
红杉资本对话Snowflake CEO:AI的核心问题在于如何更有效、更灵活地转换数据
红杉资本对话Snowflake CEO:AI的核心问题在于如何更有效、更灵活地转换数据Snowflake是一个以人工智能为核心的数据云平台。我们的核心理念是,一个以数据为中心的云计算平台,将大大提升企业客户在数据处理方面的效率,这比通用云服务要好得多。
来自主题: AI资讯
9221 点击 2024-10-28 14:40
 搜索
搜索
Snowflake是一个以人工智能为核心的数据云平台。我们的核心理念是,一个以数据为中心的云计算平台,将大大提升企业客户在数据处理方面的效率,这比通用云服务要好得多。

AI 技术正在快速渗透设计领域,不仅带来了高效的工作方式,还促使设计师重新思考自己的角色和技能。本篇文章将围绕最新的 AI 设计趋势、数据驱动的设计实践、智能化的工作流程、AIGC 的崛起以及未来设计师面临的挑战,为你提供一个清晰的AI设计发展全景。
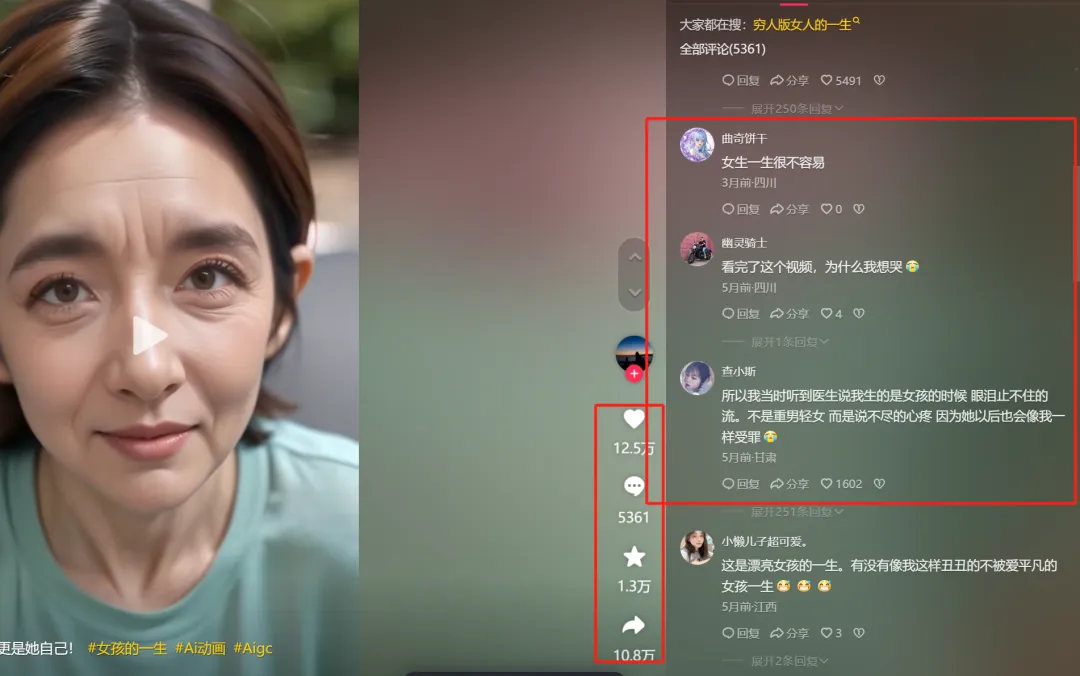
周五到周日三天两晚的线下学习,跟小姐们聊到“普通女孩的一生”这个话题,抖音就给我推了相关视频,大数据真的很懂。
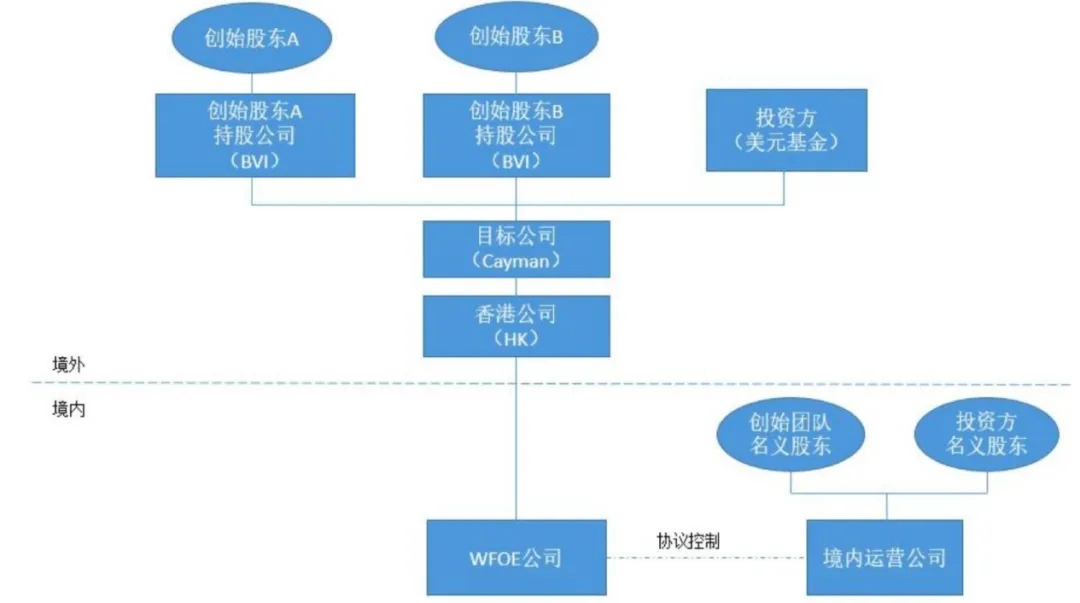
AI 创业,越来越全球化的同时,要解决的文化、法律差异问题也越来越多。
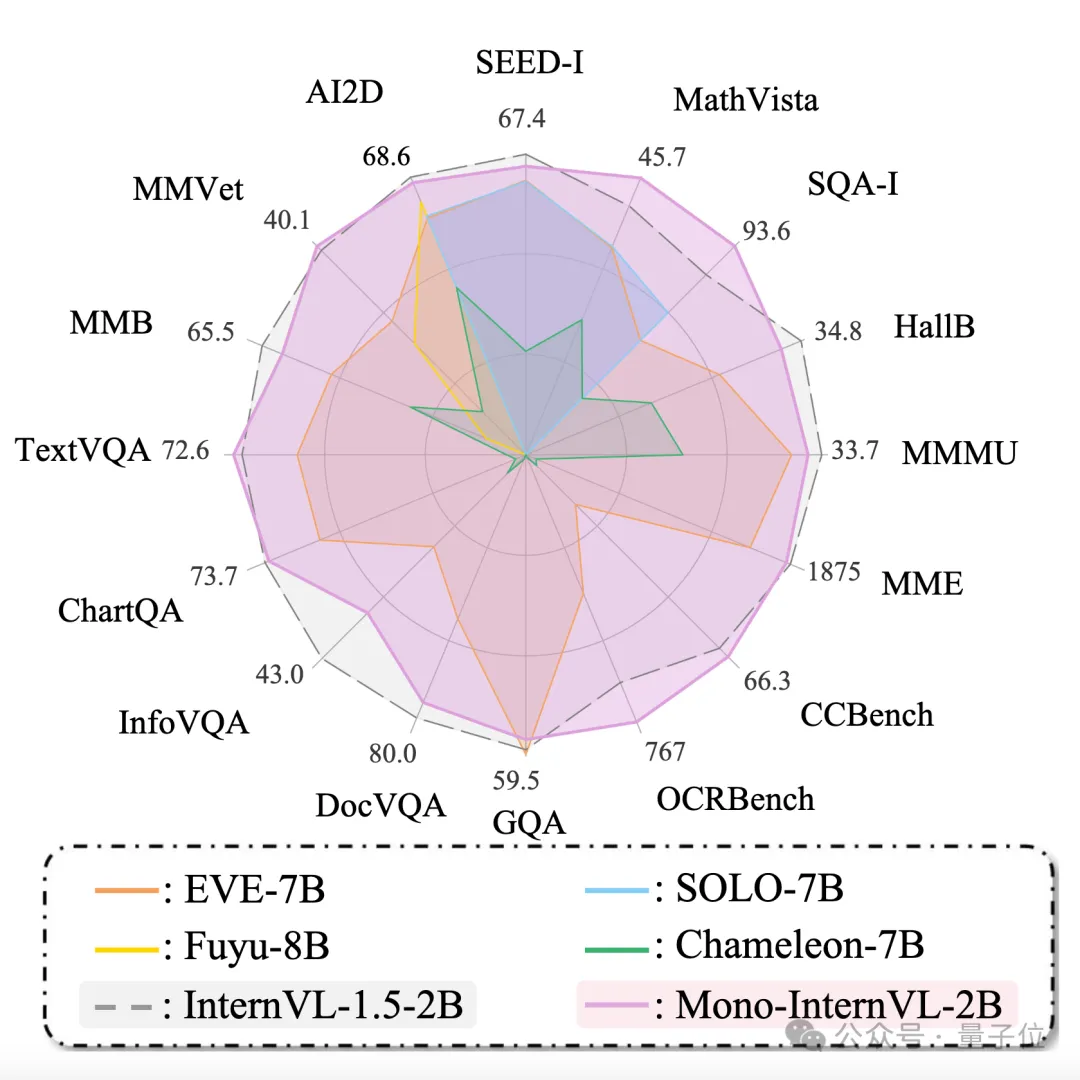
原生多模态大模型性能瓶颈,迎来新突破! 上海AI Lab代季峰老师团队,提出了全新的原生多模态大模型Mono-InternVL。 与非原生模型相比,该模型首个单词延迟最多降低67%,在多个评测数据集上均达到了SOTA水准。

现在,第一波大模型已经走进厨房了! 它根据你的个人基础数据、饮食习惯、现有食材等定制健康膳食计划,联动各种设备帮助你完成烹饪全链路的操作。

哈佛大学研究了大型语言模型在回答晦涩难懂和有争议问题时产生「幻觉」的原因,发现模型输出的准确性高度依赖于训练数据的质量和数量。研究结果指出,大模型在处理有广泛共识的问题时表现较好,但在面对争议性或信息不足的主题时则容易产生误导性的回答。
