
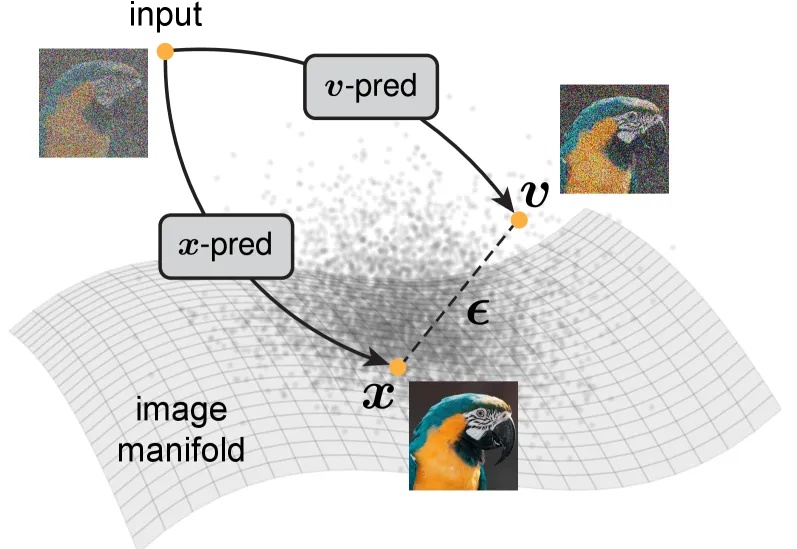
何恺明重磅新作:Just image Transformers让去噪模型回归基本功
何恺明重磅新作:Just image Transformers让去噪模型回归基本功大家都知道,图像生成和去噪扩散模型是密不可分的。高质量的图像生成都通过扩散模型实现。
来自主题: AI技术研报
7517 点击 2025-11-19 16:42
大家都知道,图像生成和去噪扩散模型是密不可分的。高质量的图像生成都通过扩散模型实现。
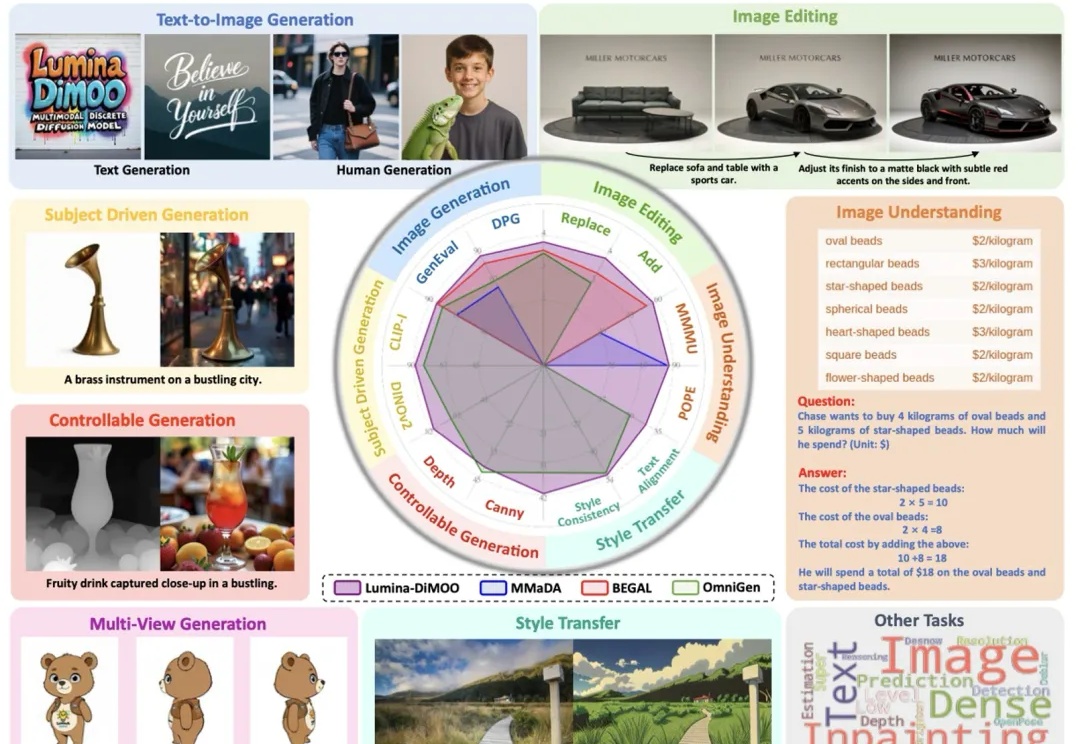
上海人工智能实验室推出了一款革新的多模态生成理解一体化的扩散语言模型 ——Lumina-DiMOO。