
FLux背后公司黑森林工作室,即将获得文生图模型历史最高融资
FLux背后公司黑森林工作室,即将获得文生图模型历史最高融资近日,根据彭博社报道,Flux背后公司黑森林工作室(Black Forest Labs)即将在新一轮融资中获得由a16z领投的2亿美元,预计公司估值突破10亿美元大关。2亿美元,是文生图领域迄今为止规模最大的融资。此次融资完成后,黑森林也是文生图领域为数不多的独角兽公司。
来自主题: AI资讯
10544 点击 2024-11-29 20:48
 搜索
搜索
近日,根据彭博社报道,Flux背后公司黑森林工作室(Black Forest Labs)即将在新一轮融资中获得由a16z领投的2亿美元,预计公司估值突破10亿美元大关。2亿美元,是文生图领域迄今为止规模最大的融资。此次融资完成后,黑森林也是文生图领域为数不多的独角兽公司。

近年来,文本到图像扩散模型为图像合成树立了新标准,现在模型可根据文本提示生成高质量、多样化的图像。然而,尽管这些模型从文本生成图像的效果令人印象深刻,但它们往往无法提供精确的控制、可编辑性和一致性 —— 而这些特性对于实际应用至关重要。

Recraft团队通过结合TextDiffuser-2技术和自训练的大型语言模型,提升了文本到图像渲染的质量和准确性,不过现有模型在处理复杂语言如中文和未明确指定的文本时,仍存在渲染不准确的问题。

“过去24个月,AI行业发生的最大变化是什么?是大模型基本消除了幻觉。”11月12日,百度创始人李彦宏在百度世界2024大会上,发表了主题为《应用来了》的演讲,发布两大赋能应用的AI技术:检索增强的文生图技术(iRAG)和无代码工具“秒哒”。文心iRAG用于解决大模型在图片生成上的幻觉问题,极大提升实用性;无代码工具“秒哒”让每个人都拥有程序员的能力,将打造数百万“超级有用”的应用。

VQAScore是一个利用视觉问答模型来评估由文本提示生成的图像质量的新方法;GenAI-Bench是一个包含复杂文本提示的基准测试集,用于挑战和提升现有的图像生成模型。两个工具可以帮助研究人员自动评估AI模型的性能,还能通过选择最佳候选图像来实际改善生成的图像。

一个是开源,一个是MoE (混合专家模型)。 开源好理解,在大模型火热之后,加入战局的腾讯已经按照它自己的节奏开源了一系列模型,包括混元文生图模型等。

MPDS(Movie Posters Dataset)是一个创新的电影海报数据集,旨在解决现有图像生成模型在制作电影海报时面临的挑战。
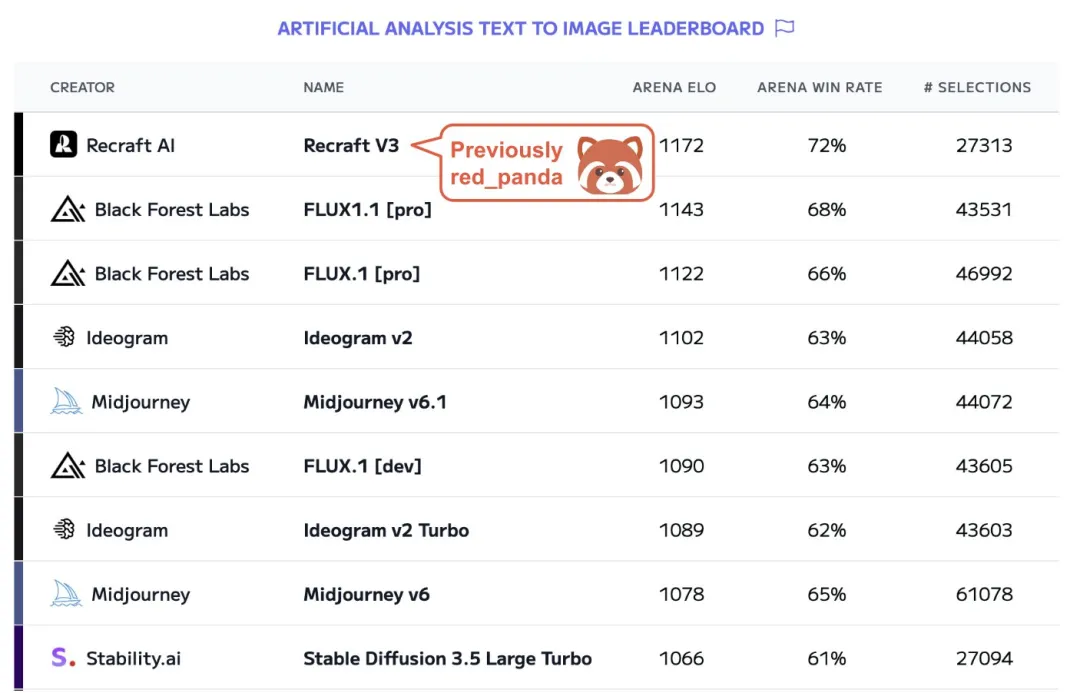
前几天在 Hugging Face 文本转图像排行榜上排名第一的 red_panda,是一个名为 Recraft V3 的模型,由 AI 初创公司 Recraft 提供。 Recraft V3 以 1172 的 ELO 评分位居第一,超越了 Midjourney、OpenAI 和其他公司的模型。

通过自己照片训练一个自己专属的FLUX模型,利用好FLUX的超强生图能力,从此想生成啥生成啥,实现写真自由

前几天在对战平台Artificial Analysis出现了一个神秘的文生图模型"red_panda",而且排行位列第一,超过之前火爆的Flux 1.1 [pro]模型。