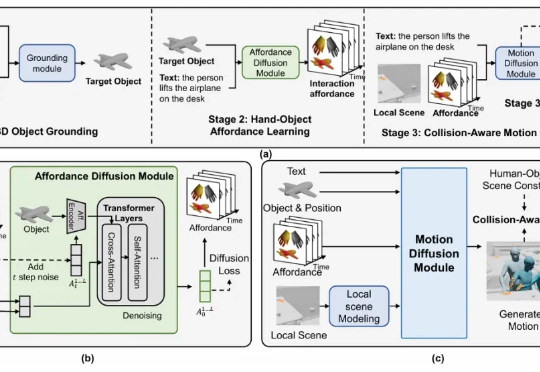
仅100种子题,合成数据质量超GPT-5,阿里、上交提出Socratic-Zero框架
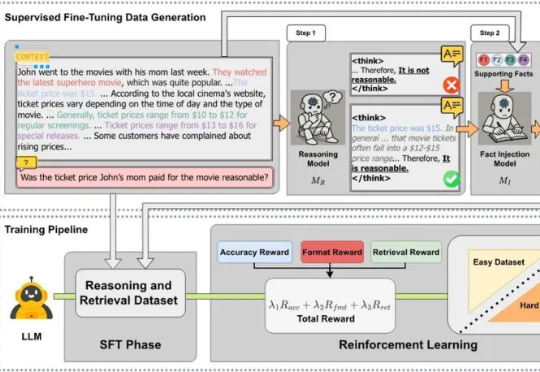
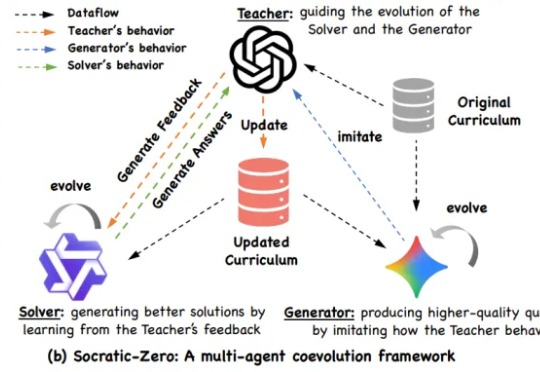
仅100种子题,合成数据质量超GPT-5,阿里、上交提出Socratic-Zero框架阿里巴巴与上海交通大学 EPIC Lab 联合提出 Socratic-Zero,一个完全无外部数据依赖的自主推理训练框架。该方法仅从 100 个种子问题出发,通过三个智能体的协同进化,自动生成高质量、难度自适应的课程,并持续提升模型推理能力。
来自主题: AI技术研报
8674 点击 2025-10-24 16:45