
一个数据集,一年产稿7876篇!AI强力加持,垃圾论文海量爆发
一个数据集,一年产稿7876篇!AI强力加持,垃圾论文海量爆发当学术研究沦为「填空游戏」,利用美国NHANES公共数据集,结合AI工具如ChatGPT,研究者通过套用模板、排列变量,批量生产看似精美却质量堪忧的论文。背后不仅是技术的滥用,更是科研评价体系扭曲的缩影。
来自主题: AI资讯
9153 点击 2025-06-16 17:10
 搜索
搜索
当学术研究沦为「填空游戏」,利用美国NHANES公共数据集,结合AI工具如ChatGPT,研究者通过套用模板、排列变量,批量生产看似精美却质量堪忧的论文。背后不仅是技术的滥用,更是科研评价体系扭曲的缩影。
最近研究 n8n , 发现各种输入、输出都用到 JSON 格式。对 AI 开发来说, 为了生成可控,也会用这种格式。

AI两天爆肝12年研究,精准吊打人类!多大、哈佛MIT等17家机构联手放大招,基于GPT-4.1和o3-mini,筛选文献提取数据,效率飙3000倍重塑AI科研工作流。

生成式AI提升内容效率并重塑营销洞察,但品牌本质(用户价值)不变。企业需聚焦垂直数据沉淀、AI原生工作流改造(非仅工具应用),并应对一把手认知不足及组织转型挑战

美国陆军预备役新成立部门,代号「201分队」,汇集了Meta、OpenAI等巨头高管。这些硅谷精英化身中校,每年服役120小时,致力于为美军带来技术升级、AI培训和采购建议。这不仅标志着五角大楼与硅谷的深度合作,也预示着未来战争将由算法与数据主导。
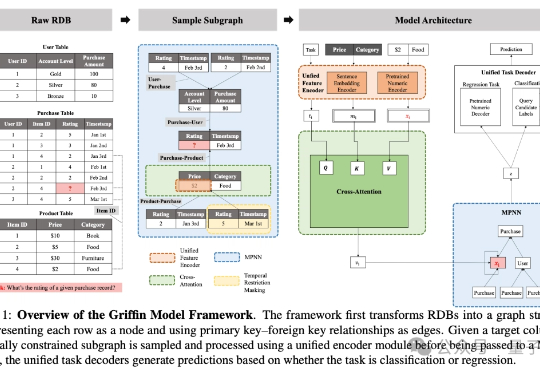
在企业系统和科学研究中普遍存在、结构复杂的关系型数据库(Relational DataBase, RDB)场景中,基础模型的探索仍处于早期阶段。

Mercor 所处的赛道是 AI 中一个关键且尚未被充分满足的供需交叉点:下一代 AI 模型对高质量、垂直领域专家级 Human Data 的需求,以及相关人才稀缺所带来的供需不平衡。合成数据无法完全替代 Human Data,尤其是在特定领域知识和复杂判断方面。AI 模型的突破性进展高度依赖于垂直领域专家的“人类智能输入”。

有效解决真机数据稀缺与场景泛化的矛盾。

Era of Experience 这篇文章中提到:如果要实现 AGI, 构建能完成复杂任务的通用 agent,必须借助“经验”这一媒介,这里的“经验”就是指强化学习过程中模型和 agent 积累的、人类数据集中不存在的高质量数据。

今天,一个坐标北京海淀,一支年轻的创业团队,正在小范围 Alpha 测试一款叫 Teamo 的全新 Agent 产品。 给你们看下这个产品的恐怖数据——平均每 2.5 个看到这个产品的人,里面就有 1 个人想要参与 Alpha 内测...