

让模型部署像调用API一样简单!1小时轻松完成超100个微调模型部署的神器来了,按量计费每月立省10万
让模型部署像调用API一样简单!1小时轻松完成超100个微调模型部署的神器来了,按量计费每月立省10万大家可能看到过很多类似的结论:针对特定任务,对开源模型进行 LoRA 微调可以干翻 GPT-4 这类闭源模型。
来自主题: AI资讯
9052 点击 2025-01-09 09:37
大家可能看到过很多类似的结论:针对特定任务,对开源模型进行 LoRA 微调可以干翻 GPT-4 这类闭源模型。
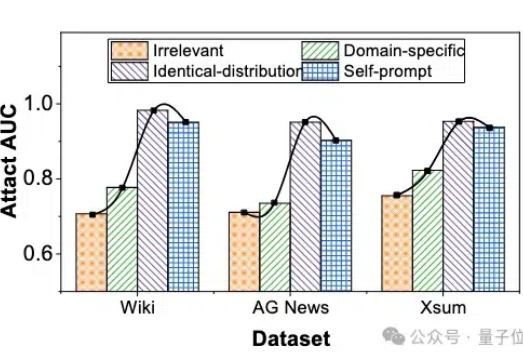
微调大模型的数据隐私可能泄露? 最近华科和清华的研究团队联合提出了一种成员推理攻击方法,能够有效地利用大模型强大的生成能力,通过自校正机制来检测给定文本是否属于大模型的微调数据集。
