
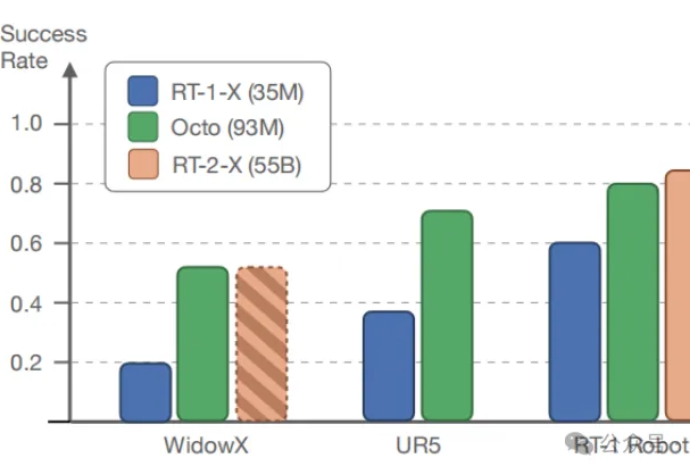
具身大模型学习——OCTO
具身大模型学习——OCTO在多样化的机器人数据集上预训练的大型策略有潜力改变机器人学习:与从头开始训练新策略相比,这种通用型机器人策略可以通过少量的领域内数据进行微调,同时具备广泛的泛化能力。
来自主题: AI资讯
9201 点击 2024-11-19 21:10
在多样化的机器人数据集上预训练的大型策略有潜力改变机器人学习:与从头开始训练新策略相比,这种通用型机器人策略可以通过少量的领域内数据进行微调,同时具备广泛的泛化能力。

自我纠错(Self Correction)能力,传统上被视为人类特有的特征,正越来越多地在人工智能领域,尤其是大型语言模型(LLMs)中得到广泛应用,最近爆火的OpenAI o1模型[1]和Reflection 70B模型[2]都采取了自我纠正的方法。

文本到图像的生成模型让创作更加灵活,用户可以用自然语言引导生成图像。

连续学习(CL)旨在增强机器学习模型的能力,使其能够不断从新数据中学习,而无需进行所有旧数据的重新训练。连续学习的主要挑战是灾难性遗忘:当任务按顺序训练时,新的任务训练会严重干扰之前学习的任务的性能,因为不受约束的微调会使参数远离旧任务的最优状态。

小米大模型第二代来了! 相比第一代,训练数据规模更大、品质更高,训练策略与微调机制上也进行了深入打磨。

一个5月份完成训练的大模型,无法对《黑神话·悟空》游戏内容相关问题给出准确回答。

大型语言模型(LLMs)虽然在适应新任务方面取得了长足进步,但它们仍面临着巨大的计算资源消耗,尤其在复杂领域的表现往往不尽如人意。

大型语言模型 (LLM) 在各种自然语言处理和推理任务中表现出卓越的能力,某些应用场景甚至超越了人类的表现。然而,这类模型在最基础的算术问题的表现上却不尽如人意。

Robin3D通过鲁棒指令数据生成引擎(RIG)生成的大规模数据进行训练,以提高模型在3D场景理解中的鲁棒性和泛化能力,在多个3D多模态学习基准测试中取得了优异的性能,超越了以往的方法,且无需针对特定任务的微调。

随着 AI 模型的参数量越来越大,对算力的需求也水涨船高。