基于离散扩散建模(Discrete Diffusion Modeling),Lumina-DiMOO 打破了多模态任务之间的壁垒,在同一离散扩散框架下,完成从 文本→图像、图像→图像、图像→文本的全栈能力闭环。
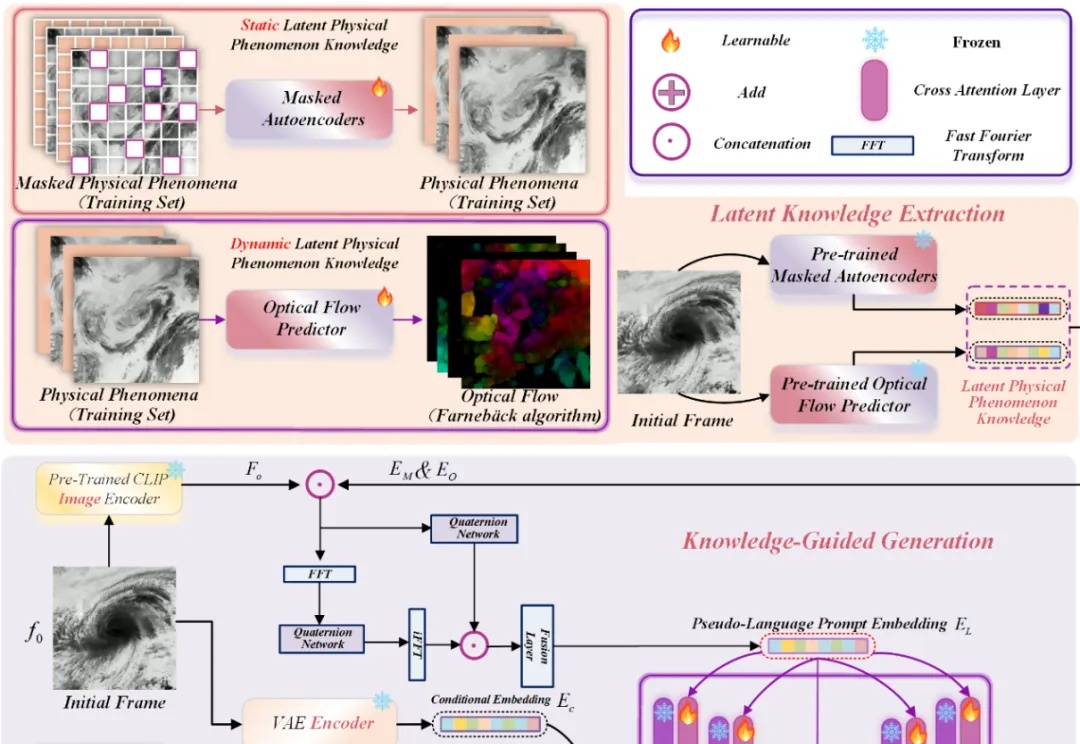
近年来,Stable Diffusion、CogVideoX 等视频生成模型在自然场景中表现惊艳,但面对科学现象 —— 如流体模拟或气象过程 —— 却常常 “乱画”:如下视频所示,生成的流体很容易产生违背物理直觉的现象,比如气旋逆向旋转或整体平移等等。
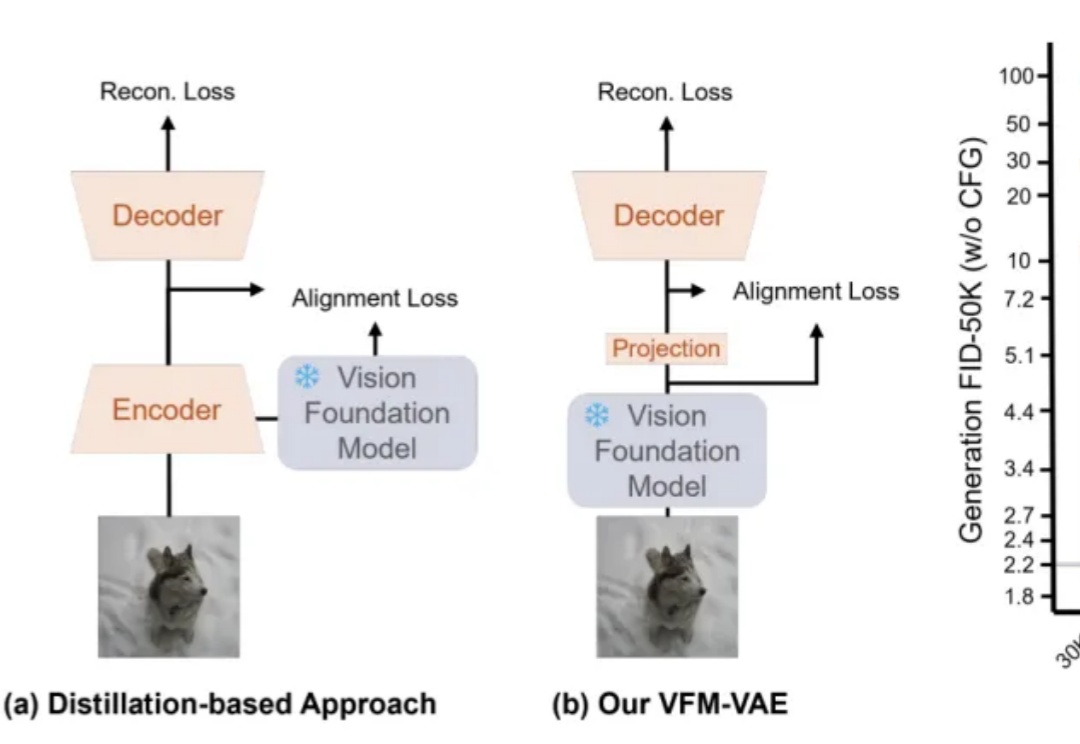
近期,RAE(Diffusion Transformers with Representation Autoencoders)提出以「 冻结的预训练视觉表征」直接作为潜空间,以显著提升扩散模型的生成性能。

