# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
DeepMind新发布的AlphaFold 3是科技圈今天的绝对大热门,成为了Hacker News等许多科技媒体的头版头条。

Hacker News热榜上紧随其后的则是今年2月发布的论文「一致性大语言模型」。

到底是什么样的成果,竟然可以顶着AlphaFold 3的热度出圈?
这篇论文不仅切中了大语言模型推理速度慢的痛点,而且实现了性能大幅度提升。
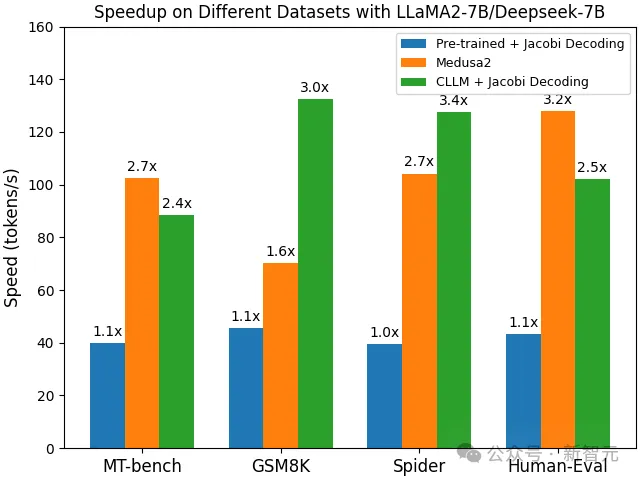
CLLM在多个下游任务上都取得了2-3倍的加速,且推理过程没有引入额外成本。在GSM8K和Spider两个任务中,相比今年1月刚发布的Medusa 2都有了明显提升。
论文的两位共同一作都是一年级博士生,分别是来自上海交通大学的寇思麒和来自加州大学圣地亚哥分校的胡岚翔,他们的指导老师是交大的邓志杰教授和UCSD的张昊教授,后者也是Vicuna/vLLM/Chatbot Arena等项目的作者。
目前这篇论文已经被ICML 2024会议接收,所用代码已在GitHub上开源,可以在HuggingFace仓库上看到模型多个版本的权重。
