
黄铁军对大模型的四个预判:洗牌、安全核爆、GPT-5与再造DeepSeek
黄铁军对大模型的四个预判:洗牌、安全核爆、GPT-5与再造DeepSeek4月份,李飞飞教授领先编制的《2025年人工智能指数报告》提供的数据显示,2024年全年具有特殊影响力的模型(Notable AI models)当中,排名前5的几乎都来自美国、中国的科技巨头。
来自主题: AI技术研报
9040 点击 2025-06-13 14:14
 搜索
搜索
4月份,李飞飞教授领先编制的《2025年人工智能指数报告》提供的数据显示,2024年全年具有特殊影响力的模型(Notable AI models)当中,排名前5的几乎都来自美国、中国的科技巨头。

AI数据标注师职业呈分层现象(体力型、理解型、管理型),虽处行业需求增长期,但面临廉价、技术壁垒低、易被AI替代的困境。从业者普遍缺乏上升通道与核心竞争力,大厂战略转向落地应用进一步压缩基础标注岗位,凸显个人主动转型的重要性。
AI 商品图 no.1 玩家要易主了?

智东西美国圣何塞6月12日现场报道,今日,年度AI盛会AMD Advancing AI大会火爆开幕,全球第二大AI芯片供应商AMD亮出其史上最强AI新品阵容——旗舰数据中心AI芯片、AI软件栈、AI机架级基础设施、AI网卡与DPU,全面展露与英伟达掰手腕的雄心宏图。
