
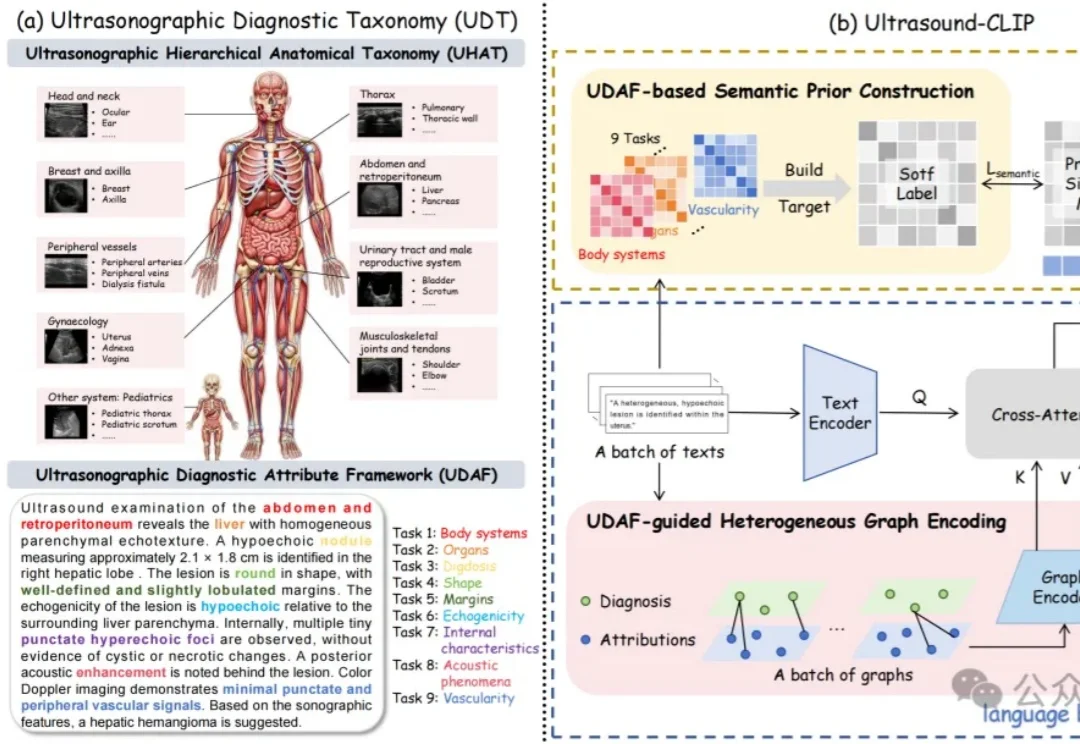
36.4万超声图文对!中国团队构建首个大规模超声专属数据集,让AI真正读懂临床诊断语义丨CVPR'26
36.4万超声图文对!中国团队构建首个大规模超声专属数据集,让AI真正读懂临床诊断语义丨CVPR'26超声领域也有大模型了!
来自主题: AI技术研报
8789 点击 2026-04-13 09:38
超声领域也有大模型了!

近日,哈尔滨工业大学(深圳)联合深圳河套学院、Independent Researcher提出了隐式思考模型 LRT(Latent Reasoning Tuning),通过一个轻量级的推理网络,将大模型冗长的「思维链」压缩为紧凑的隐式向量表征,一次前向计算即可完成推理,无需逐 token 生成数千字的中间推理过程。
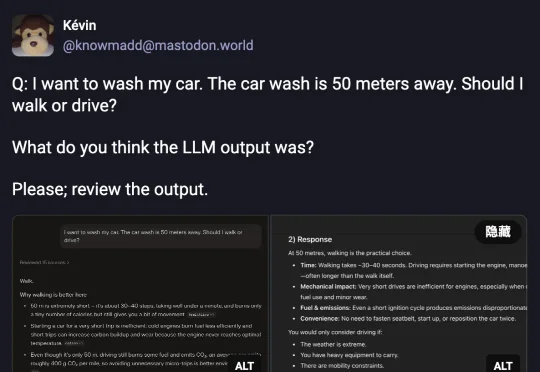
今年 2 月,一位 Mastodon 用户随手敲了一句话丢给四个主流大模型:「我想洗车,我家距离洗车店只有 50 米,请问你推荐我走路去还是开车去呢?」

4 月 10 日晚,灵初智能发布了大模型、数据集与合作计划:包括策略模型 Psi-R2、世界模型 Psi-W0,以及总规模近 10 万小时的人类操作数据。它想回答的问题也很直接 —— 当真机数据不再是唯一解,机器人还能靠什么继续 scaling?

字节Seed最新研究,让大模型能“原地改参数”了。既不用改模型结构,也不用重新训练,还跑得很快。具体是这么个情况。智能体时代嘛,大家都知道模型们面对的任务开始变得越来越复杂、上下文越来越长。