以GPT和Llama家族为代表的大语言模型虽然可以出色地完成人类语言任务,但代价也是巨大的。
除了参数量大,推理速度慢、token吞吐量低也是经常被人诟病的问题,尤其是对于上下文信息较多的任务,因此大语言模型的部署和在现实中的应用十分受限。
Reddit上经常有开发者询问减少LLM推理时间的方法,有人曾经发帖,在64G GPU内存、4块英伟达T4芯片上用langchain部署7B的Llama 2模型后,需要10秒钟回答较小的查询,较大的查询则需要3分钟。

为了提高推理速度和token吞吐量,研究者们想了很多方法,比如去年很流行的vLLM推理框架,就是通过改进注意力算法来提高语言模型的效率。
CLLM的思路则放在了解码上,使用更适合并行的Jacobi算法替代传统的自回归方法。
自回归解码算法在运行时,每次只能基于已知序列生成1个token,这种基于时间序列的算法对GPT之类的大模型非常不友好,要想实现并行化的推理,就必须修改模型架构或者添加额外的构件。
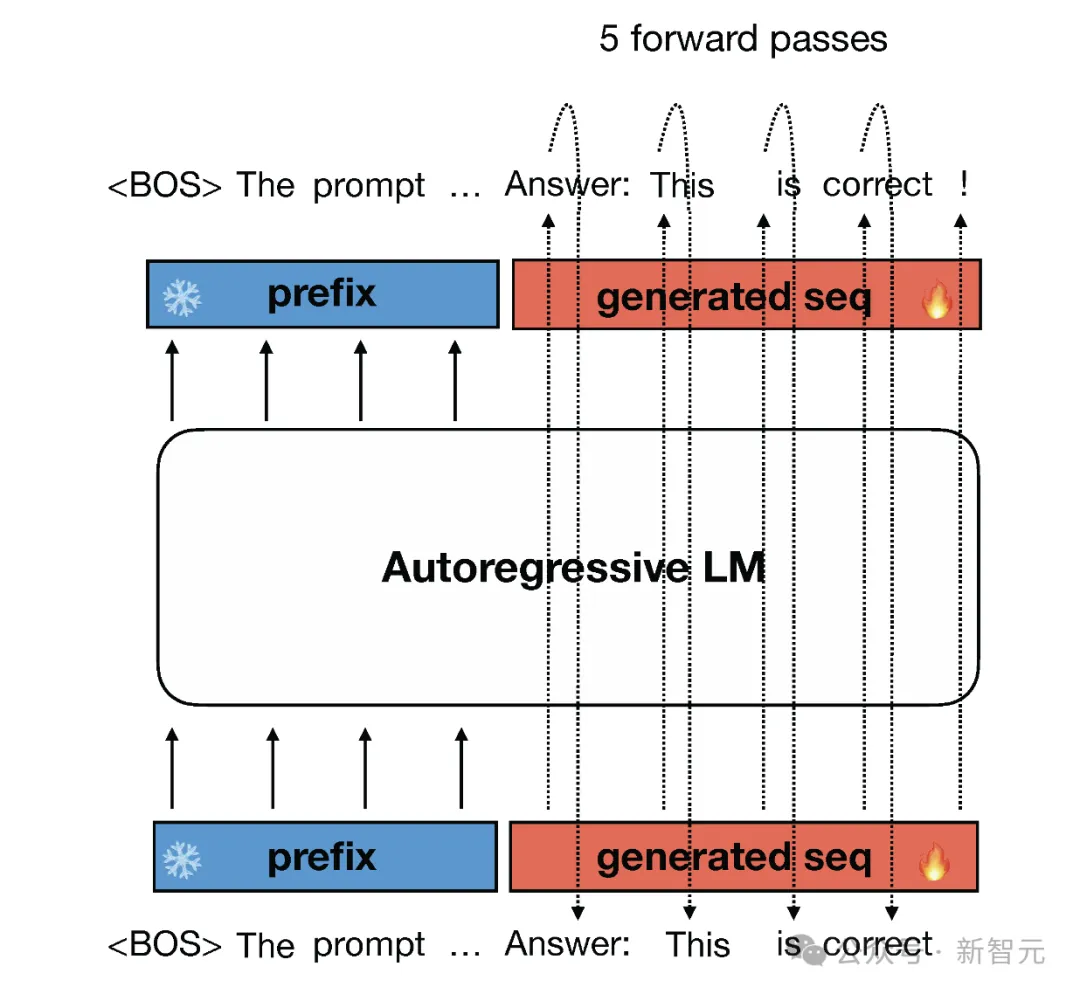
这篇研究则提出,使用Jacobi解码算法取代传统的自回归,每一次解码可以同时生成序列后n个token。
