

TokenDance 内测开启,同期发布百亿补贴计划!
TokenDance 内测开启,同期发布百亿补贴计划!我们发布了TokenDance 词元跳动,一站式大模型 API 调用平台。希望能够赋能更多观猹生态内的 AI 企业、OPC 开发者与 AI 爱好者,帮助 AI 时代的创造者们,省一些成本,多一些创造。
来自主题: AI资讯
6390 点击 2026-04-15 09:22
我们发布了TokenDance 词元跳动,一站式大模型 API 调用平台。希望能够赋能更多观猹生态内的 AI 企业、OPC 开发者与 AI 爱好者,帮助 AI 时代的创造者们,省一些成本,多一些创造。
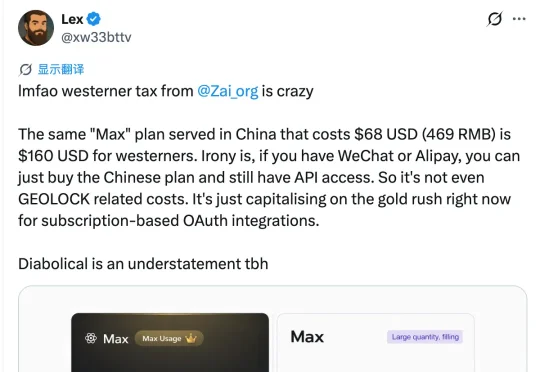
现在,轮到国产模型开始收割老外了。 有网友发现,智谱的Max计划在中国只要469元人民币,折合差不多68美元; 可到了西方用户手里,直接飙到160美元,足足贵了一倍多。

试想一下,如果把当下大火的大模型技术带回 1970 年,会发生什么?

过去一年,大模型的能力曲线几乎是指数上升的——推理更强、工具调用更稳、上下文窗口越撑越大。但一个越来越尖锐的问题也随之浮出水面:模型变强了,可承接它的那层东西在哪?
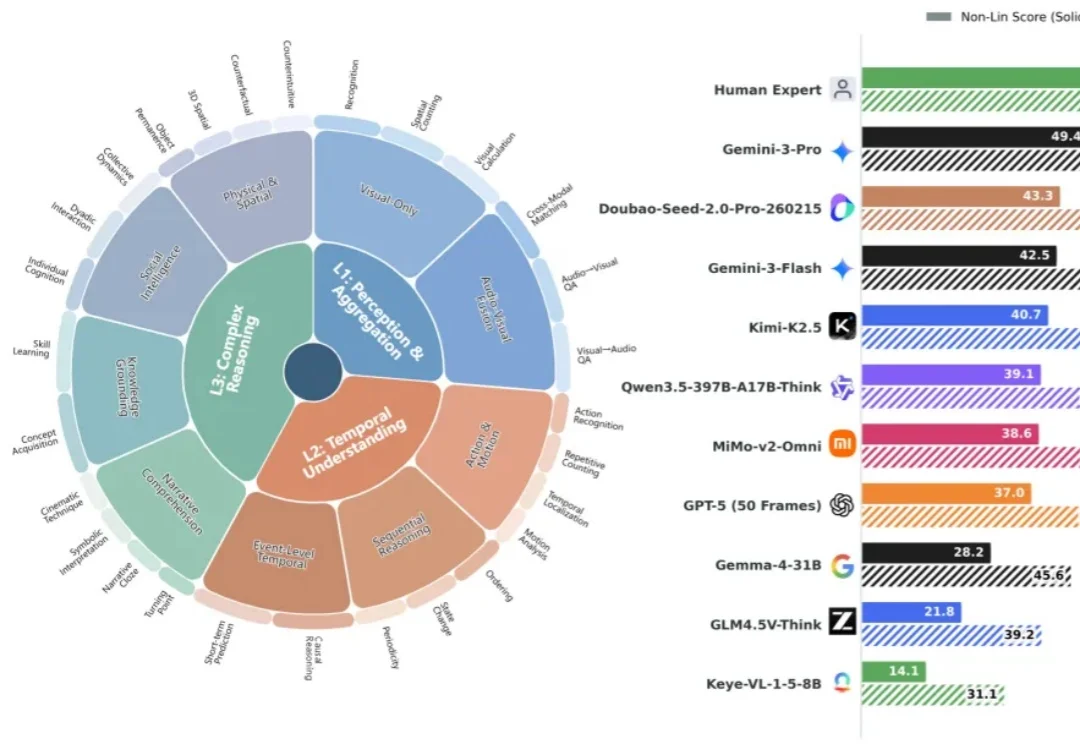
现有大模型评测分数日趋饱和,但与真实体验差距显著。南京大学傅朝友团队牵头,在 Google Gemini 评测团队邀约下推出视频理解新基准 Video-MME-v2。凭借创新的分层能力体系与组级非线性评分,以及 3300 + 人工时高质量标注,揭示模型与人类的巨大鸿沟(49 vs 90)、传统 Acc 指标虚高、以及 “Thinking” 并非总是增益等现象。

