
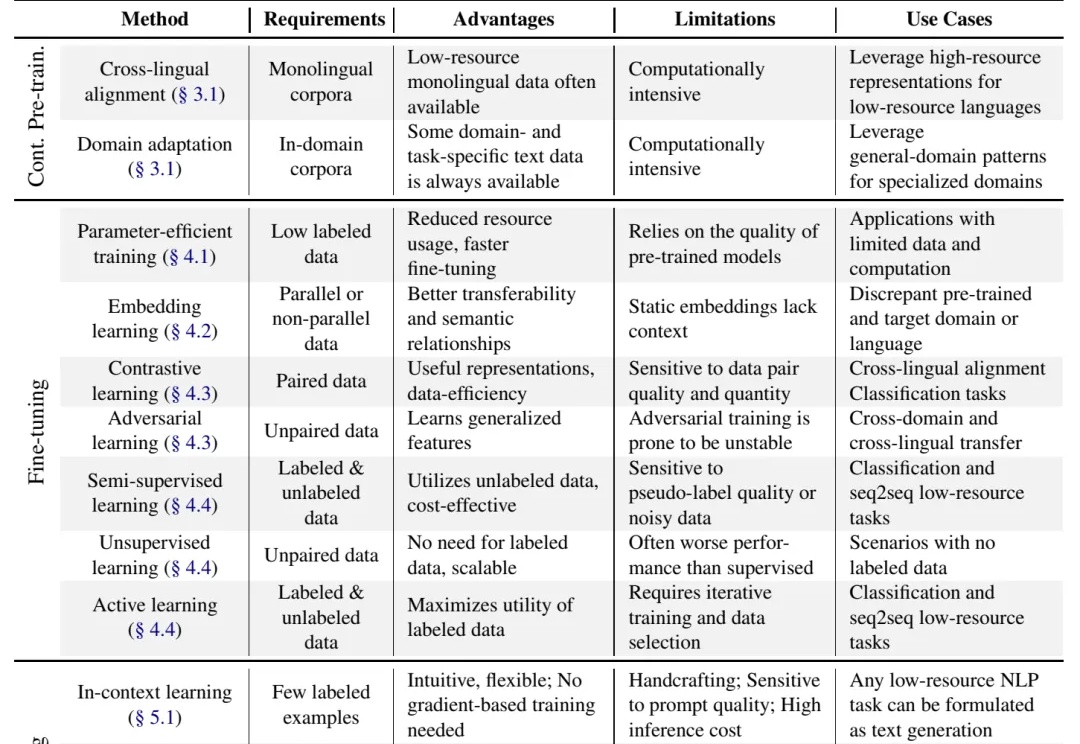
缺钱缺数据时的大模型微调方法汇总
缺钱缺数据时的大模型微调方法汇总别说什么“没数据就去标注啊,没钱标注就别做大模型啊”这种风凉话,有些人数据不足也能做大模型,是因为有野心,就能想出来稀缺数据场景下的大模型解决方案,或者整理出本文将要介绍的 "Practical Guide to Fine-tuning with Limited Data" 这样的综述。
来自主题: AI资讯
11096 点击 2024-12-09 09:30
别说什么“没数据就去标注啊,没钱标注就别做大模型啊”这种风凉话,有些人数据不足也能做大模型,是因为有野心,就能想出来稀缺数据场景下的大模型解决方案,或者整理出本文将要介绍的 "Practical Guide to Fine-tuning with Limited Data" 这样的综述。

2024 年 12 月 6 号加州时间上午 11 点,OpenAI 发布了新的 Reinforcement Finetuning 方法,用于构造专家模型。对于特定领域的决策问题,比如医疗诊断、罕见病诊断等等,只需要上传几十到几千条训练案例,就可以通过微调来找到最有的决策。
