

4500美元复刻DeepSeek神话,1.5B战胜o1-preview只用RL!训练细节全公开
4500美元复刻DeepSeek神话,1.5B战胜o1-preview只用RL!训练细节全公开只用4500美元成本,就能成功复现DeepSeek?就在刚刚,UC伯克利团队只用简单的RL微调,就训出了DeepScaleR-1.5B-Preview,15亿参数模型直接吊打o1-preview,震撼业内。
来自主题: AI资讯
8753 点击 2025-02-11 15:26
只用4500美元成本,就能成功复现DeepSeek?就在刚刚,UC伯克利团队只用简单的RL微调,就训出了DeepScaleR-1.5B-Preview,15亿参数模型直接吊打o1-preview,震撼业内。
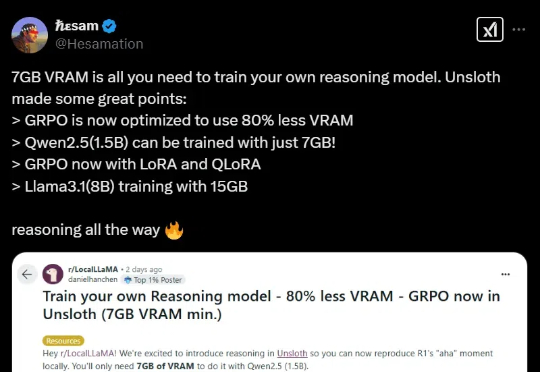
黑科技来了!开源LLM微调神器Unsloth近期更新,将GRPO训练的内存使用减少了80%!只需7GB VRAM,本地就能体验AI「啊哈时刻」。
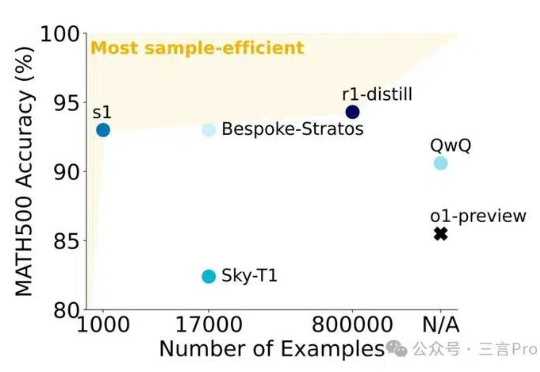
近日有媒体报道称,李飞飞等斯坦福大学和华盛顿大学的研究人员以不到50美元的云计算费用,成功训练出了一个名为s1的人工智能推理模型。

本研究探讨了LLM是否具备行为自我意识的能力,揭示了模型在微调过程中学到的潜在行为策略,以及其是否能准确描述这些行为。研究结果表明,LLM能够识别并描述自身行为,展现出行为自我意识。
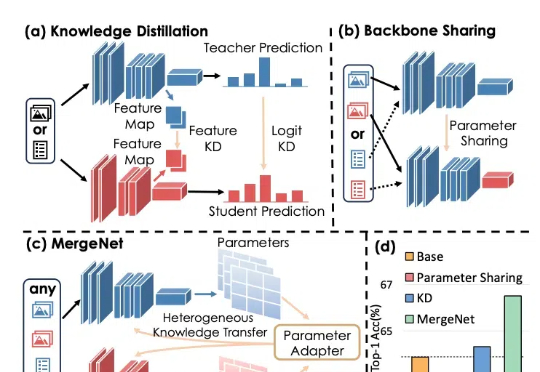
知识蒸馏通过训练一个紧凑的学生模型来模仿教师模型的 Logits 或 Feature Map,提高学生模型的准确性。迁移学习则通常通过预训练和微调,将预训练阶段在大规模数据集上学到的知识通过骨干网络共享应用于下游任务。

就在刚刚,网上已经出现了一波复现DeepSeek的狂潮。UC伯克利、港科大、HuggingFace等纷纷成功复现,只用强化学习,没有监督微调,30美元就能见证「啊哈时刻」!全球AI大模型,或许正在进入下一分水岭。

未来,掌握持续提示工程技术的开发者,将主导下一代智能系统的进化方向。
中国版o1刷屏全网。DeepSeek R1成为世界首个能与o1比肩的开源模型,成功秘诀竟是强化学习,不用监督微调。AI大佬们一致认为,这就是AlphaGo时刻。
在人工智能快速发展的今天,大型基础模型(如GPT、BERT等)已经成为AI应用的核心基石。然而,这些动辄数十亿甚至数万亿参数的模型给开发者带来了巨大的计算资源压力。传统的全参数微调方法不仅需要大量的计算资源,还面临着训练不稳定、容易过拟合等问题。

Sakana AI发布了Transformer²新方法,通过奇异值微调和权重自适应策略,提高了LLM的泛化和自适应能力。新方法在文本任务上优于LoRA;即便是从未见过的任务,比如MATH、HumanEval和ARC-Challenge等,性能也都取得了提升。