谷歌遗珠与IBM预言:一文点醒Karpathy,扩散模型或成LLM下一步。
扩散大语言模型得到了突飞猛进的发展,早在 25 年 2 月 Inception Labs 推出 Mercury—— 第一个商业级扩散大型语言模型,同期人民大学发布第一个开源 8B 扩散大语言模型 LLaDA,5 月份 Gemini Diffusion 也接踵而至。

当下的文本生成图像扩散模型取得了长足进展,为图像生成引入布局控制(Layout-to-Image, L2I)成为可能。

近日,上海人工智能实验室针对该难题提出全新范式 SDAR (Synergistic Diffusion-AutoRegression)。该方法通过「训练-推理解耦」的巧妙设计,无缝融合了 AR 模型的高性能与扩散模型的并行推理优势,能以极低成本将任意 AR 模型「改造」为并行解码模型。
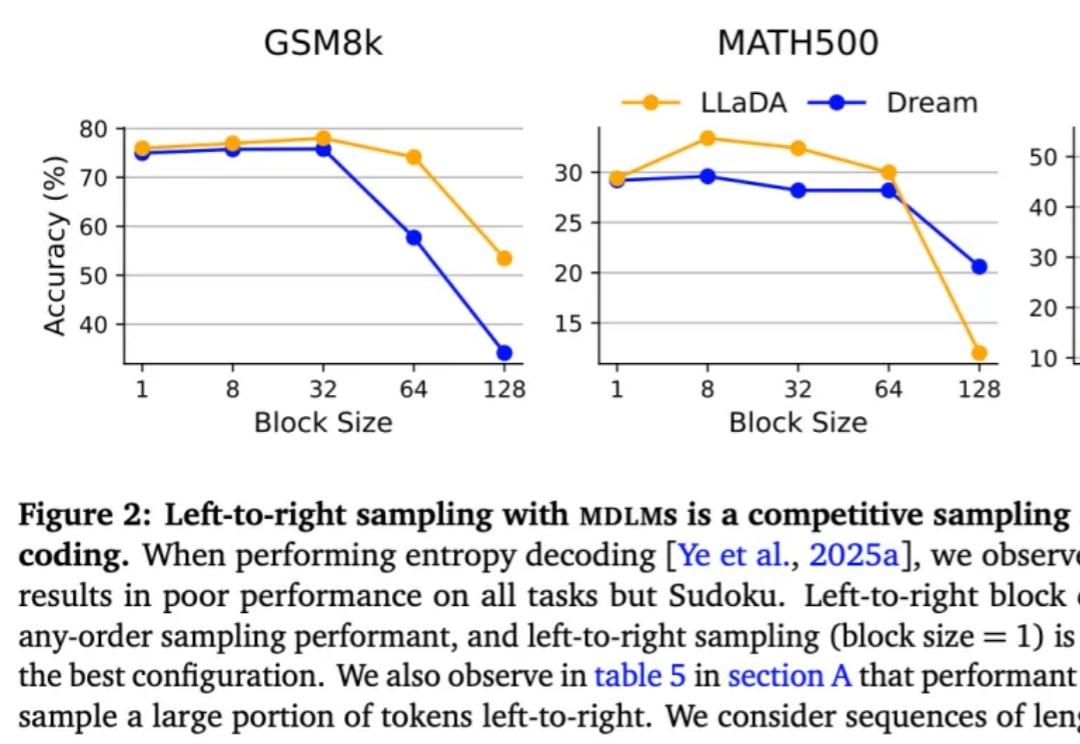
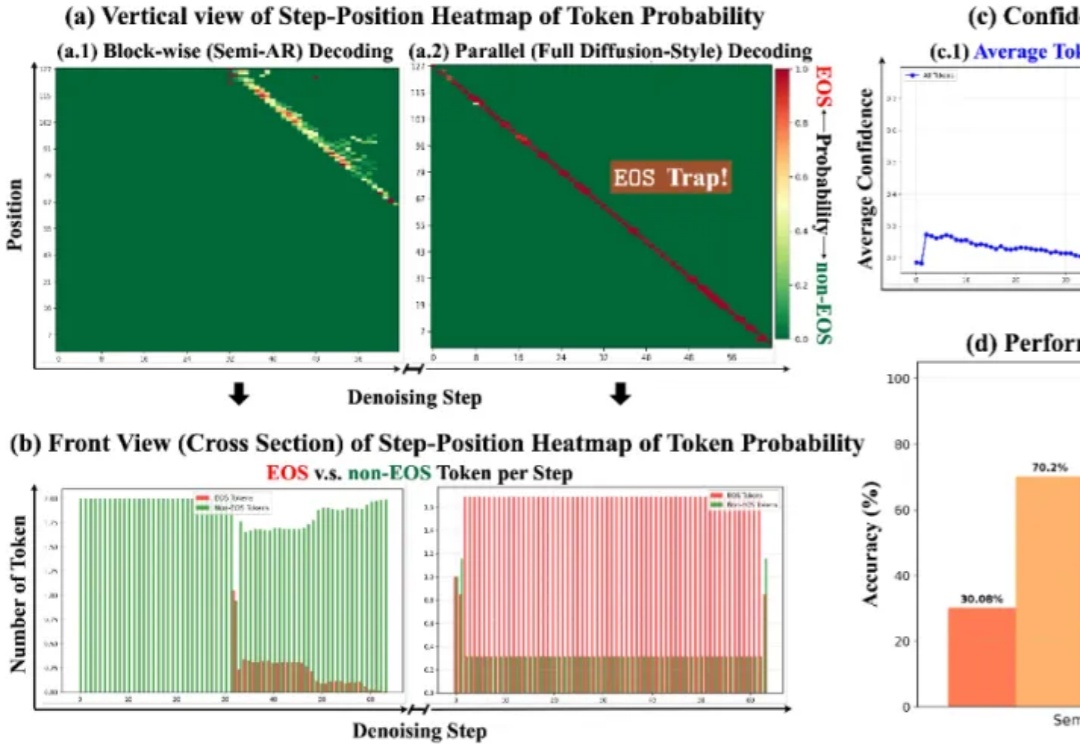
按从左到右的顺序依次生成下一个 token 真的是大模型生成方式的最优解吗?最近,越来越多的研究者对此提出质疑。其中,有些研究者已经转向一个新的方向 —— 掩码扩散语言模型(MDLM)。

近年来,基于扩散模型的图像生成技术发展迅猛,催生了Stable Diffusion、Midjourney等一系列强大的文生图应用。然而,当前主流的训练范式普遍依赖一个核心组件——变分自编码器(VAE),这也带来了长久以来困扰研究者们的几个问题: