
HuggingFace上的热门开源模型,一半都来自中国了
HuggingFace上的热门开源模型,一半都来自中国了HuggingFace热门榜单几乎被中国模型“承包”了!
来自主题: AI资讯
9651 点击 2025-03-12 10:27
 搜索
搜索
HuggingFace热门榜单几乎被中国模型“承包”了!

2025年3月11日,AI智能体领域迎来惊天反转:Manus团队宣布与阿里通义千问达成战略合作,双方将基于国产开源模型重构Manus全部功能。这一决策直接回应了3月5日产品发布后遭遇的“破解危机”——因过度依赖Claude Sonnet模型,Manus被质疑为“工具集成商”,甚至开源社区迅速推出复刻版OpenManus。

AI21Labs 近日发布了其最新的 Jamba1.6系列大型语言模型,这款模型被称为当前市场上最强大、最高效的长文本处理模型。与传统的 Transformer 模型相比,Jamba 模型在处理长上下文时展现出了更高的速度和质量,其推理速度比同类模型快了2.5倍,标志着一种新的技术突破。
仅用32B,就击败o1-mini追平671B满血版DeepSeek-R1!阿里深夜重磅发布的QwQ-32B,再次让全球开发者陷入狂欢:消费级显卡就能跑,还一下子干到推理模型天花板!

今夜,Manus发布之后,随之而来赶到战场的,是阿里。
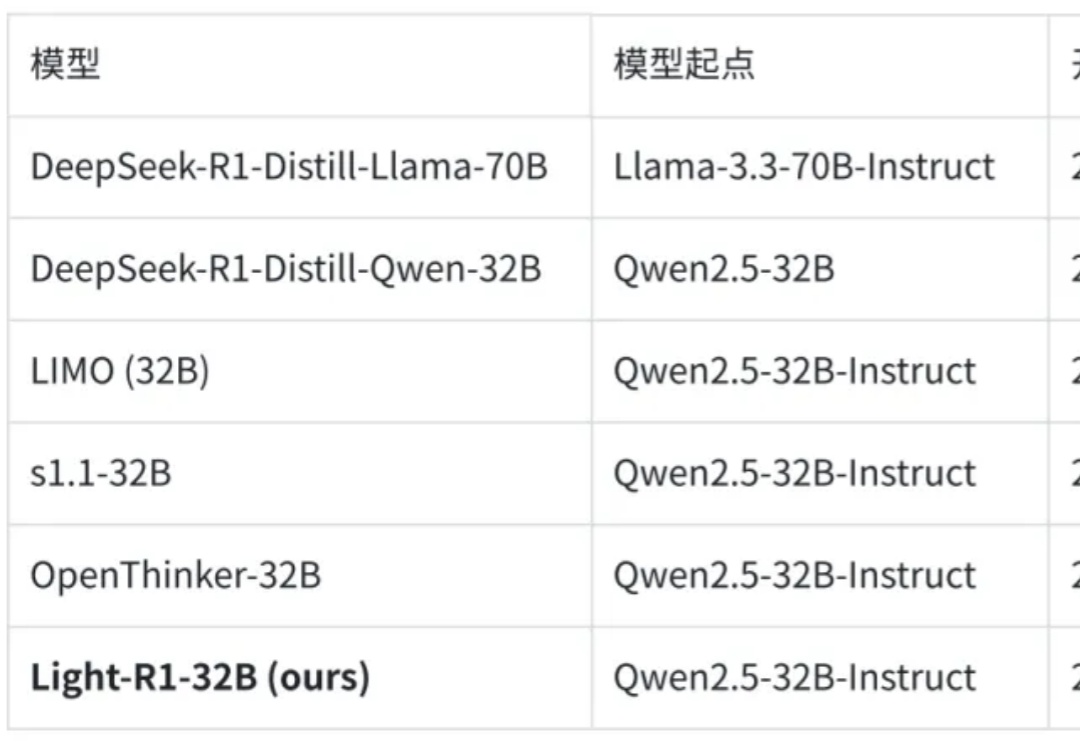
2025 年 3 月 4 日,360 智脑开源了 Light-R1-32B 模型,以及全部训练数据、代码。仅需 12 台 H800 上 6 小时即可训练完成,从没有长思维链的 Qwen2.5-32B-Instruct 出发,仅使用 7 万条数学数据训练,得到 Light-R1-32B
开源模型,还是得看杭州。
美国AI云服务商Together AI宣布完成3.05亿美元B轮融资,估值高达33亿美元!该公司押注开源模型,提供包括DeepSeek-R1在内的200多个模型API服务,并出租GPU算力,年收入已超1亿美元。
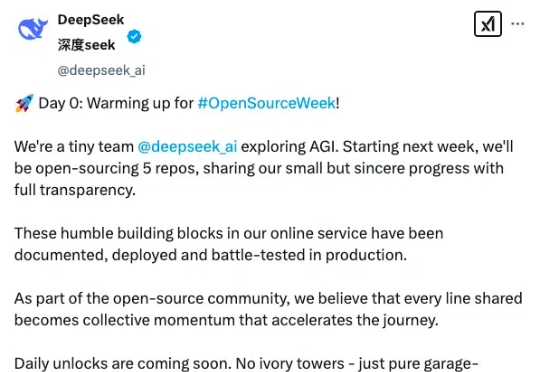
就在刚刚,DeepSeek 在 X 平台发文宣布,将在下周(OpenSourceWeek 开源周)连续五天开源 5 个项目的代码库。

刚刚,阶跃星辰联合吉利汽车集团,开源了两款多模态大模型!新模型共2款:全球范围内参数量最大的开源视频生成模型Step-Video-T2V行业内首款产品级开源语音交互大模型Step-Audio多模态卷王开始开源多模态模型,其中Step-Video-T2V采用的还是最为开放宽松的MIT开源协议,可任意编辑和商业应用。