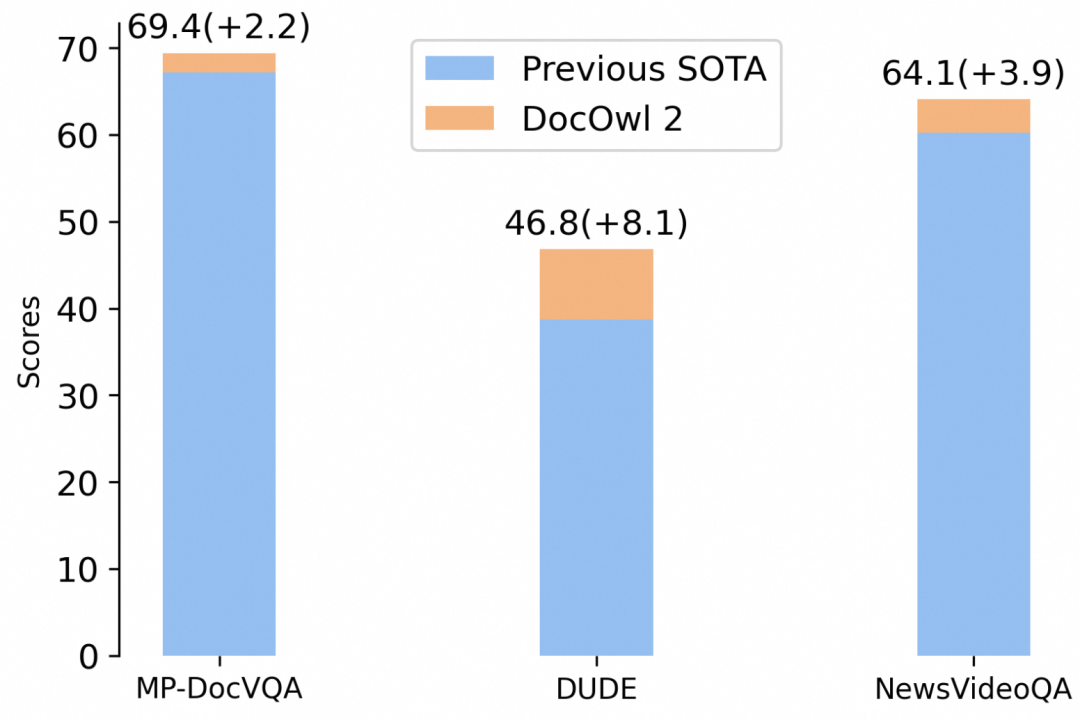
高效多页文档理解,阿里通义实验室mPLUG团队拿下新SOTA。