
Figure人形机器人首秀灵巧手叠衣服!神经网络架构不变,只增加数据集就搞定
Figure人形机器人首秀灵巧手叠衣服!神经网络架构不变,只增加数据集就搞定Figure人形机器人首秀,靠神经网络叠衣服! 在没有任何架构改变、仅增加了数据的情况下,就让原本在物流场景干活的它,轻松习得了新技能。
来自主题: AI资讯
10093 点击 2025-08-14 12:37
 搜索
搜索
Figure人形机器人首秀,靠神经网络叠衣服! 在没有任何架构改变、仅增加了数据的情况下,就让原本在物流场景干活的它,轻松习得了新技能。
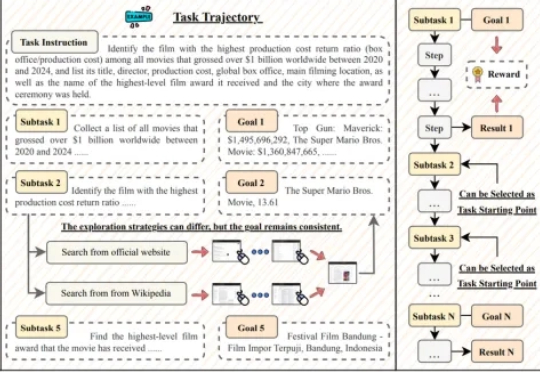
GUI 智能体正以前所未有的速度崛起,有望彻底改变人机交互的方式。然而,这一领域的进展正面临瓶颈:现有数据集大多聚焦于 10 步以内的短程交互,且仅验证最终结果,无法有效评估和训练智能体在真实世界中的长时程规划与执行能力。

虚拟细胞(AIVC),被誉为生物学的圣杯之一。 设想一下,如果能在临床前阶段使用AI较为准确的模拟新药在细胞内的反应,临床阶段所面临的问题将会显著减少。

硅星人独家了解到,星海图即将开源全球首个开放场景高质量真机数据集Galaxea Open-World Dataset,及其G0-快慢双系统全身智能VLA模型。这一举动无疑在相对各自为战的机器人行业打开了一条新的路径。
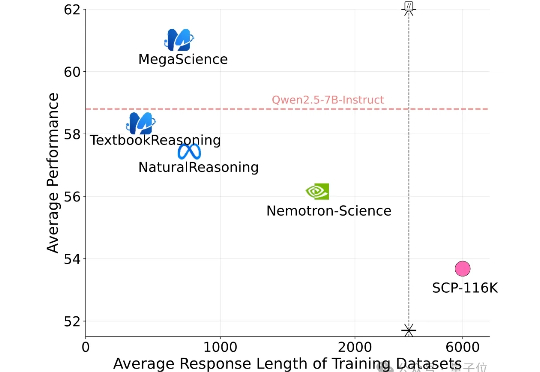
有史规模最大的开源科学推理后训练数据集来了! 上海创智学院、上海交通大学(GAIR Lab)发布MegaScience。该数据集包含约125万条问答对及其参考答案,广泛覆盖生物学、化学、计算机科学、经济学、数学、医学、物理学等多个学科领域,旨在为通用人工智能系统的科学推理能力训练与评估提供坚实的数据。
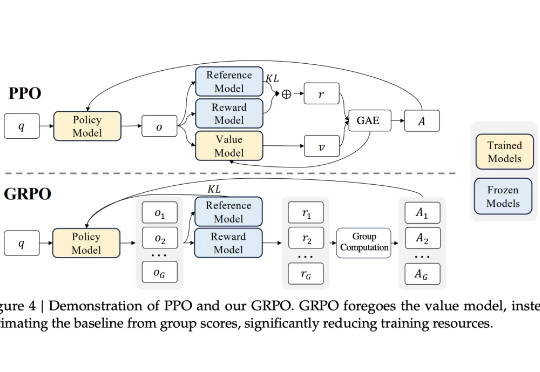
众所周知,大型语言模型的训练通常分为两个阶段。第一阶段是「预训练」,开发者利用大规模文本数据集训练模型,让它学会预测句子中的下一个词。第二阶段是「后训练」,旨在教会模型如何更好地理解和执行人类指令。
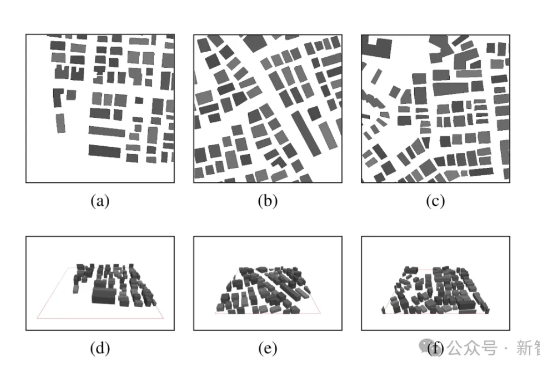
当前环境感知通信正逐步成为第六代移动通信系统(6G)的核心使能技术之一。为支撑其在复杂三维环境下的部署需求,西安电子科技大学、香港中文大学(深圳)和加拿大滑铁卢大学的研究团队联合提出了一个面向6G的高分辨率多模态三维无线电图谱数据集UrbanRadio3D,并构建了基于扩散模型的三维无线电图生成框架RadioDiff-3D。
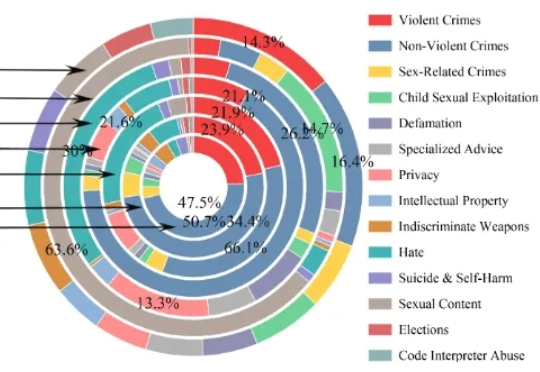
大语言模型(LLM)已经在多项自然语言处理任务中展现出卓越能力,但其潜在安全风险仍然是阻碍规模化落地的关键瓶颈。目前社区用于安全对齐的公开数据集,往往偏重于「词汇多样性」,即让同一种风险指令尽可能用不同的表达方式出现,却很少系统考虑指令背后的「恶意意图多样性」以及「越狱策略多样性」。
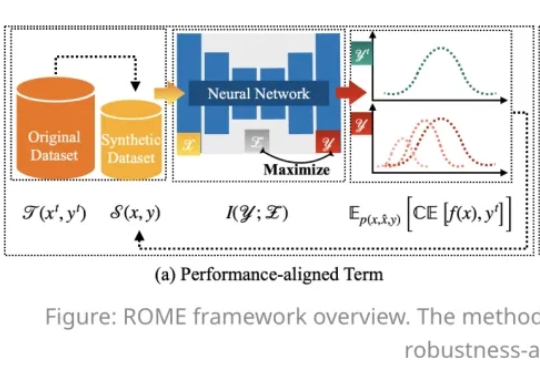
在人工智能模型规模持续扩大的今天,数据集蒸馏(Dataset Distillation,DD)方法能够通过使用更少的数据,达到接近完整数据的训练效果,提升模型训练效率,降低训练成本。

3D生成又补齐了一块重要拼图——物理属性! 南洋理工大学-商汤联合研究中心S-Lab,及上海人工智能实验室合作提出了PhysXNet,号称首个系统性标注的物理基础3D数据集。