
Nature专业户DeepMind又登封面,开源水印技术SynthID-Text,Gemini已经用上了
Nature专业户DeepMind又登封面,开源水印技术SynthID-Text,Gemini已经用上了现如今,大型语言模型(LLM)生成的内容已经充斥了整个互联网,并且这些模型还能模仿各种类似真人的语气和行文风格,让人难以分辨眼前的文本究竟来自人类还是 AI。
来自主题: AI技术研报
4499 点击 2024-10-24 15:37
 搜索
搜索
现如今,大型语言模型(LLM)生成的内容已经充斥了整个互联网,并且这些模型还能模仿各种类似真人的语气和行文风格,让人难以分辨眼前的文本究竟来自人类还是 AI。

大型语言模型(LLMs)虽然在适应新任务方面取得了长足进步,但它们仍面临着巨大的计算资源消耗,尤其在复杂领域的表现往往不尽如人意。

大型语言模型 (LLM) 在各种自然语言处理和推理任务中表现出卓越的能力,某些应用场景甚至超越了人类的表现。然而,这类模型在最基础的算术问题的表现上却不尽如人意。
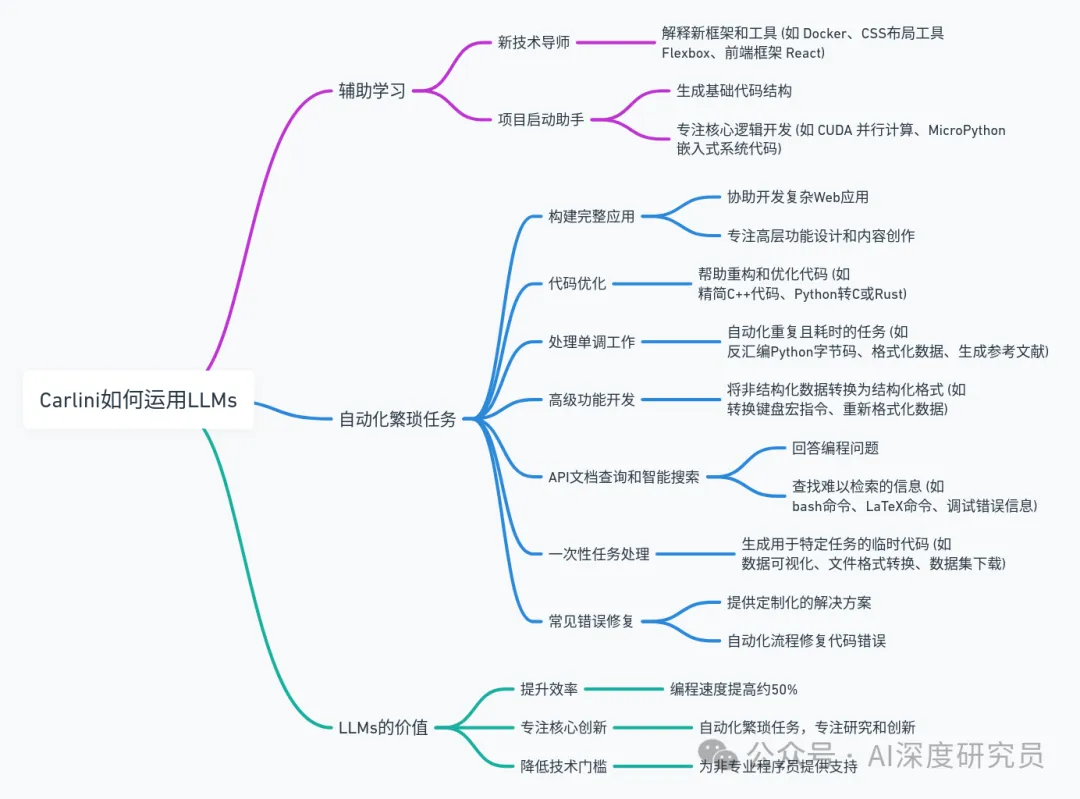
在当今科技界,关于人工智能是否被过度炒作的争论从未停息。然而,很少有像谷歌 DeepMind 的安全研究专家和机器学习科学家 Nicholas Carlini 这样的专家,用亲身经历为我们提供了一个独特的视角。通过他的文章,我们看到了大型语言模型(LLM)在实际应用中的强大能力和多样性。这些并非空洞的营销宣传,而是切实可以改变工作方式、提高生产效率、激发创意的工具。