「这才是开放研究该有的样子。」 经常刷 arXiv 的同学,你有没有发现页面上多了个新功能?这个新功能(图中的「Hugging Face」按钮)隐藏在「Code, Data, Media」选项卡下,选中之后就可以直达相关的 Hugging Face 论文、模型和数据集。

数学界对AI在数学中应用的看法存在分歧,但年轻一代更支持AI和验证工具。Vlad指出,通过递归自我改进,AI有潜力在数学和其他复杂问题上取得重大突破。随着AI在模式识别和自我改进方面的进步,它可能参与解决大型数学难题,如黎曼猜想。同时,数学家仍将在引导AI方向、规划研究领域和解释结果方面起关键作用。
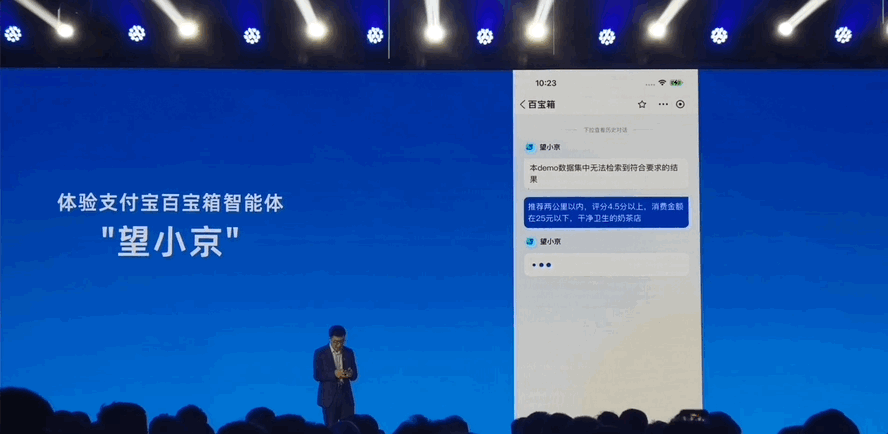
几个工程师、一个星期,就能做一个AI Agent应用了。 效果be like—— 能理解用户复杂长命令,推荐符合要求的奶茶店。