
「世界开源新王」跌落神坛?重测跑分暴跌实锤造假,2人团队光速「滑跪」
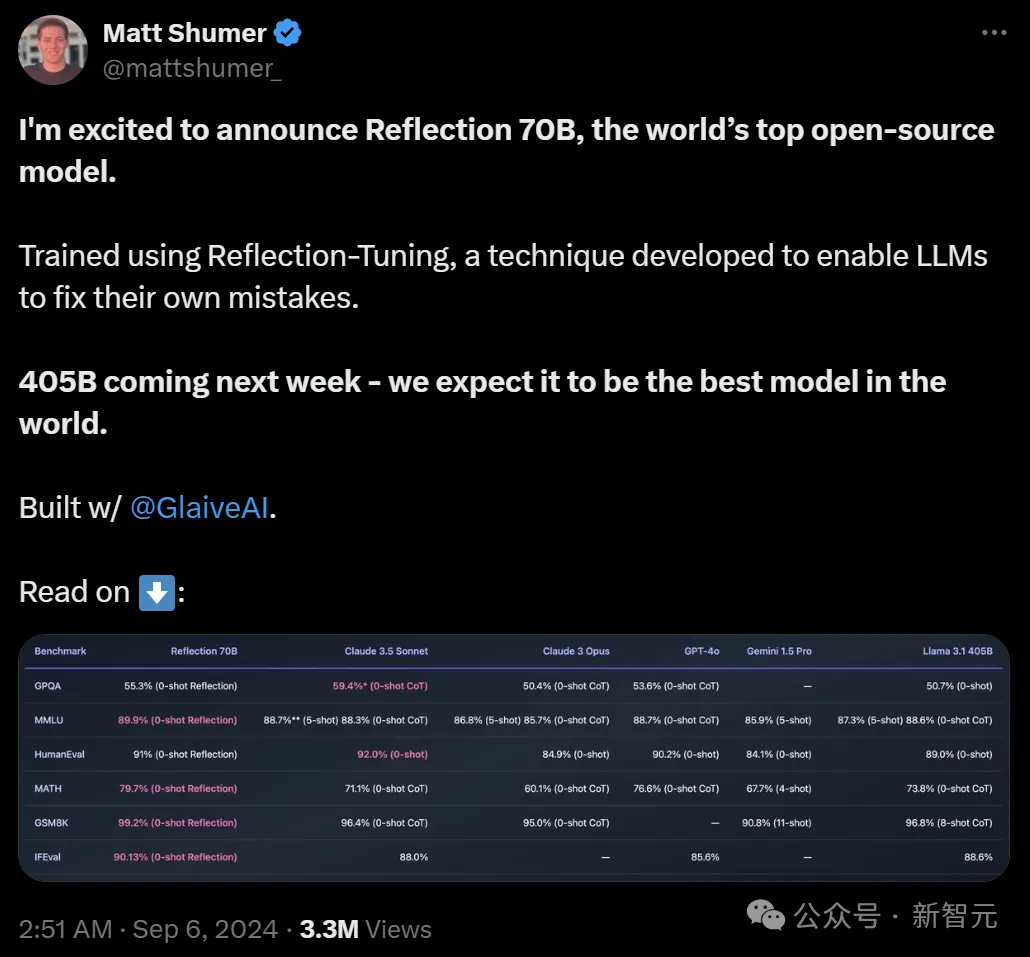
「世界开源新王」跌落神坛?重测跑分暴跌实锤造假,2人团队光速「滑跪」「开源新王」Reflection 70B,才发布一个月就跌落神坛了? 9月5日,Hyperwrite AI联创兼CEO Matt Shumer在X上扔出一则爆炸性消息—— 用Meta的开源Llama 3.1-70B,团队微调出了Reflection 70B。
来自主题: AI资讯
4921 点击 2024-10-07 13:57
「开源新王」Reflection 70B,才发布一个月就跌落神坛了? 9月5日,Hyperwrite AI联创兼CEO Matt Shumer在X上扔出一则爆炸性消息—— 用Meta的开源Llama 3.1-70B,团队微调出了Reflection 70B。

十一假期第1天, OpenAI一年一度的开发者大会又来了惹!今年的开发者大会分成三部分分别在美国、英国、新加坡三个地点举办,刚刚结束的是第一场。
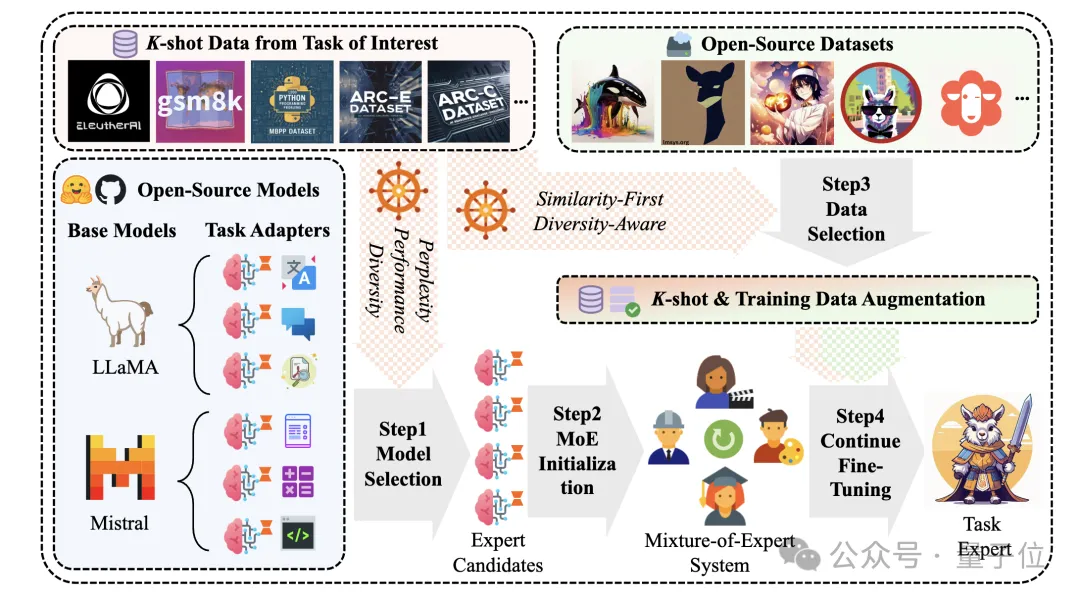
告别传统指令微调,大模型特定任务性能提升有新方法了。 一种新型开源增强知识框架,可以从公开数据中自动提取相关知识,针对性提升任务性能。 与基线和SOTA方法对比,本文方法在各项任务上均取得了更好的性能。

指令调优(Instruction tuning)是一种优化技术,通过对模型的输入进行微调,以使其更好地适应特定任务。先前的研究表明,指令调优样本效率是很高效的,只需要大约 1000 个指令-响应对或精心制作的提示和少量指令-响应示例即可。

在当今大模型技术日新月异的背景下,数据已跃升为构建企业大模型知识库、优化训练与微调,乃至驱动模型创新不可或缺的核心要素。

近期,浙大和 Salesforce 学者进一步发现:语言模型或许帮助有限,但是图像模型能够有效地迁移到时序预测领域。

比LoRA更高效的模型微调方法来了——
微调的所有门道,都在这里了。

OpenAI推出GPT-4o模型微调功能。

一觉醒来,OpenAI又上新功能了: