
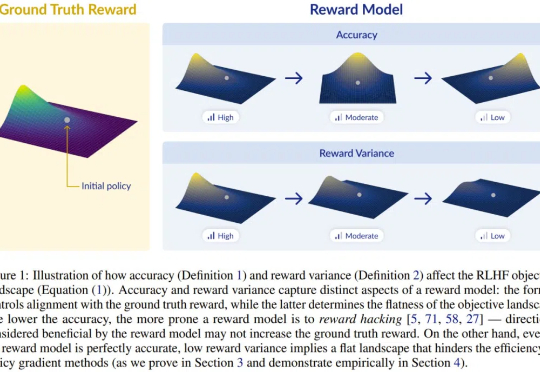
为什么明明很准,奖励模型就是不work?新研究:准确度 is not all you need
为什么明明很准,奖励模型就是不work?新研究:准确度 is not all you need训练狗时不仅要让它知对错,还要给予差异较大的、不同的奖励诱导,设计 RLHF 的奖励模型时也是一样。
来自主题: AI技术研报
10882 点击 2025-03-24 15:33
训练狗时不仅要让它知对错,还要给予差异较大的、不同的奖励诱导,设计 RLHF 的奖励模型时也是一样。

基于内置思维链的思考方法为解决多轮会话中存在的问题提供了研究方向。按照思考方法收集训练数据集,通过有监督学习微调大语言模型;训练一个一致性奖励模型,并将该模型用作奖励函数,以使用强化学习来微调大语言模型。结果大语言模型的推理能力和计划能力,以及执行计划的能力得到了增强。

图像生成模型,也用上思维链(CoT)了!此外,作者还提出了两种专门针对该任务的新型奖励模型——潜力评估奖励模型。(Potential Assessment Reward Model,PARM)及其增强版本PARM++。

1/10训练数据激发高级推理能力!近日,来自清华的研究者提出了PRIME,通过隐式奖励来进行过程强化,提高了语言模型的推理能力,超越了SFT以及蒸馏等方法。

通过过程奖励模型(PRM)在每一步提供反馈,并使用过程优势验证器(PAV)来预测进展,从而优化基础策略,该方法在测试时搜索和在线强化学习中显示出比传统方法更高的准确性和计算效率,显著提升了解决复杂问题的能力。

传统的训练方法通常依赖于大量人工标注的数据和外部奖励模型,这些方法往往受到成本、质量控制和泛化能力的限制。因此,如何减少对人工标注的依赖,并提高模型在复杂推理任务中的表现,成为了当前的主要挑战之一。

