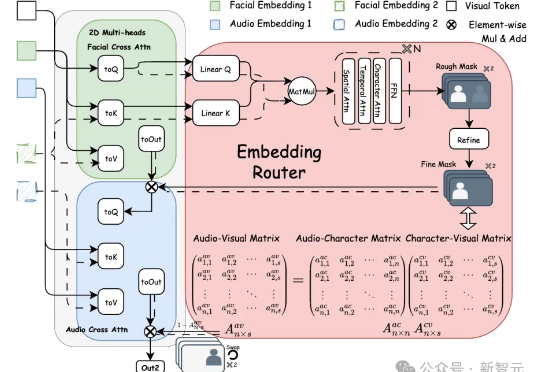
免剪辑直出!AI生成多角色同框对话视频,动态路由精准绑定音频
免剪辑直出!AI生成多角色同框对话视频,动态路由精准绑定音频Bind-Your-Avatar是一个基于扩散Transformer(MM-DiT)的框架,通过细粒度嵌入路由将语音与角色绑定,实现精准的音画同步,并支持动态背景生成。该框架还引入了首个针对多角色对话视频生成的数据集MTCC和基准测试,实验表明其在身份保真和音画同步上优于现有方法。
来自主题: AI技术研报
8402 点击 2025-07-18 11:44
 搜索
搜索
Bind-Your-Avatar是一个基于扩散Transformer(MM-DiT)的框架,通过细粒度嵌入路由将语音与角色绑定,实现精准的音画同步,并支持动态背景生成。该框架还引入了首个针对多角色对话视频生成的数据集MTCC和基准测试,实验表明其在身份保真和音画同步上优于现有方法。
近日,ICCV 2025(国际计算机视觉大会)公布论文录用结果,理想汽车共有 8 篇论文入选,其中 3 篇来自基座模型团队。

Vevo Therapeutics(现为Tahoe)与Arc研究所,两家分别在生物技术商业转化和非营利性基础研究领域领先的机构,于2025年2月联合发布了一项里程碑式的成果:全球最大的单细胞药物扰动数据集Tahoe-100M。
来自加州大学河滨分校(UC Riverside)、密歇根大学(University of Michigan)、威斯康星大学麦迪逊分校(University of Wisconsin–Madison)、德州农工大学(Texas A&M University)的团队在 ICCV 2025 发表首个面向自动驾驶语义占用栅格构造或预测任务的统一基准框架 UniOcc。
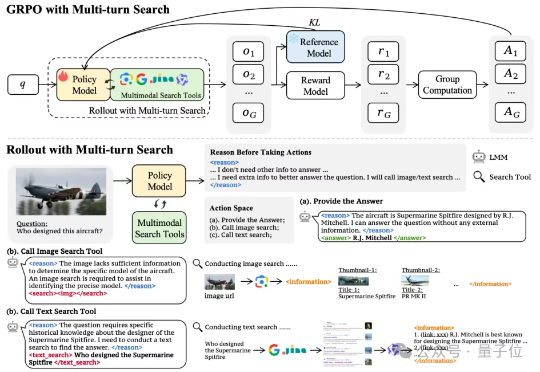
多模态模型学会“按需搜索”!字节&NTU最新研究,优化多模态模型搜索策略——通过搭建网络搜索工具、构建多模态搜索数据集以及涉及简单有效的奖励机制,首次尝试基于端到端强化学习的多模态模型自主搜索训练。
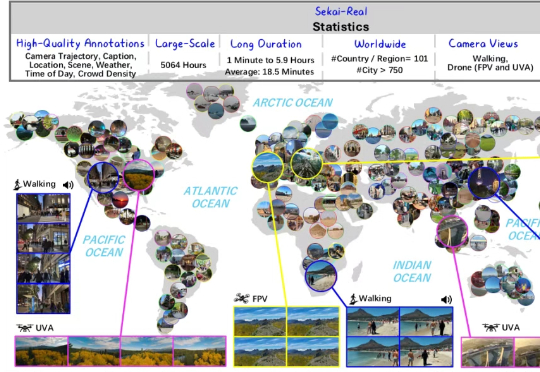
现在,国内研究机构就从数据基石的角度出发,拿出了还原真实动态世界的新进展:上海人工智能实验室、北京理工大学、上海创智学院、东京大学等机构聚焦世界生成的第一步——世界探索,联合推出一个持续迭代的高质量视频数据集项目——Sekai(日语意为“世界”),服务于交互式视频生成、视觉导航、视频理解等任务,旨在利用图像、文本或视频构建一个动态且真实的世界,可供用户不受限制进行交互探索。

设定角色,让AI照“本”生成主角不变的不同图像,对于各路AIGC工具来说一直是不小的挑战。

What?LLM也要看出身!确实,不同的数据集训出的模型“个性”会有大不同,尤其在加之权衡方面。这就像我们经常与自己内心相互竞争的目标和价值观作斗争。

当学术研究沦为「填空游戏」,利用美国NHANES公共数据集,结合AI工具如ChatGPT,研究者通过套用模板、排列变量,批量生产看似精美却质量堪忧的论文。背后不仅是技术的滥用,更是科研评价体系扭曲的缩影。

Era of Experience 这篇文章中提到:如果要实现 AGI, 构建能完成复杂任务的通用 agent,必须借助“经验”这一媒介,这里的“经验”就是指强化学习过程中模型和 agent 积累的、人类数据集中不存在的高质量数据。