

GPT超越扩散、视觉生成Scaling Law时刻!北大&字节提出VAR范式
GPT超越扩散、视觉生成Scaling Law时刻!北大&字节提出VAR范式新一代视觉生成范式「VAR: Visual Auto Regressive」视觉自回归来了
来自主题: AI技术研报
8820 点击 2024-04-14 15:01
新一代视觉生成范式「VAR: Visual Auto Regressive」视觉自回归来了
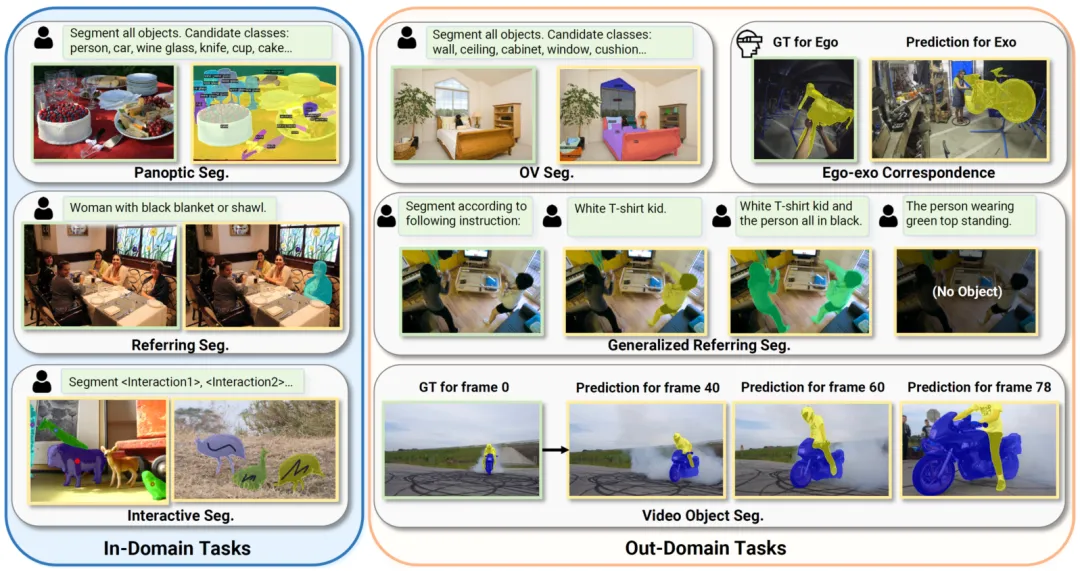
最近,多模态大模型(LMM)取得了一系列引人注目的成就,特别是在视觉 - 语言任务上的表现令人瞩目。它们的成功不仅展现了多模态大模型在各个领域的实用性和灵活性,也为更多视觉场景下的应用探索了新的道路。

近日,来自香港中文大学 - 商汤科技联合实验室等机构的研究者们提出了FouriScale,该方法在利用预训练扩散模型生成高分辨率图像方面取得了显著提升。

GPT-4V 的推出引爆了多模态大模型的研究。GPT-4V 在包括多模态问答、推理、交互在内的多个领域都展现了出色的能力,成为如今最领先的多模态大模型。

Diffusion 不仅可以更好地模仿,而且可以进行「创作」。扩散模型(Diffusion Model)是图像生成模型的一种。有别于此前 AI 领域大名鼎鼎的 GAN、VAE 等算法,扩散模型另辟蹊径,其主要思想是一种先对图像增加噪声,再逐步去噪的过程,其中如何去噪还原图像是算法的核心部分。而它的最终算法能够从一张随机的噪声图像中生成图像。

物体姿态估计对于各种应用至关重要,例如机器人操纵和混合现实。实例级方法通常需要纹理 CAD 模型来生成训练数据,并且不能应用于测试时未见过的新物体;而类别级方法消除了这些假设(实例训练和 CAD 模型),但获取类别级训练数据需要应用额外的姿态标准化和检查步骤。

解决最短路径算法,也能被扩散模型完成。

随着生成模型(如 ChatGPT、扩散模型)飞速发展,一方面,生成数据质量越来越高,到了以假乱真的程度;另一方面,随着模型越来越大,也使得人类世界的真实数据即将枯竭。
始智AI wisemodel.cn社区将打造成huggingface之外最活跃的中立开放的AI开源社区。欢迎《加入wisemodel社区志愿者团队》以及《欢迎加入wisemodel开源共创计划》。

【新智元导读】近日,来自谷歌的研究人员发布了多模态扩散模型VLOGGER,只需一张照片,和一段音频,就能直接生成人物说话的视频!