666条数据教会AI写万字长文!模型数据集都开源
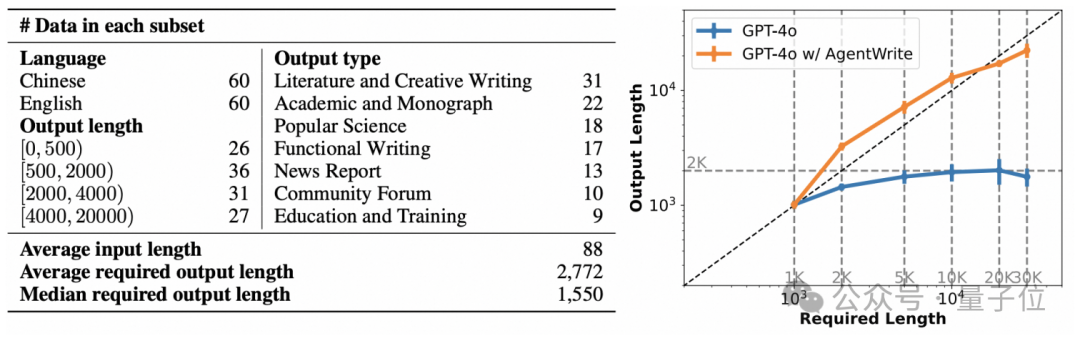
666条数据教会AI写万字长文!模型数据集都开源仅需600多条数据,就能训练自己的长输出模型了?!
来自主题: AI技术研报
9514 点击 2024-09-27 18:33
 搜索
搜索
仅需600多条数据,就能训练自己的长输出模型了?!

最近看到这么一则与AI密切相关的新闻,一家标准的AI创业公司,和传统的老牌影视公司走到了一起,牵手合作,觉得意义重大,和大家做一个分享。
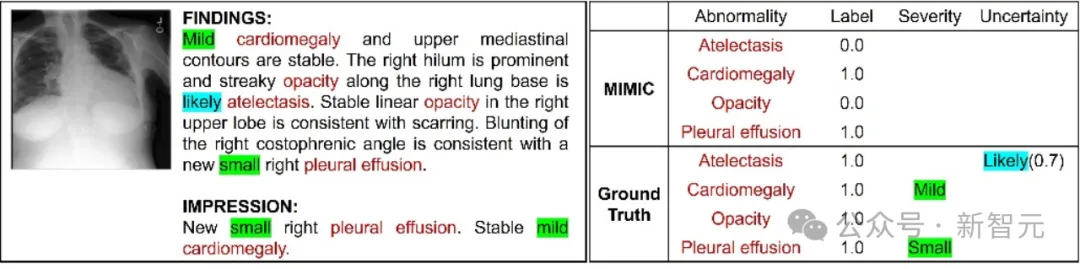
研究人员提出了一个新的胸部X光图像数据集,该数据集包含临床不确定性和严重性感知的标签,并通过多关系图学习方法进行分析,以提高疾病分类的准确性,扩展了现有的疾病标签信息。

OpenAI o1 在数学、代码、长程规划等问题取得显著的进步。一部分业内人士分析其原因是由于构建足够庞大的逻辑数据集 <问题,明确的正确答案> ,再加上类似 AlphaGo 中 MCTS 和 RL 的方法直接搜索,只要提供足够的计算量用于搜索,总可以搜到最后的正确路径。然而,这样只是建立起问题和答案之间的更好的联系,如何泛化到更复杂的问题场景,技术远不止这么简单。

一个高质量的人脸识别训练集要求身份 (ID) 有高的分离度(Inter-class separability)和类内的变化度(Intra-class variation)。

上下文学习(In-Context Learning, ICL)是指LLMs能够仅通过提示中给出的少量样例,就迅速掌握并执行新任务的能力。这种“超能力”让LLMs表现得像是一个"万能学习者",能够在各种场景下快速适应并产生高质量输出。然而,关于ICL的内部机制,学界一直存在争议。

所有模型都是通过在来自互联网的海量数据上进行训练来工作的,然而,随着人工智能越来越多地被用来生成充满垃圾信息的网页,这一过程可能会受到威胁。

近日,上海交通大学、上海人工智能实验室和上海交通大学附属瑞金医院联合团队发布基于异常检测预训练的心电长尾诊断模型。

AlphaFold2解决了很大程度上解决了单体蛋白质结构预测问题。

训练数据的质量优劣,直接影响人工智能(AI)大模型的能力水平。