

GPT-4o mini实力霸榜,限时2个月微调不花钱!每天200万训练token免费薅
GPT-4o mini实力霸榜,限时2个月微调不花钱!每天200万训练token免费薅Llama 3.1 405B巨兽开源的同时,OpenAI又抢了一波风头。从现在起,每天200万训练token免费微调模型,截止到9月23日。
来自主题: AI资讯
5437 点击 2024-07-26 17:20
Llama 3.1 405B巨兽开源的同时,OpenAI又抢了一波风头。从现在起,每天200万训练token免费微调模型,截止到9月23日。
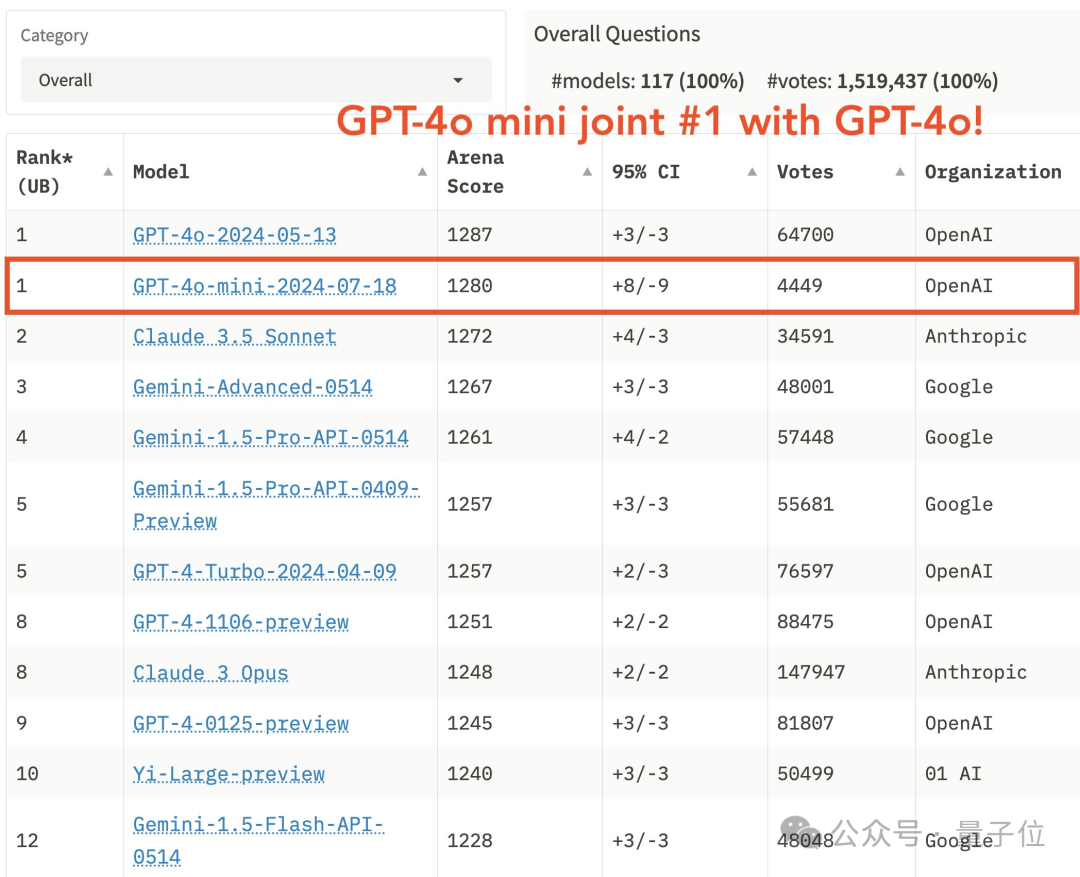
刚刚,GPT-4o mini版迎来“高光时刻”——

低秩适应(Low-Rank Adaptation,LoRA)通过可插拔的低秩矩阵更新密集神经网络层,是当前参数高效微调范式中表现最佳的方法之一。此外,它在跨任务泛化和隐私保护方面具有显著优势。

Scaling Laws当道,但随着大模型应用的发展,基础模型不断扩大的参数也成了令开发者们头疼的问题。

只需激活60%的参数,就能实现与全激活稠密模型相当的性能。

无需训练或微调,在提示词指定的新场景中克隆参考视频的运动,无论是全局的相机运动还是局部的肢体运动都可以一键搞定。

自从大型 Transformer 模型逐渐成为各个领域的统一架构,微调就成为了将预训练大模型应用到下游任务的重要手段

全球首个芯片设计开源大模型SemiKong正式发布,基于Llama 3微调而来,性能超越通用大模型。未来5年,SemiKong或将重塑价值5000亿美元的半导体行业。

来自佐治亚理工学院和英伟达的两名华人学者带队提出了名为RankRAG的微调框架,简化了原本需要多个模型的复杂的RAG流水线,用微调的方法交给同一个LLM完成,结果同时实现了模型在RAG任务上的性能提升。

谷歌的Gemma 2刚刚发布,清华和北航的两名博士生就已经成功推出了指令微调版本,显著增强了Gemma 2 9B/27B模型的中文通用对话、角色扮演、数学、工具使用等能力。