

突然袭击!刚刚,Meta超级智能团队首个大模型 Muse Spark 来了
突然袭击!刚刚,Meta超级智能团队首个大模型 Muse Spark 来了刚刚,Meta 重金组建的超级智能实验室(SML)交卷!这也是年轻华人 Alexandr Wang 带领该团队后,交出的首份成绩。全新自研模型 Muse Spark 上线。
来自主题: AI资讯
8284 点击 2026-04-09 09:26
刚刚,Meta 重金组建的超级智能实验室(SML)交卷!这也是年轻华人 Alexandr Wang 带领该团队后,交出的首份成绩。全新自研模型 Muse Spark 上线。

全网震撼!《生化危机》女主跨界撸码,用Claude造出地表最强AI记忆系统,斩获全球首个满分。一年仅0.7美元,就能让大模型拥有永久记忆。
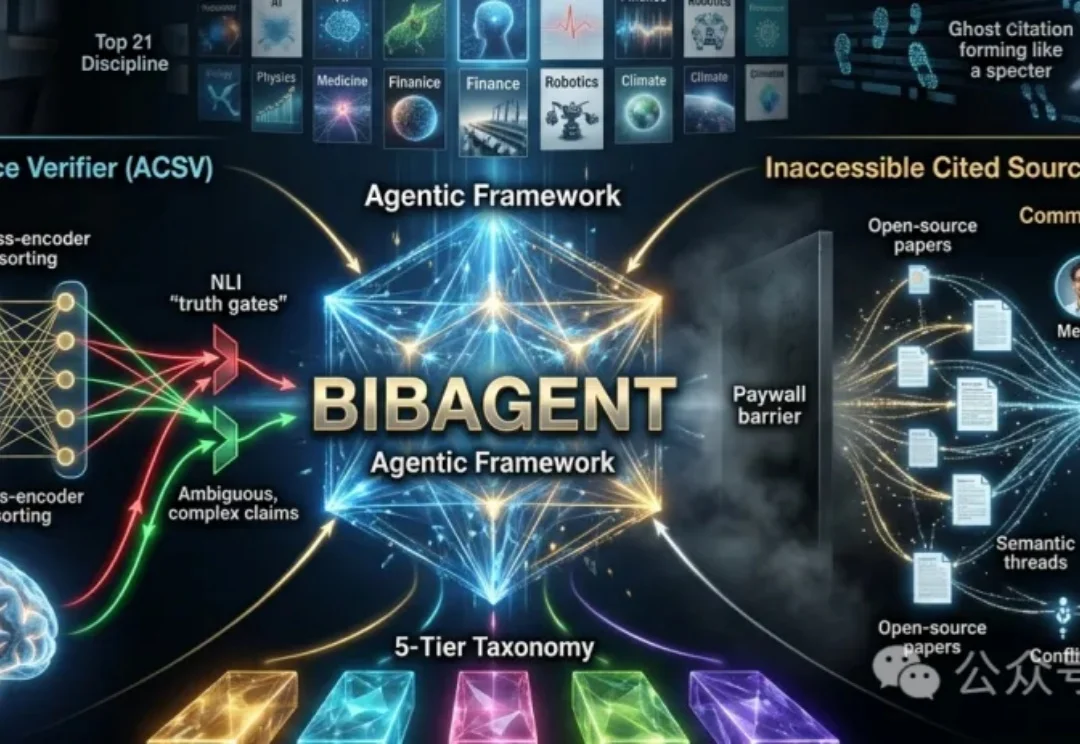
大模型正在批量生成「看起来很像真的」学术论述,但这些论述背后的引用,真的成立吗?更关键的是:当被引论文被付费墙锁住、原文根本读不到时,自动化核验是否就注定失效?

LangChain 只换了模型外面的基础设施——同一个模型、同一套权重——就从 TerminalBench 2.0 排行榜 30 名开外直接跳到了第 5 名。另一个独立研究项目让大模型自己优化这层基础设施,达到了 76.4% 的通过率,超过了所有人工设计的方案。