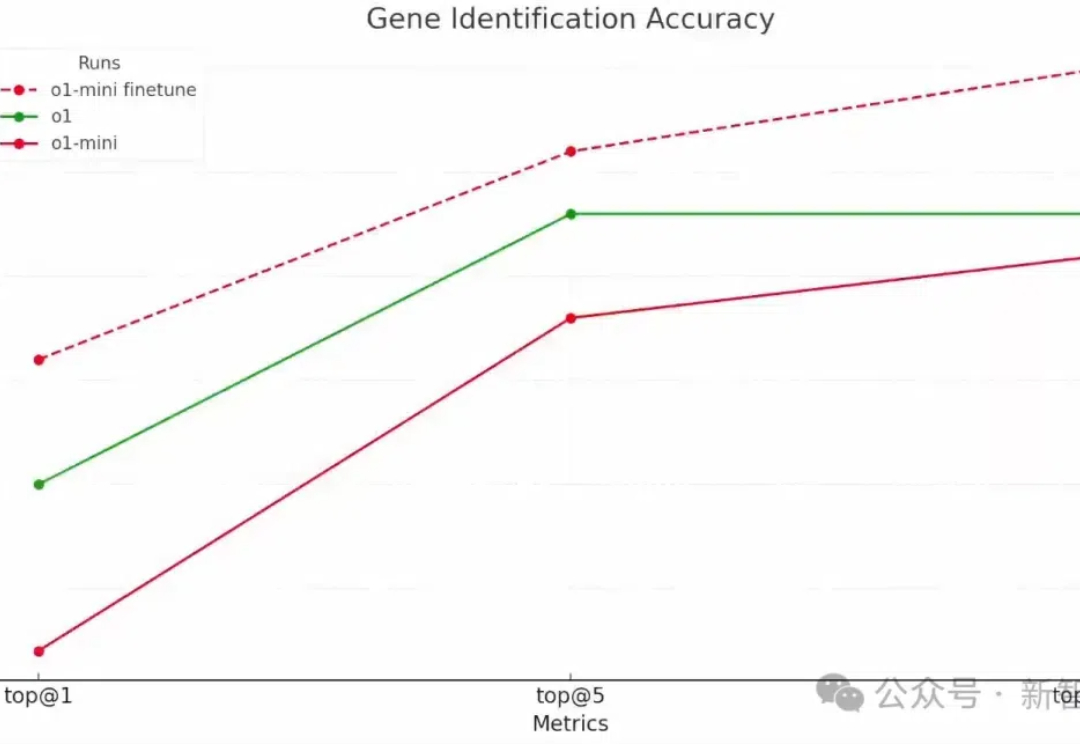
OpenAI第二天的直播,揭示了强化微调的强大威力:强化微调后的o1-mini,竟然全面超越了地表最强基础模型o1。而被奥特曼称为「2024年我最大的惊喜」的技术,技术路线竟和来自字节跳动之前公开发表的强化微调研究思路相同。

强化微调可以轻松创建具备强大推理能力的专家模型。

就在刚刚,OpenAI 年底的 AI 春晚迎来了第二弹。 如果说昨天的 ChatGPT Pro 订阅计划震撼了普通用户的钱包,那么今天推出的产品则转向了不同的目标客户群体——企业机构和开发者。

OpenAI“双12”直播第二天,依旧简短精悍,主题:新功能强化微调(Reinforcement Fine-Tuning),使用极少训练数据即在特定领域轻松地创建专家模型。少到什么程度呢?最低几十个例子就可以。
最近,一支来自UCSD和清华的研究团队提出了一种全新的微调方法。经过这种微调后,一个仅80亿参数的小模型,在科学问题上也能和GPT-4o一较高下!或许,单纯地卷AI计算能力并不是唯一的出路。