从 2024 年底的关于潜在空间的早期探索,再到 2025 年底和 2026 年初的相关研究爆发,潜空间范式正在彻底重塑大模型 (LLMs, VLMs, VLAs 等延伸模型) 的底层设计逻辑。

现有大模型评测分数日趋饱和,但与真实体验差距显著。南京大学傅朝友团队牵头,在Google Gemini评测团队邀约下推出视频理解新基准Video-MME-v2。凭借创新的分层能力体系与组级非线性评分,以及3300+人工时高质量标注,揭示模型与人类的巨大鸿沟(49vs90)、传统Acc指标虚高、以及「Thinking」并非总是增益等现象。

LangChain 只换了模型外面的基础设施——同一个模型、同一套权重——就从 TerminalBench 2.0 排行榜 30 名开外直接跳到了第 5 名。另一个独立研究项目让大模型自己优化这层基础设施,达到了 76.4% 的通过率,超过了所有人工设计的方案。
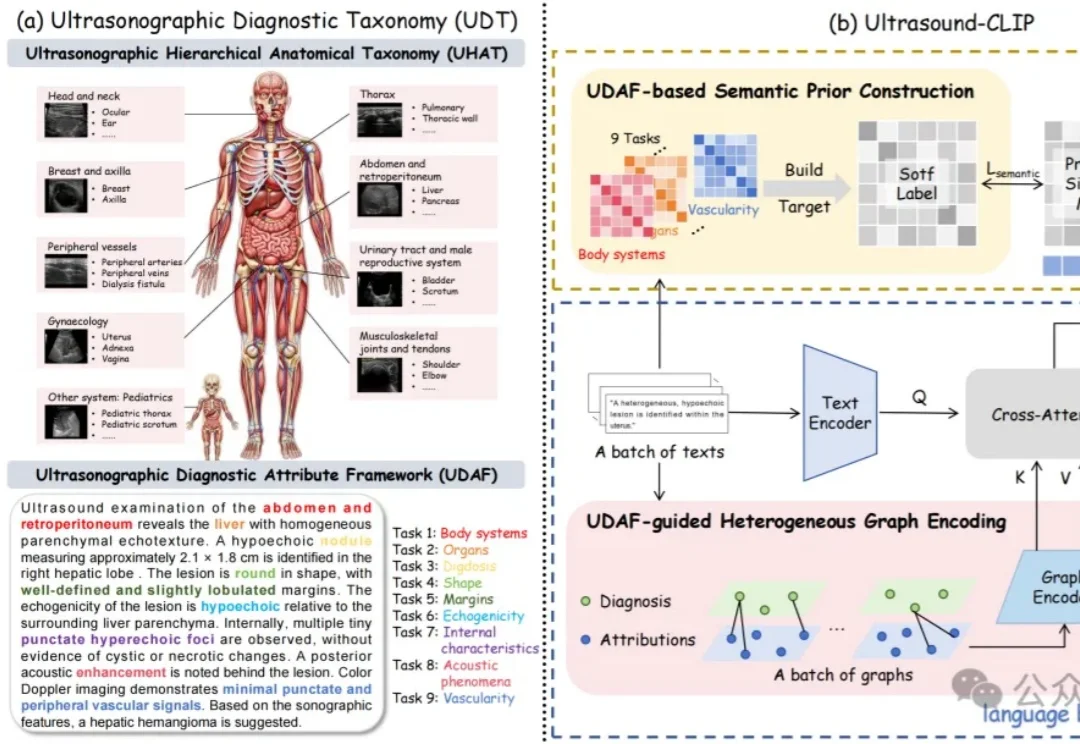
超声领域也有大模型了!

近日,哈尔滨工业大学(深圳)联合深圳河套学院、Independent Researcher提出了隐式思考模型 LRT(Latent Reasoning Tuning),通过一个轻量级的推理网络,将大模型冗长的「思维链」压缩为紧凑的隐式向量表征,一次前向计算即可完成推理,无需逐 token 生成数千字的中间推理过程。