AI交互的「机械感」消失了!今天,豆包甩出原生全双工语音大模型Seeduplex,不仅能边听边说,甚至能听懂你在思考时的「卡壳」,就算环境再吵也不怕,抗干扰能力直接拉满。
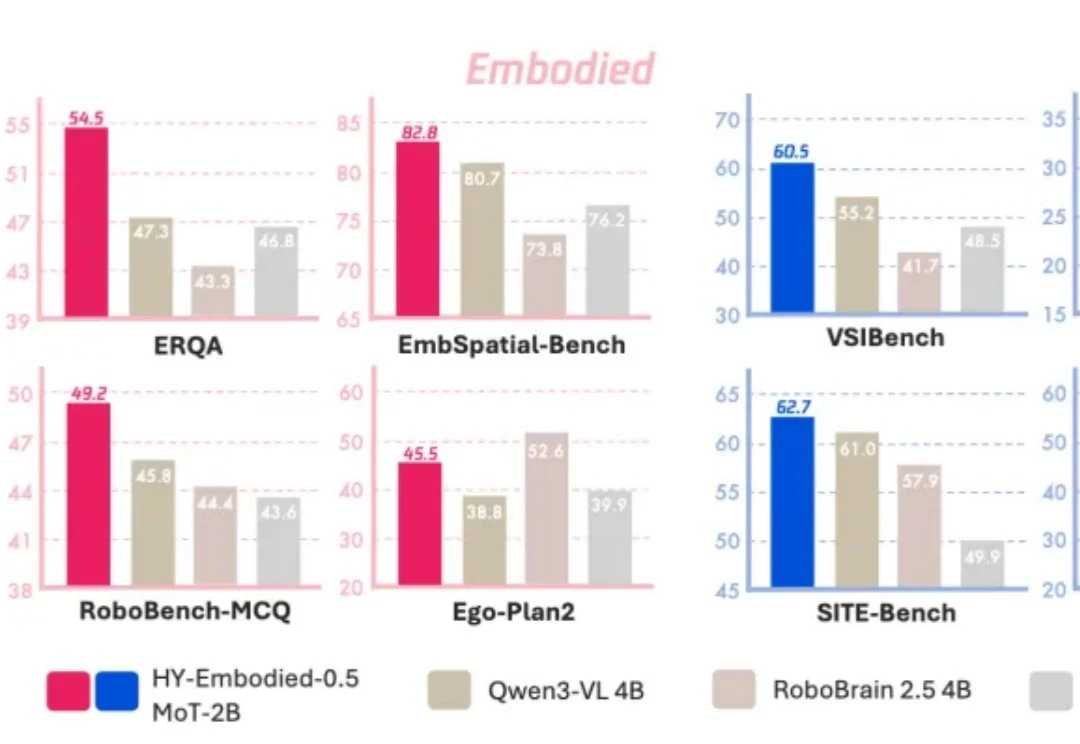
让大模型真正走进现实世界,是当下最迫切的需求之一。

RL之后,大模型为什么更容易「越训越单一」?面对五花八门的改进思路,也许答案并不复杂:先试着改一改KL项。

被动成为新一代 AI 黄埔军校的字节跳动。
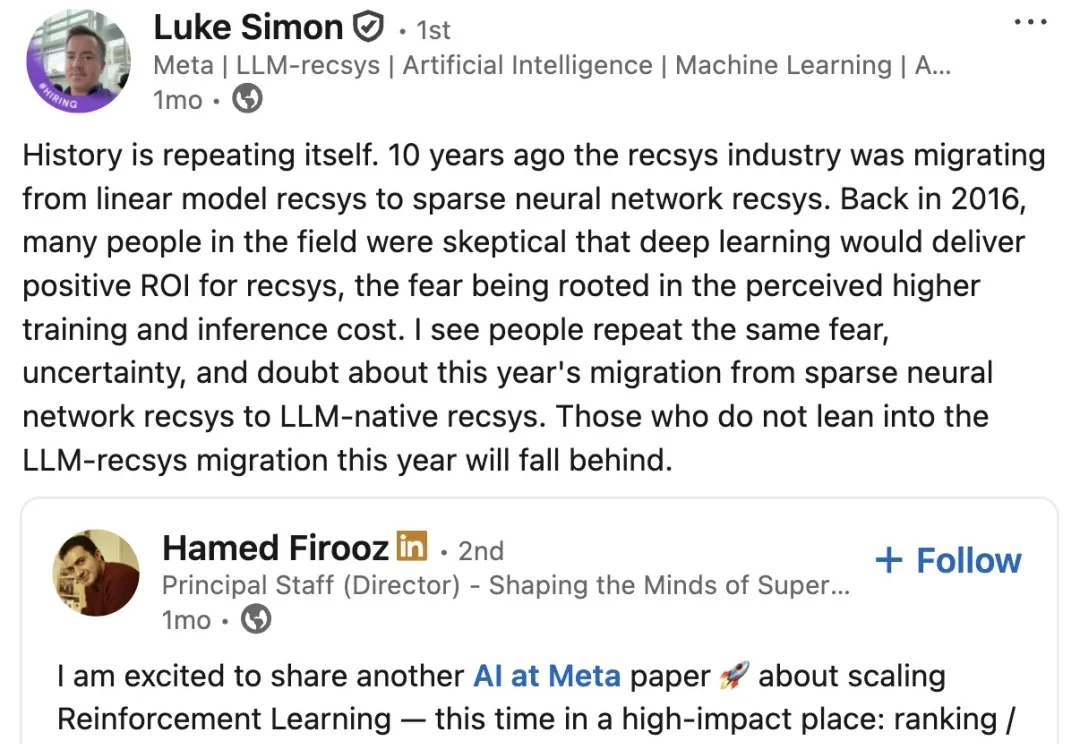
大模型(LLM)的世界知识和推理能力是实现下一代推荐系统,即基于大模型的推荐系统(LLM4Recsys)的重要基石。来自meta ai的研究者们尝试将推理模型引入再排序阶段,推荐系统的最后一环。