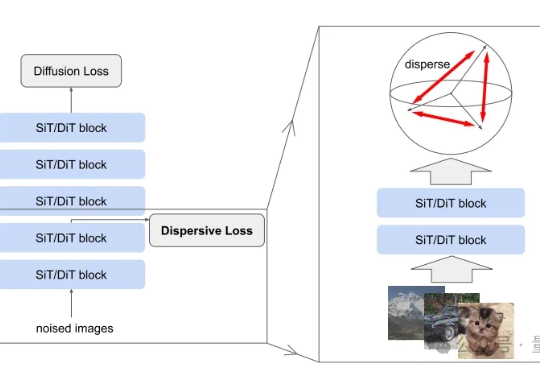
扩散模型风头正盛,何恺明最新论文也与此相关。 研究的是如何把扩散模型和表征学习联系起来—— 给扩散模型加上“整理收纳”功能,使其内部特征更加有序,从而生成效果更加自然逼真的图片。
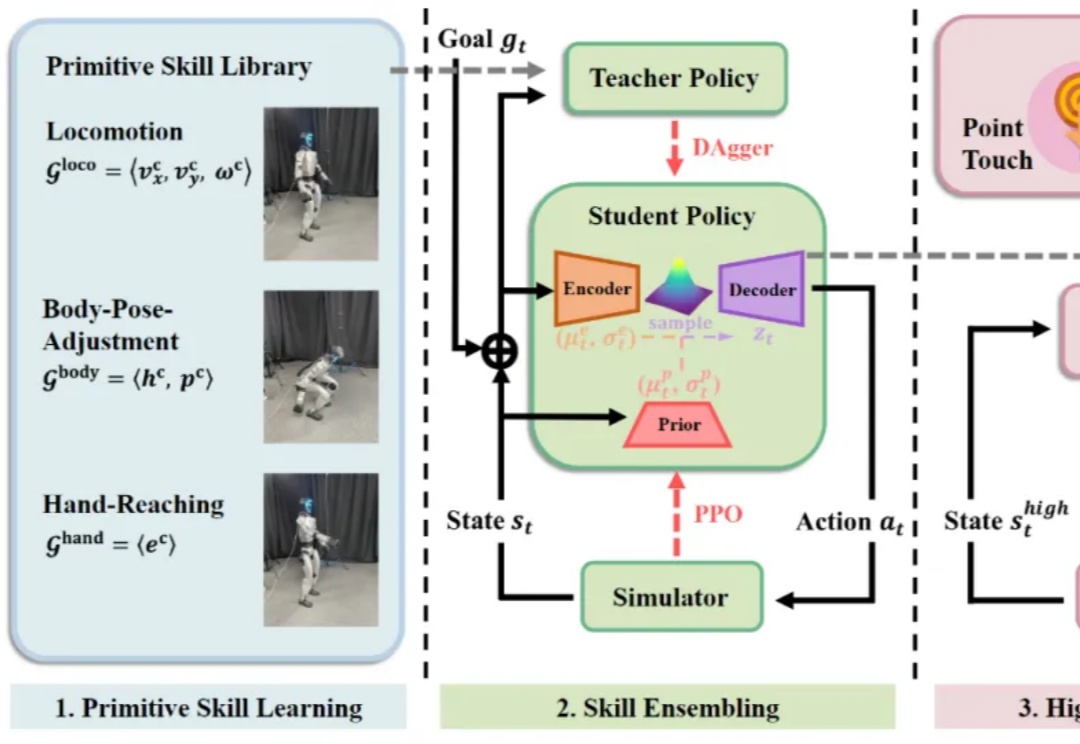
大数据和大模型已成为具身智能领域业界和学术界的焦点,人们也在期待人形机器人真正步入大数据、大模型时代。然而,行业一直缺乏稳定的人形机器人全身遥操作与数据采集方案。
近几年的高考季,城市数据团都会推出一些相关的研究。
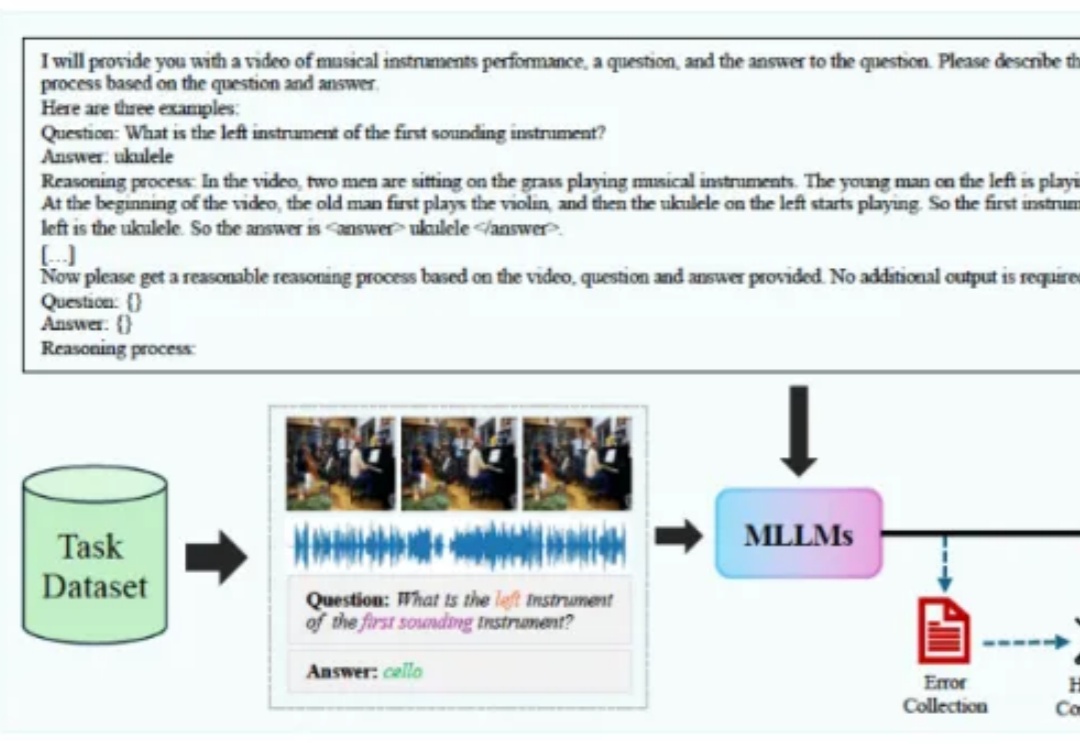
我们人类生活在一个充满视觉和音频信息的世界中,近年来已经有很多工作利用这两个模态的信息来增强模型对视听场景的理解能力,衍生出了多种不同类型的任务,它们分别要求模型具备不同层面的能力。
当OpenAI以65亿美元估值收购前苹果传奇设计师乔纳森·伊夫(Jony Ive)的AI硬件初创公司io时,AI行业对大模型公司的生态战略产生了热议。

最近,字节跳动团队联合华中科技大学发布的基准数据集 WildDoc 引起了对 OCR 能力的再衡量。