

LLM数学性能暴涨168%,微软14人团队力作!合成数据2.0秘诀曝光,智能体生成教学
LLM数学性能暴涨168%,微软14人团队力作!合成数据2.0秘诀曝光,智能体生成教学合成数据2.0秘诀曝光了!来自微软的研究人员们提出了智能体框架AgentInstruct,能够自动创建大量、多样化的合成数据。经过合成数据微调后的模型Orca-3,在多项基准上刷新了SOTA。
来自主题: AI技术研报
10524 点击 2024-08-19 14:52
合成数据2.0秘诀曝光了!来自微软的研究人员们提出了智能体框架AgentInstruct,能够自动创建大量、多样化的合成数据。经过合成数据微调后的模型Orca-3,在多项基准上刷新了SOTA。

席卷开源界的AI生图王者诞生了!发布半个月,Flux已经成为替代Midjourney的宠儿。各路开发者们开始用自己的照片微调LoRA,一人拿捏多种风格。

互相检查,让小模型也能解决大问题。

发布40天后,最强开源模型Llama 3.1 405B等来了微调版本的发布。但不是来自Meta,而是一个专注于开放模型的神秘初创Nous Research。

智谱AI把自研打造的大模型给开源了。
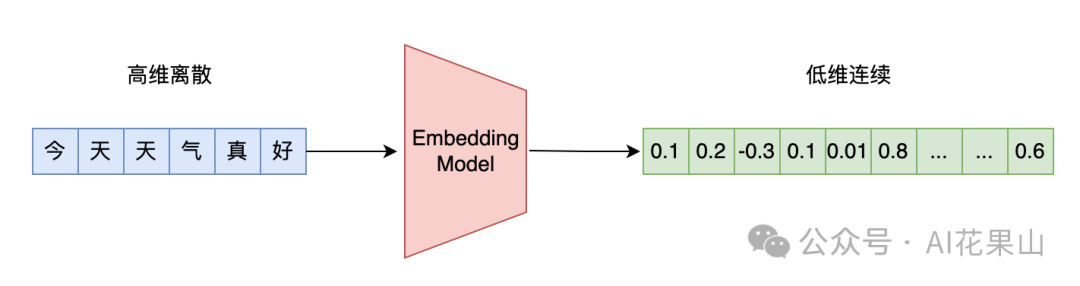
在本篇文章中,笔者将讨论以下几个问题: • 向量模型在 RAG 系统中的作用 有哪些性能不错的向量模型(从 RAG 角度) 不同向量模型的评测基准 MTEB 业务中选择向量模型有哪些考量 如何 Finetune 向量模型

为了解决这个问题,一些研究尝试通过强大的 Teacher Model 生成训练数据,来增强 Student Model 在特定任务上的性能。然而,这种方法在成本、可扩展性和法律合规性方面仍面临诸多挑战。在无法持续获得高质量人类监督信号的情况下,如何持续迭代模型的能力,成为了亟待解决的问题。

UrbanGPT是一种创新的时空大型语言模型,它通过结合时空依赖编码器和指令微调技术,展现出在多种城市任务中卓越的泛化能力和预测精度。这项技术突破了传统模型对大量标记数据的依赖,即使在数据稀缺的情况下也能提供准确的预测,为城市管理和规划提供了强大的支持。

适逢Llama 3.1模型刚刚发布,英伟达就发表了一篇技术博客,手把手教你如何好好利用这个强大的开源模型,为领域模型或RAG系统的微调生成合成数据。

华盛顿大学和Allen AI最近发表的论文提出了一种新颖有趣的数据合成方法。他们发现,充分利用LLM的自回归特性,可以引导模型自动生成高质量的指令微调数据。