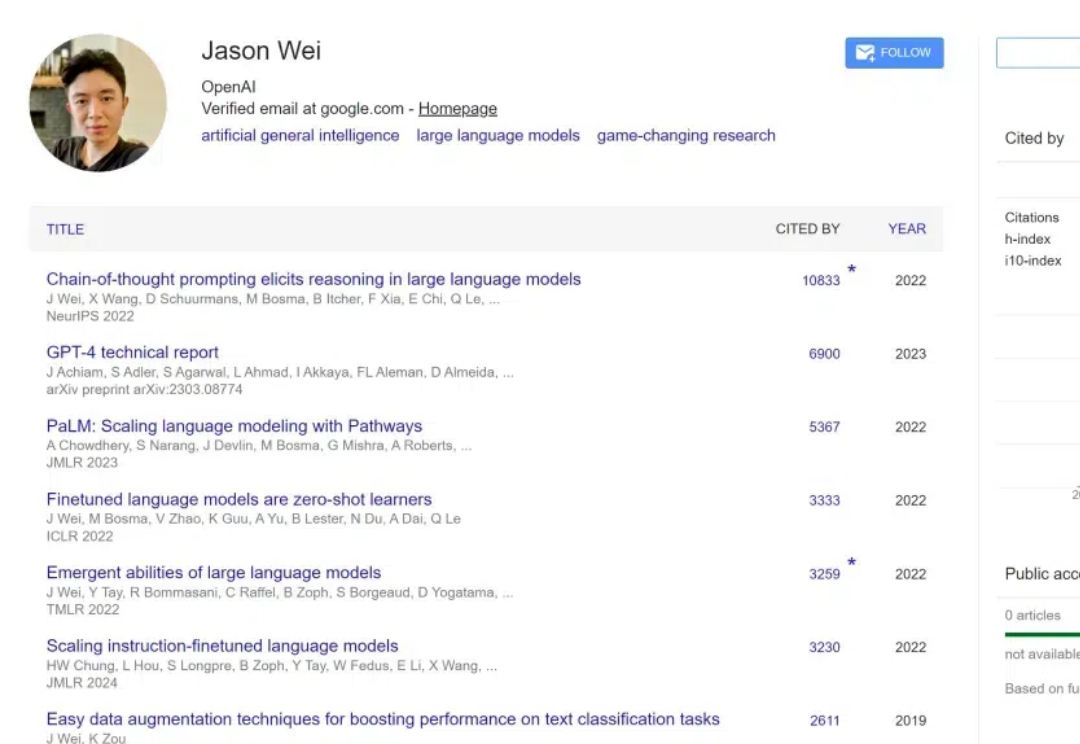
2023 年初,Jason Wei 加入了 OpenAI,参与了 ChatGPT 的构建以及 o1 等重大项目。他的工作使思维链提示、指令微调和涌现现象等技术和概念变得广为人知。
只需几十个样本即可训练专家模型,强化微调RLF能掀起强化学习热潮吗?具体技术实现尚不清楚,AI2此前开源的RLVR或许在技术思路上存在相似之处。
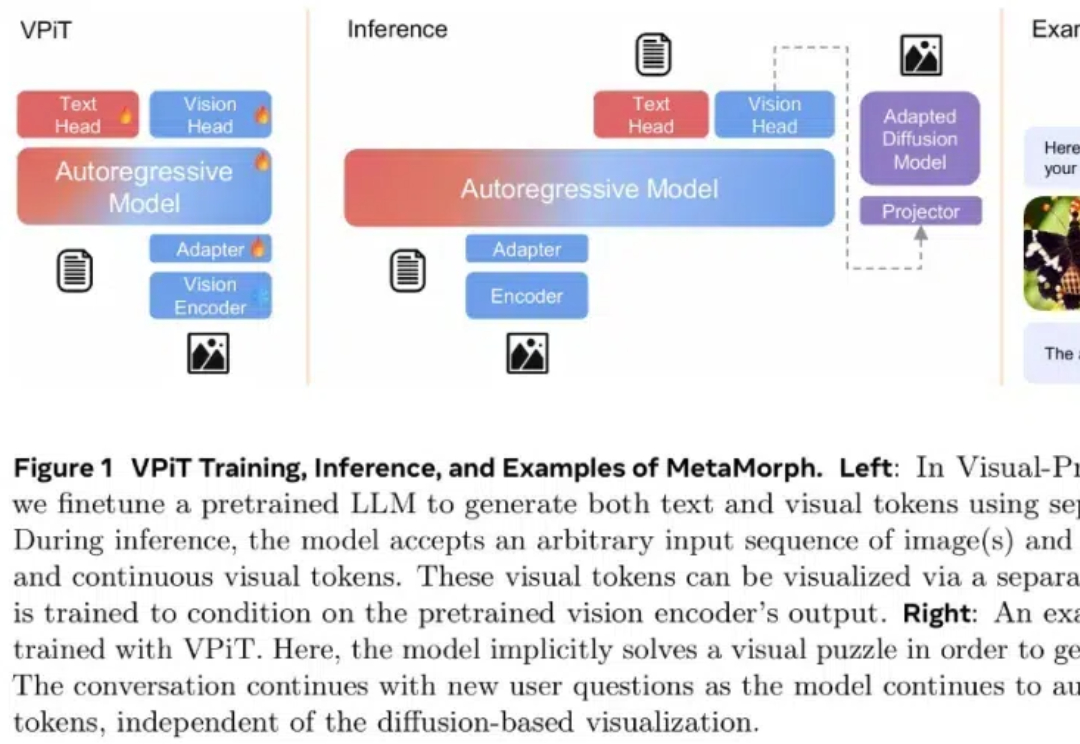
如今,多模态大模型(MLLM)已经在视觉理解领域取得了长足进步,其中视觉指令调整方法已被广泛应用。该方法是具有数据和计算效率方面的优势,其有效性表明大语言模型(LLM)拥有了大量固有的视觉知识,使得它们能够在指令调整过程中有效地学习和发展视觉理解。
