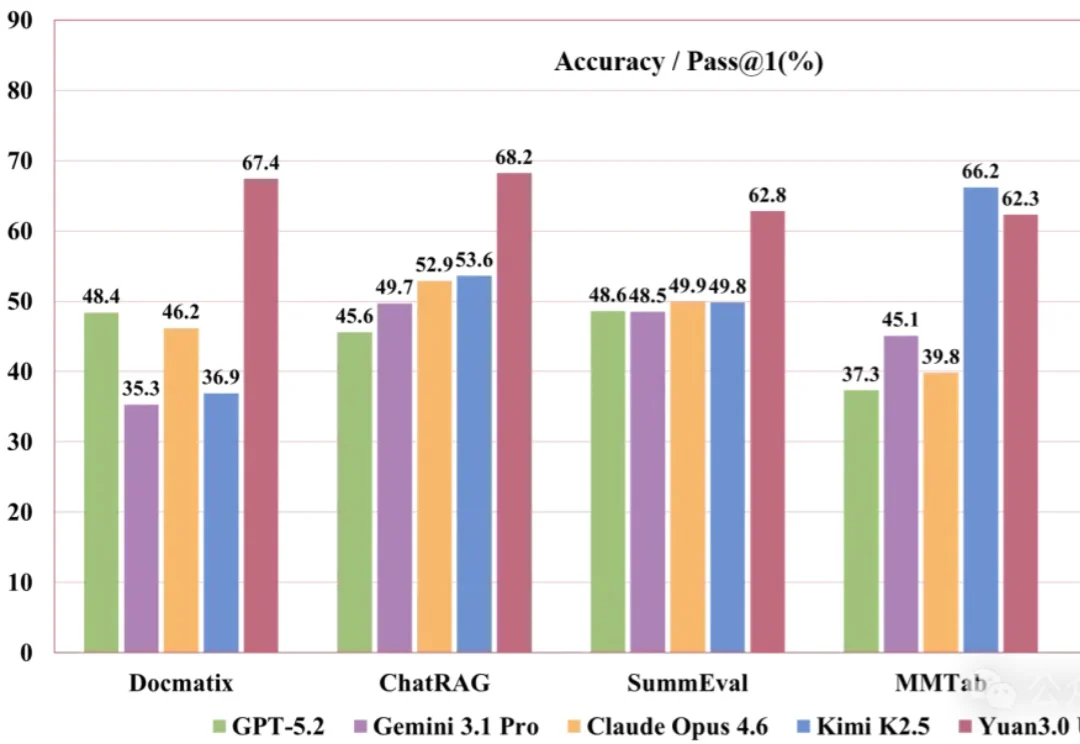
企业级OpenClaw最强拍档来了!万亿参数的国产多模态大模型,刚刚开源发布
企业级OpenClaw最强拍档来了!万亿参数的国产多模态大模型,刚刚开源发布刚刚,YuanLab.ai团队正式开源发布源Yuan3.0 Ultra多模态基础大模型。
来自主题: AI技术研报
10236 点击 2026-03-06 10:08
 搜索
搜索
刚刚,YuanLab.ai团队正式开源发布源Yuan3.0 Ultra多模态基础大模型。

伴随多模态大模型的发展,GUI Agent正成为人机交互的新范式。

没有图片,也能预训练多模态大模型?在多模态大模型(MLLM)的研发中,行业内长期遵循着一个昂贵的共识:没有图文对(Image-Text Pairs),就没有多模态能力。

Meta联合多所高校发布首个可规模化自动生成第一视角音视频理解数据的引擎EgoAVU ,让多模态大模型首次真正「听懂世界」。
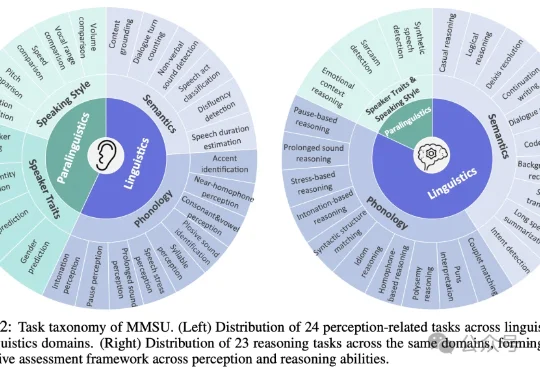
随着多模态大模型能力不断扩展,语音大模型(SpeechLLMs) 已从语音识别走向复杂语音交互。然而,当模型逐渐进入真实口语交互场景,一个更基础的问题浮现出来:我们是否真正定义清楚了「语音理解」的能力边界?
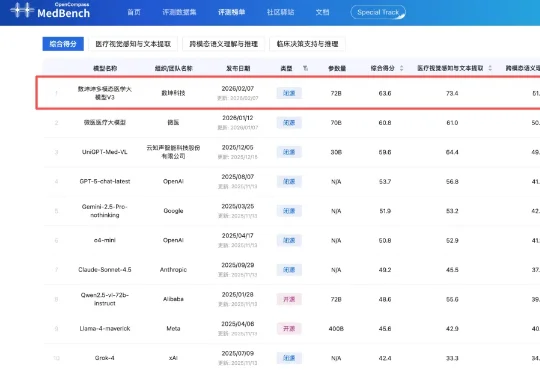
2月7日,中文医疗大模型评测平台MedBench公布最新多模态大模型评测榜单,数坤科技的数坤坤多模态医学大模型V3以63.6分拿下第一。在榜单中,V3的表现超过微医、云知声旗下医疗行业大模型,以及OpenAI、谷歌、阿里千问旗下通用大模型。