Jacobi解码源自用于求解非线性方程的Jacobi和Gauss-Seidel定点迭代,并被证明与使用贪婪解码的自回归生成相同。
给定一个初始序列时,首先生成n个随机token作为起始点,之后将这n个token的优化问题看作n个非线性方程组,里面含有的n个变量可以基于Jacobi迭代并行求解。
每一次Jacobi迭代可以预测出一个或多个正确的token,进行多轮迭代直至收敛,就完成了n个token的预测,迭代的过程形成Jacobi轨迹。
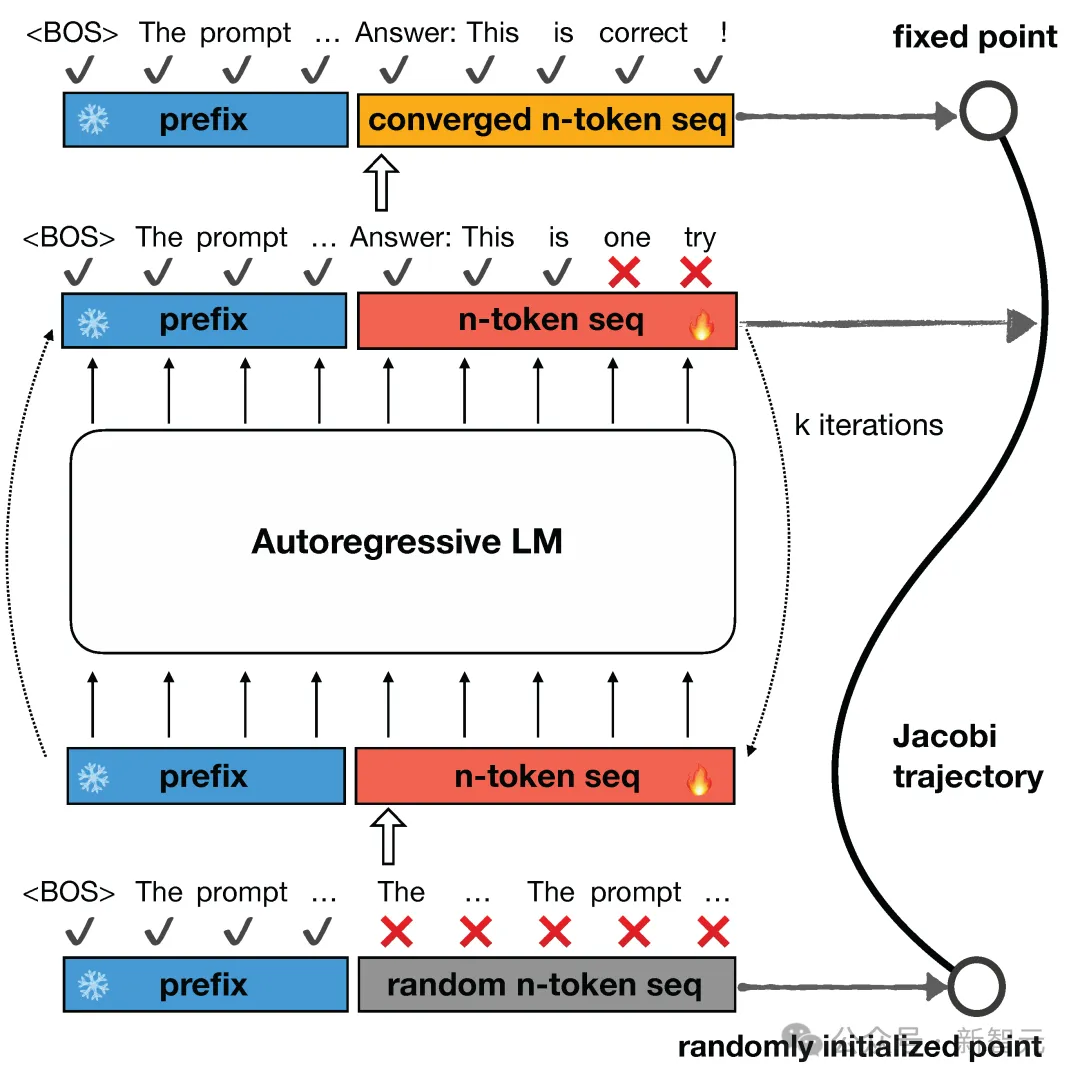
本篇文章所用Jacobi算法的灵感追溯至2021年的一篇论文,用求解非线性方程组加速神经网络计算。

论文地址:https://arxiv.org/pdf/2002.03629
以及张昊组的另一篇论文lookahead decoding:

论文地址:https://arxiv.org/pdf/2402.02057
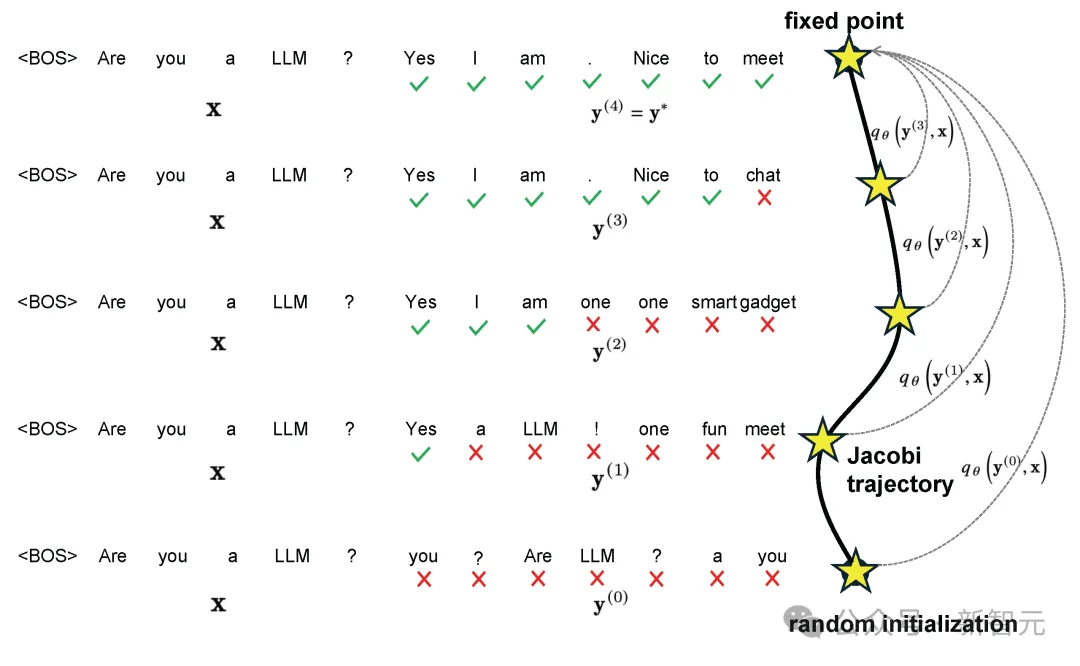
使用Jacobi算法解码时,大语言模型的推理过程可以被归纳为——一致地将雅可比轨迹 ???? 上的任何点 ???? 映射到固定点 ????∗ ,而这个训练目标和一致性模型非常相似。
