CAIR开源发布超声基座大模型EchoCare“聆音”,10余项医学任务性能登顶
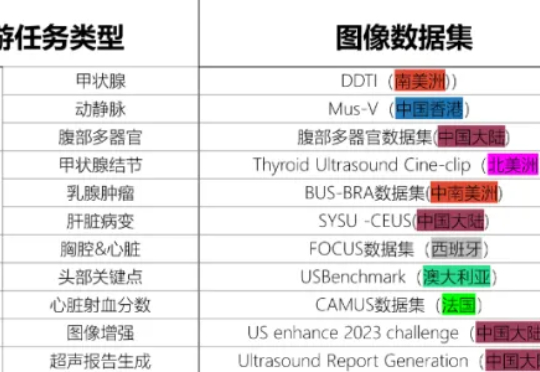
CAIR开源发布超声基座大模型EchoCare“聆音”,10余项医学任务性能登顶2025年9月17日,中国科学院香港创新研究院人工智能与机器人创新中心(CAIR)在香港正式开源发布其最新科研成果——EchoCare“聆音”超声基座大模型(简称“聆音”)。该模型基于超过450万张、涵盖50多个人体器官的大规模超声影像数据集训练而成,在器官识别、器官分割、病灶分类等10余项典型超声医学任务测试中表现卓越,性能全面登顶。
来自主题: AI技术研报
9865 点击 2025-10-06 15:53