Meta、UC伯克利、NYU共同提出元奖励语言模型,给「超级对齐」指条明路:让AI自己当裁判,自我改进对齐,效果秒杀自我奖励模型。

为了将大型语言模型(LLM)与人类的价值和意图对齐,学习人类反馈至关重要,这能确保它们是有用的、诚实的和无害的。在对齐 LLM 方面,一种有效的方法是根据人类反馈的强化学习(RLHF)。尽管经典 RLHF 方法的结果很出色,但其多阶段的过程依然带来了一些优化难题,其中涉及到训练一个奖励模型,然后优化一个策略模型来最大化该奖励。
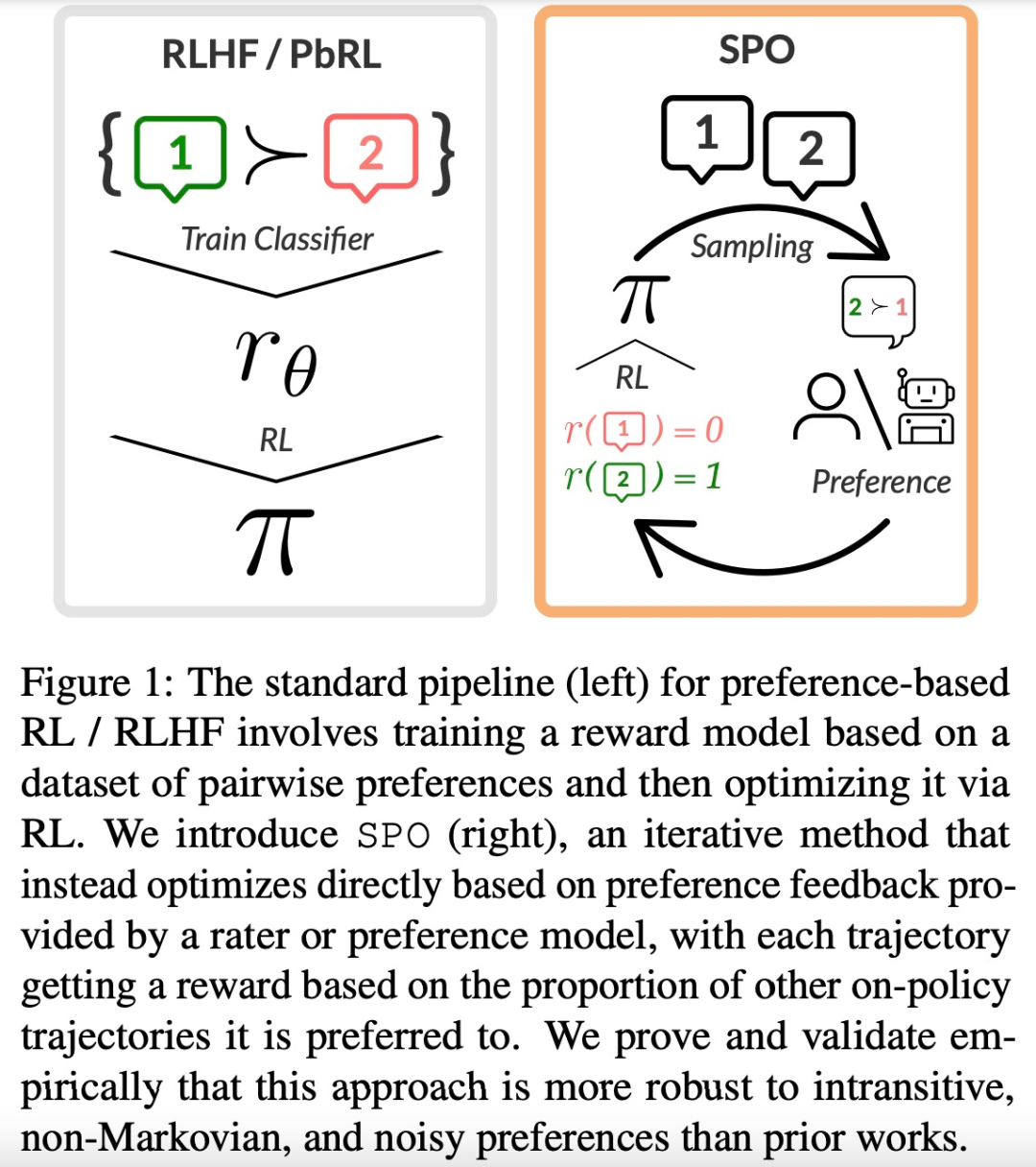
大型语言模型(LLM)的成功离不开「基于人类反馈的强化学习(RLHF)」。RLHF 可以大致可以分为两个阶段,首先,给定一对偏好和不偏好的行为,训练一个奖励模型,通过分类目标为前者分配更高的分数。
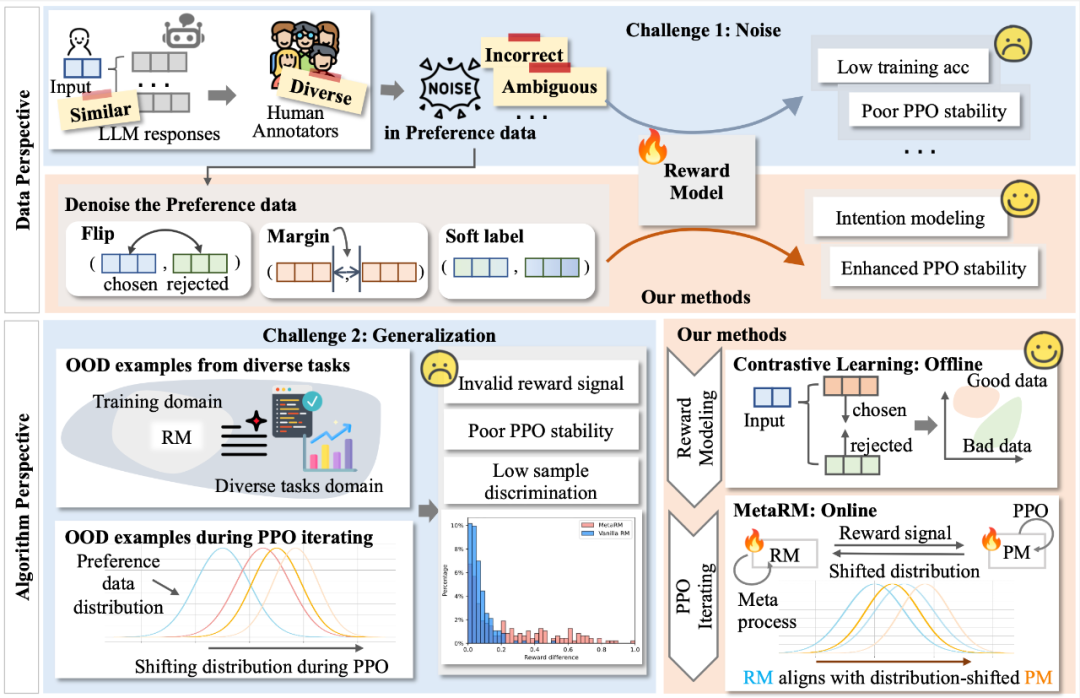
复旦团队进一步挖掘 RLHF 的潜力,重点关注奖励模型(Reward Model)在面对实际应用挑战时的表现和优化途径。