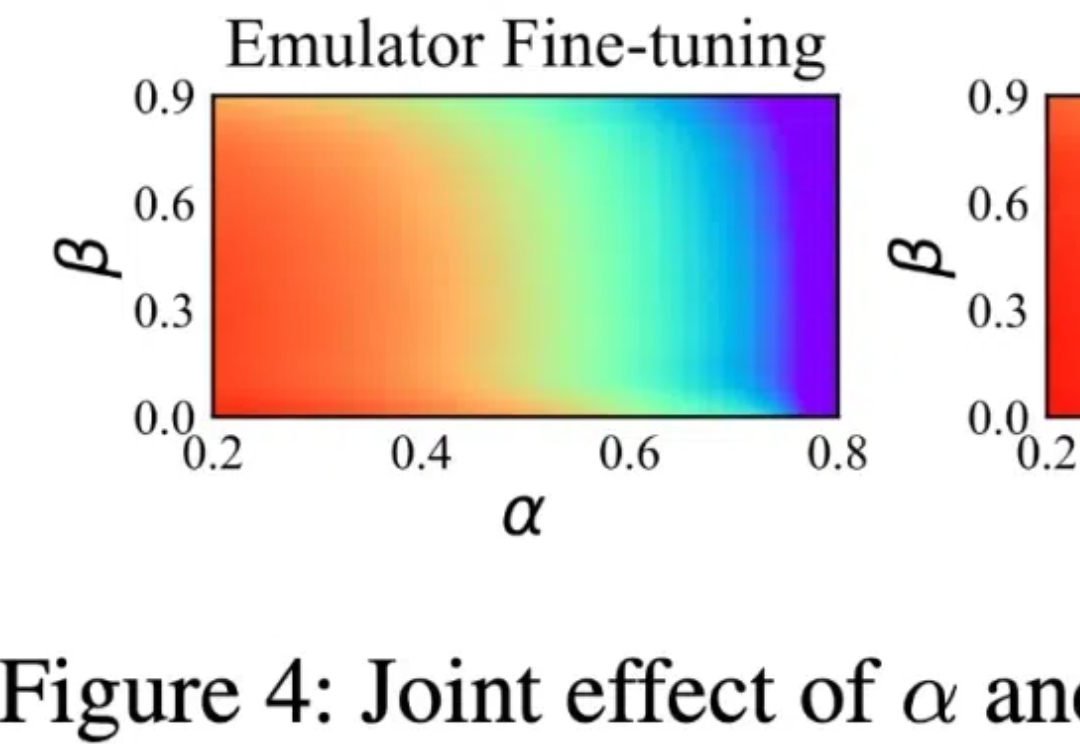
要让大模型适应各不一样的下游任务,微调必不可少。常规的中心化微调过程需要模型和数据存在于同一位置 —— 要么需要数据所有者上传数据(这会威胁到数据所有者的数据隐私),要么模型所有者需要共享模型权重(这又可能泄露自己花费大量资源训练的模型)。
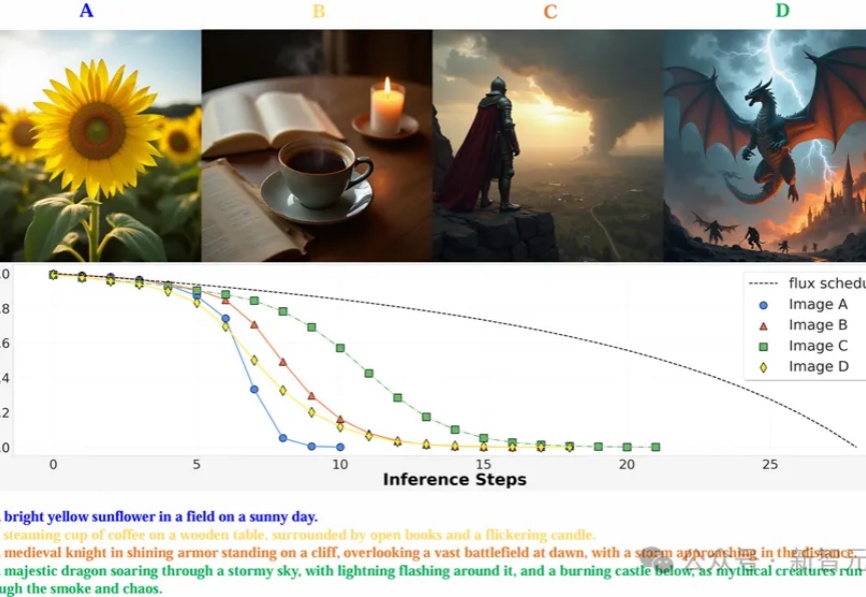
MAPLE实验室提出通过强化学习优化图像生成模型的去噪过程,使其能以更少的步骤生成高质量图像,在多个图像生成模型上实现了减少推理步骤,还能提高图像质量。
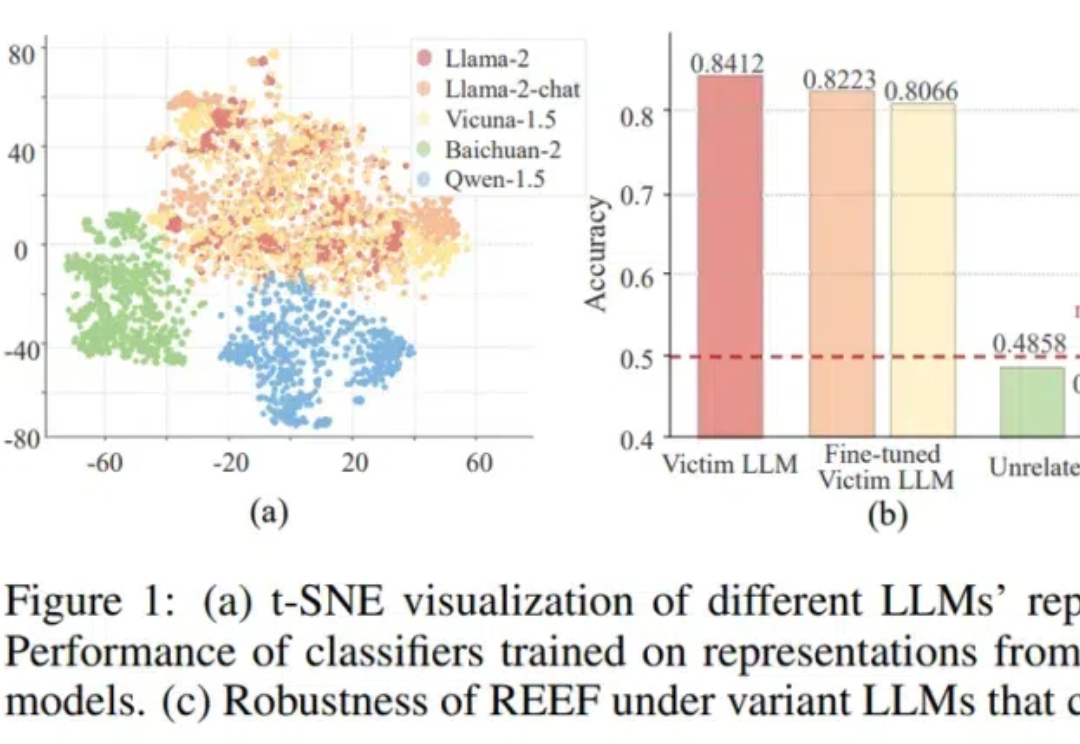