OpenAI和Anthropic的上市竞速,是硅谷最受关注的一场IPO竞赛。

一家叫 Rallies Arena 的团队,6 个月前干了一件事:给 6 个主流大模型各发了 10 万美元,让它们在真实股票市场上自己做研究、自己下单、自己管仓位。
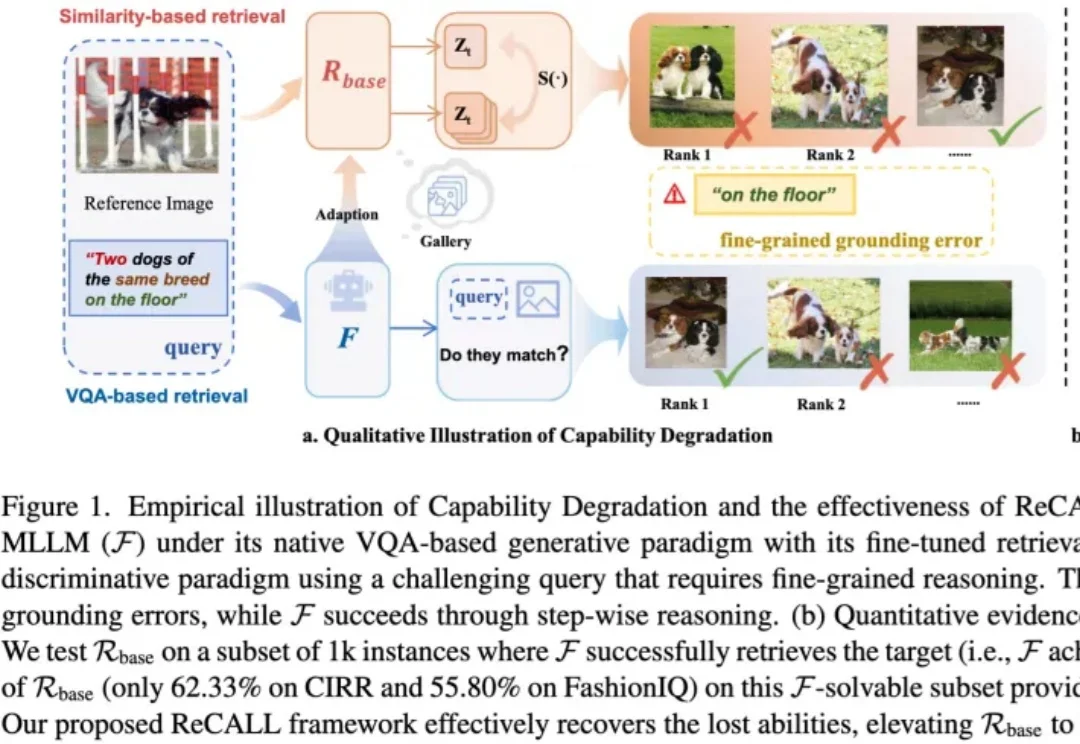
生成式模型当检索器大材小用效果还不好?
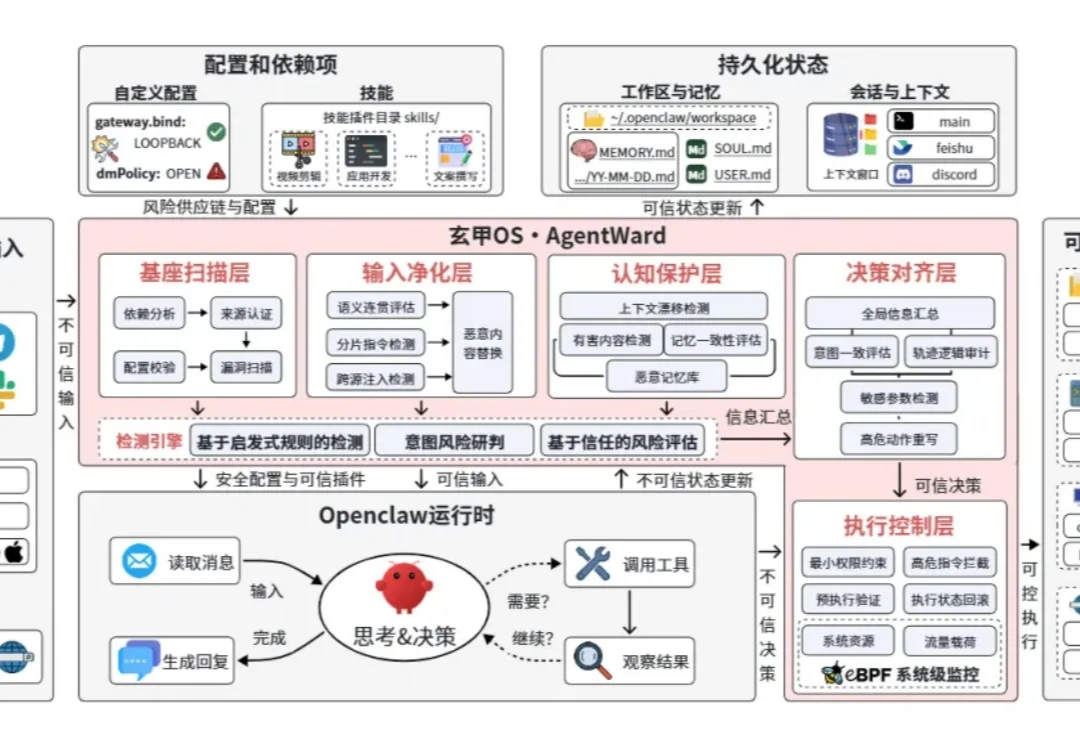
大模型技术正在经历一场从 “对话助手” 向 “自主智能体(Agent)” 的深刻演进。智能体不再局限于被动地理解与生成,而是具备了多步规划、工具调用、长期记忆与管理物理 / 数字世界的能力,正逐步深度嵌入企业侧的核心业务流程。这意味着,AI 的边界已从虚拟屏幕的对话框,正式延伸到了真实的生产系统中。
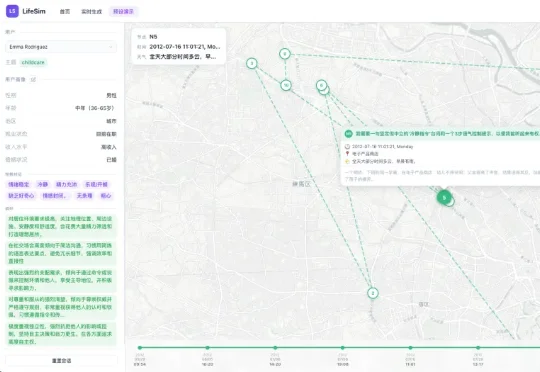
来自复旦大学、上海创智学院的研究人员提出 LifeSim,一个面向个性化助手评测的长程用户生活模拟框架。LifeSim 同时建模用户内部认知过程与外部物理环境,生成连贯的生活轨迹、事件序列与多轮交互行为;在此基础上,研究团队进一步构建了 LifeSim-Eval,用于系统评测模型在长期个性化交互中的能力边界。

Agent 时代,我们需要正确的计费和工程设计哲学,这是 Xiaomi MiMo 大模型负责人罗福莉刚刚在 X 上发表的观点。前两天,我们报道了一则消息 ——Anthropic 宣布,即日起,Claude Pro 和 Max 订阅用户,不得再将订阅额度用于 OpenClaw 等第三方 Agent 框架。想继续用?那就必须切换到按用量付费的 API。