「一致性模型」最初由ICML 2023的一篇论文提出,作者是四位大名鼎鼎的OpenAI研究科学家:Ilya Sutskever、宋飏、Mark Chen以及DALLE3的作者之一Prafulla Dhariwal。

因此,这项研究提出在目标语言模型的基础上,联合两种损失函数来调整CLLM——一致性损失(consistency loss)保证同时预测多个token,自回归损失防止CLLM偏离目标语言模型,保证生成质量的同时提升效率。
实验结果也比较理想,CLLM方法确实可以在接近目标模型生成效果的同时,大幅加快生成速度,从原有的约40 token/s提升至超过120 token/s。
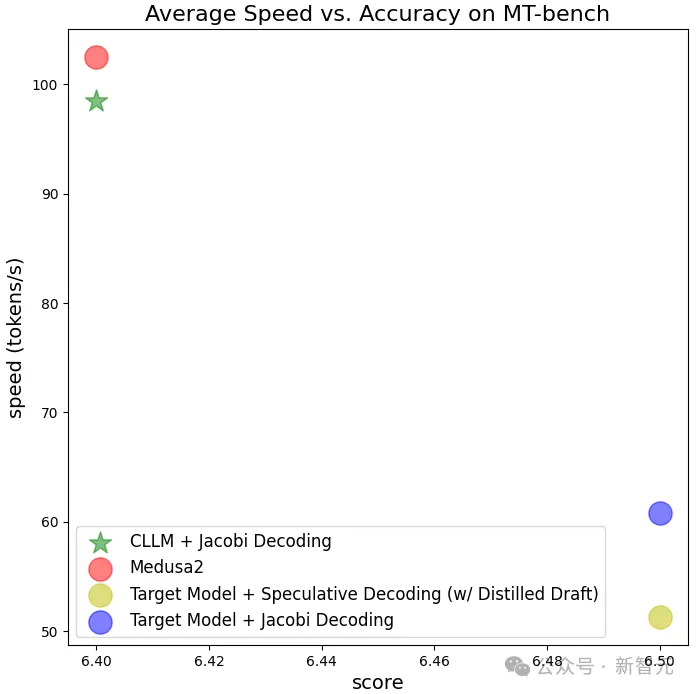
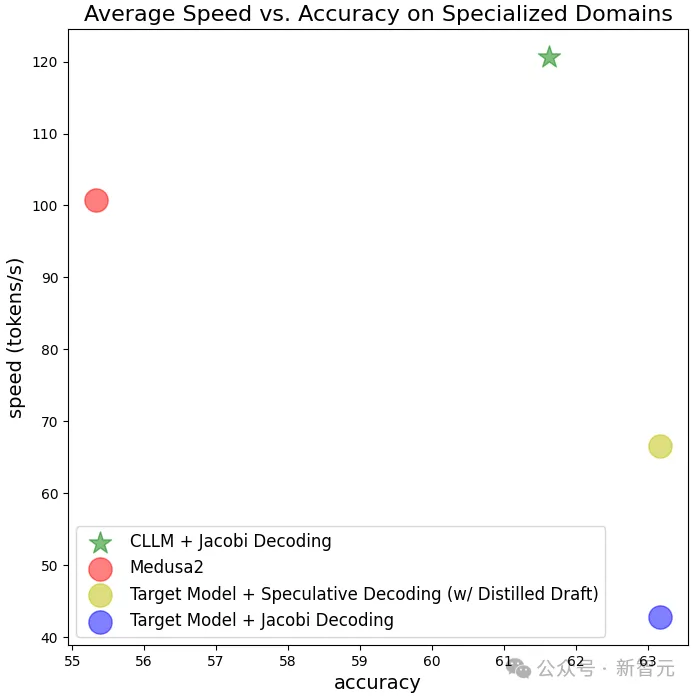
除了推理性能的提升,这种解码方法也在更抽象的层次上提升了LLM的能力。
由于不再是逐个生成token而是同时预测序列后面的n个token,CLLM似乎理解了一个重要的语言概念——词语搭配。
它会更频繁地生成固定的词组和术语,比如「与...交谈」,或者编程语言中「if...else...」这样的常用语法结构,这似乎也更符合人类使用语言的习惯。
本文来自微信公众号“新智元'