大模型“套壳”事件防不胜防,有没有方法可以检测套壳行为呢? 来自上海AI实验室、中科院、人大和上交大的学者们,提出了一种大模型的“指纹识别”方法——REEF(Representation Encoding Fingerprints)。
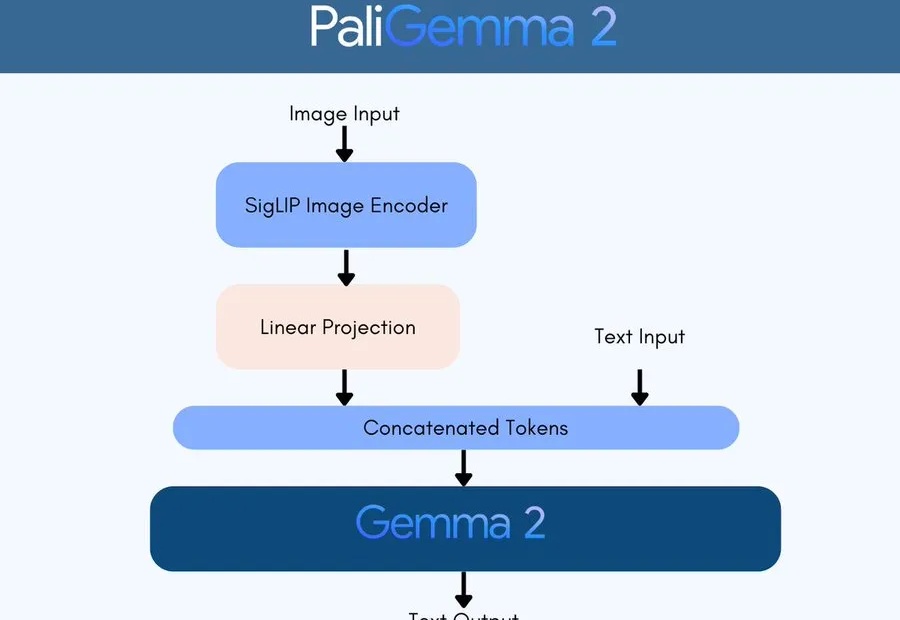
PaliGemma 2在多个任务上取得了业界领先的成绩,包括图像描述、乐谱识别和医学图像报告生成;并且提供了不同尺寸和分辨率的版本,用户可以根据不同的任务需求进行微调,以获得更好的性能。
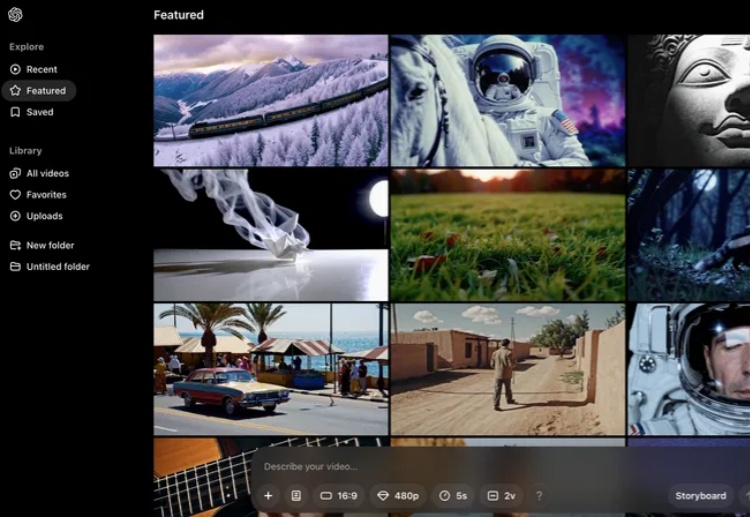
OpenAI发布会直播第3天,继第1天完全版o1和200美元月费ChatGPT Pro会员,以及第2天的强化微调工具后,OpenAI终于填上9个月前的期货大坑,正式发布了观众敲碗已久的全新视频生成模型——Sora Turbo。