按照传统,FDA会每年秋季都会更新一次人工智能数据库,目前,FDA数据库中共有950个设备。 截至2024年10月,还没有任何使用生成式人工智能或由大型语言模型驱动的设备获批。

本文是一篇发表在 NeurIPS 2024 上的论文,单位是香港大学、Sea AI Lab、Contextual AI 和俄亥俄州立大学。论文主要探讨了大型语言模型(LLMs)的词表大小对模型性能的影响。

RAG(Retrieval-Augmented Generation)是一种结合信息检索与文本生成的技术,旨在提高大型语言模型(LLM)在回答复杂查询时的表现。它通过检索相关的上下文信息来增强生成答案的质量和准确性。解读RAG测评:关键指标与应用分析

Transformer 的强大实力已经在诸多大型语言模型(LLM)上得到了证明,但该架构远非完美,也有很多研究者致力于改进这一架构,比如机器之心曾报道过的 Reformer 和 Infini-Transformer。

知名开源数据科学平台提供商Anaconda 今天宣布推出AI Navigator,这是一款新型桌面应用程序,允许用户在笔记本电脑或个人电脑上本地运行一系列人工智能应用的大型语言模型(LLMs),而无需将任何数据发送到云服务器。
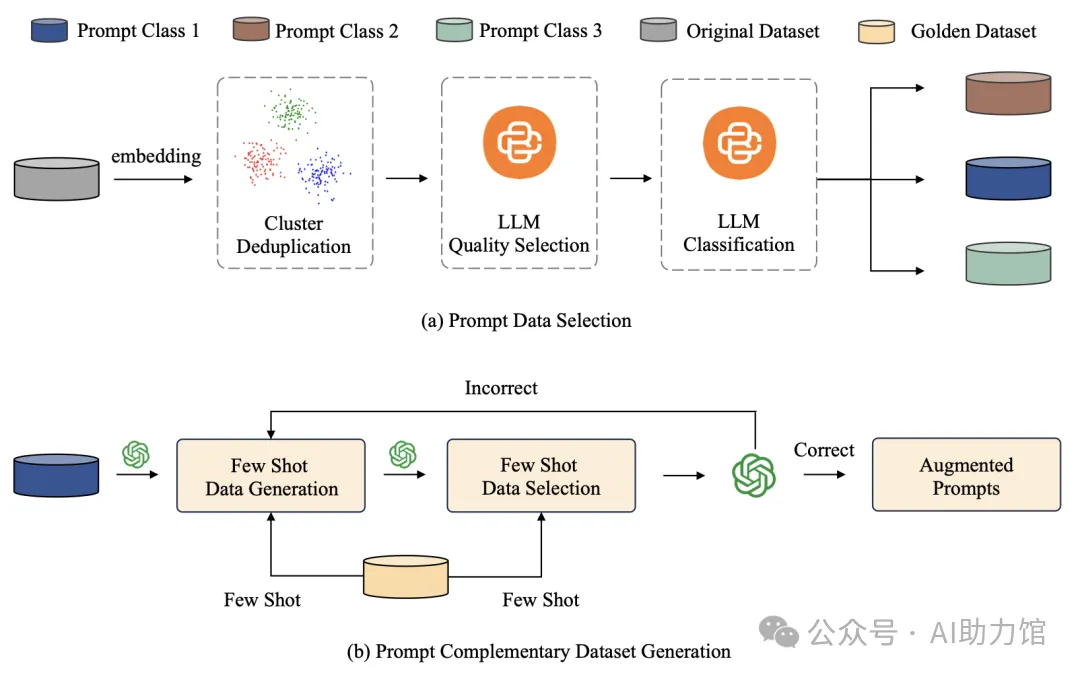
在人工智能的世界里,大型语言模型(LLM)已经成为我们探索未知、解决问题的得力助手。但是,你在编写AI提示词时,是否觉得这个过程就像在“炼丹”,既神秘又难以掌握?别担心,自动提示工程(APE)来帮你了!