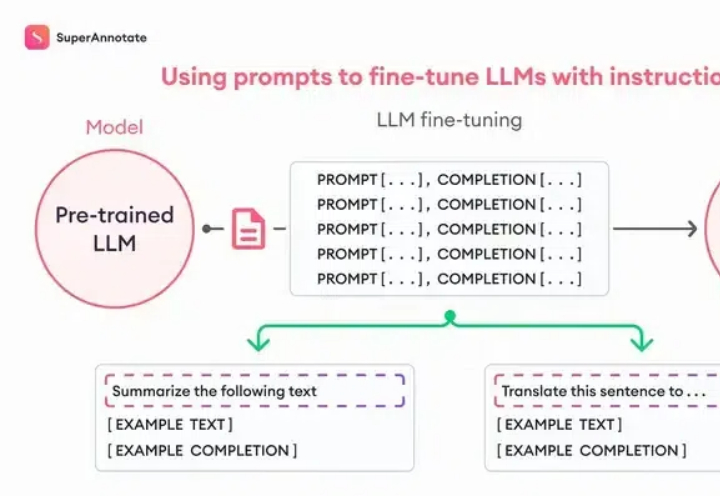
Fine-tuning理论上很复杂,但是OpenAI把这个功能完善到任何一个人看了就能做出来的程度。我们先从原理入手,你看这张图,左边是Pre-trained LLM (预训练大模型模型),也就是像ChatGPT这样的模型;右边是Fine-tuned LLM (微调过的语言大模型),中间就是进行微调的过程,它需要我们提供一些「ChatGPT提供不了但是我们需要的东西」。
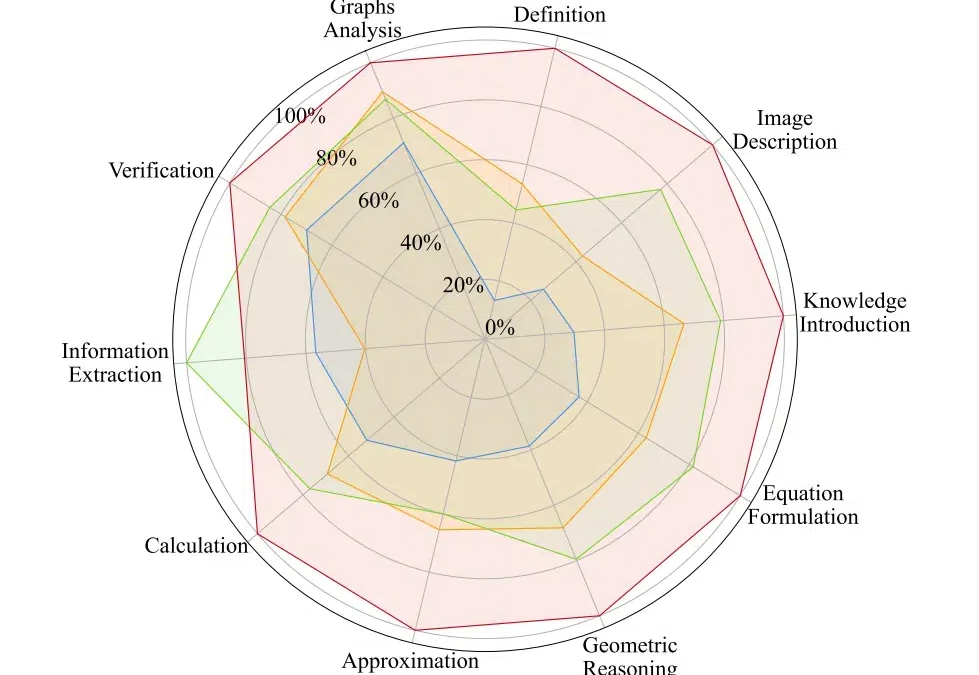
AtomThink 是一个包括 CoT 注释引擎、原子步骤指令微调、政策搜索推理的全流程框架,旨在通过将 “慢思考 “能力融入多模态大语言模型来解决高阶数学推理问题。量化结果显示其在两个基准数学测试中取得了大幅的性能增长,并能够轻易迁移至不同的多模态大模型当中。
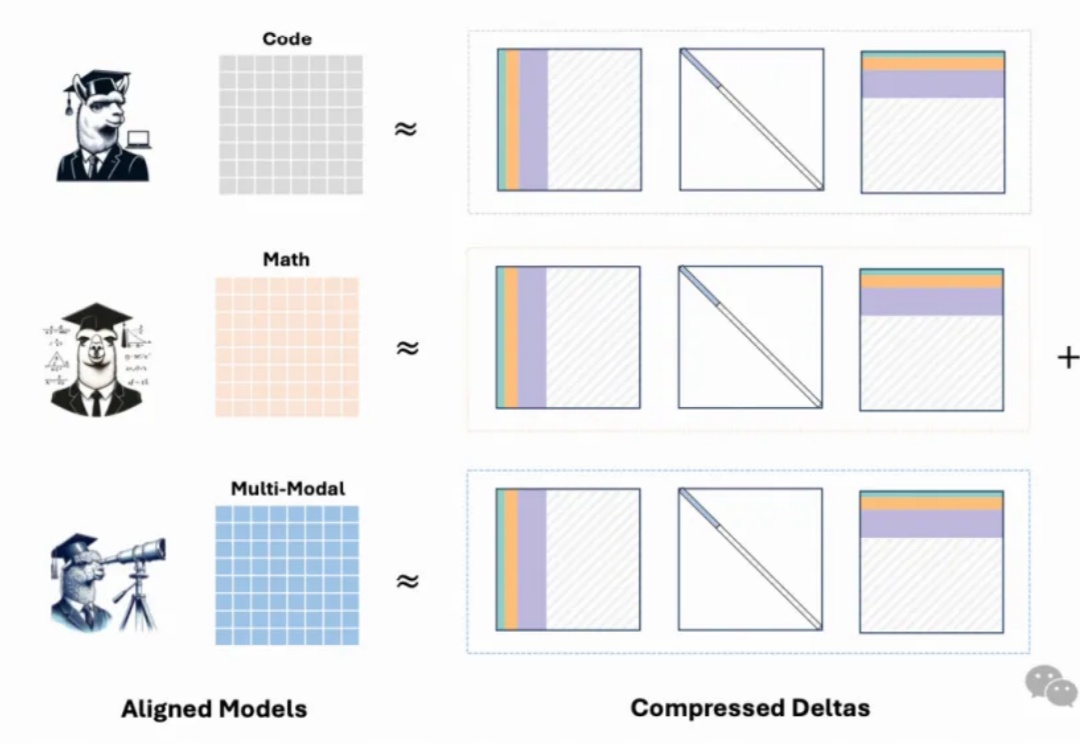
最新模型增量压缩技术,一个80G的A100 GPU能够轻松加载多达50个7B模型,节省显存约8倍,同时模型性能几乎与压缩前的微调模型相当。