周伯文还详细介绍了上海 AI 实验室近年来开展的前沿探索与实践,包括驱动 “通专融合” 发展的技术架构 ——“智者”SAGE(Synergistic Architecture for Generalizable Experts),其包含基础、融合与进化三个层次,并可双向循环实现全栈进化;支撑 AGI4S 探索的两大基础设施“书生”科学多模态大模型 Intern-S1、“

为什么让多模态大模型“一步一步思考”(”Let’s think step by step”)来回答视频问题,效果有时甚至还不如让它“直接回答”?
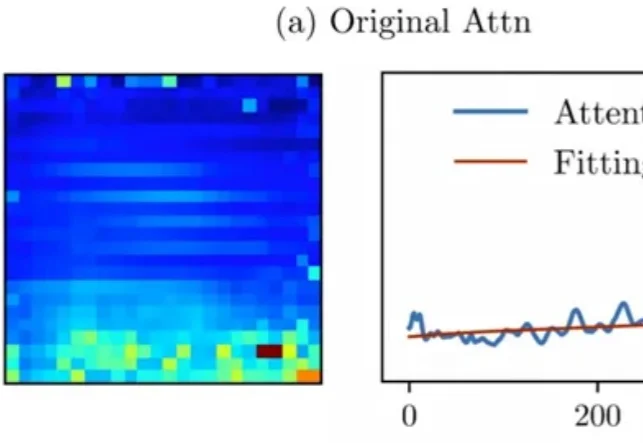
Attention真的可靠吗?
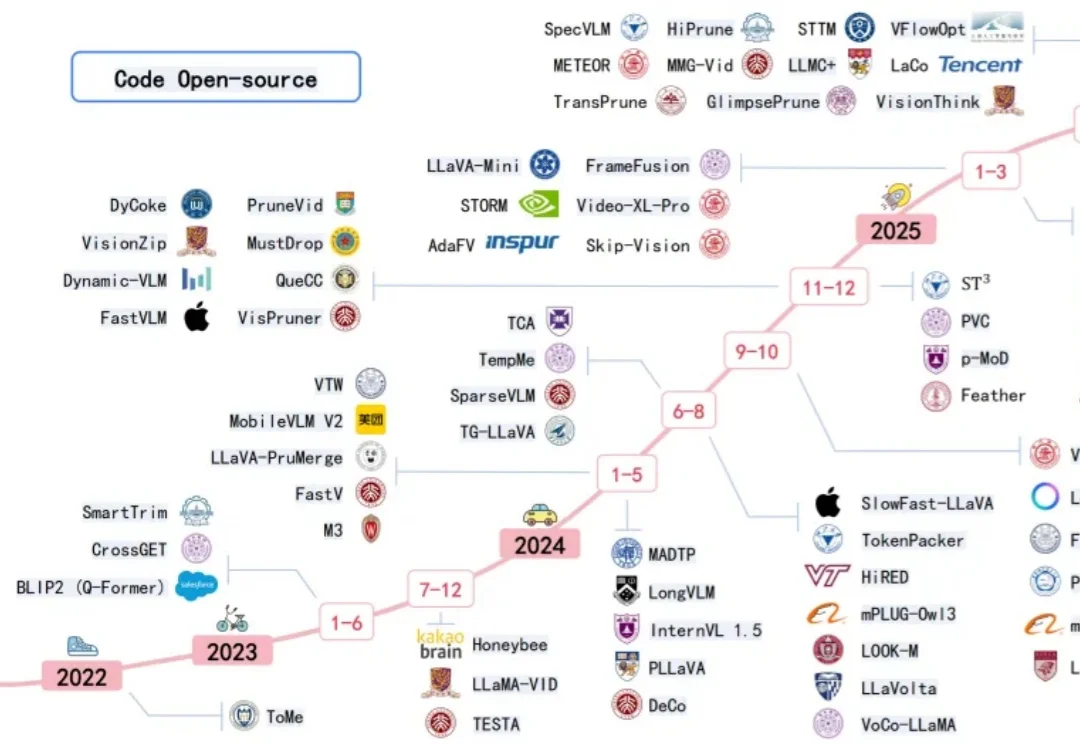
近年来多模态大模型在视觉感知,长视频问答等方面涌现出了强劲的性能,但是这种跨模态融合也带来了巨大的计算成本。高分辨率图像和长视频会产生成千上万个视觉 token ,带来极高的显存占用和延迟,限制了模型的可扩展性和本地部署。