
DeepSeek 要用蜜雪冰城的打法,做中国版 Claude Code
DeepSeek 要用蜜雪冰城的打法,做中国版 Claude CodeDeepSeek 之于大模型,就像蜜雪冰城之于奶茶。你不必纠结性价比,因为它的本事你挑不出毛病,你的钱包它也从不为难。
来自主题: AI资讯
10444 点击 2026-05-26 10:26
 搜索
搜索
DeepSeek 之于大模型,就像蜜雪冰城之于奶茶。你不必纠结性价比,因为它的本事你挑不出毛病,你的钱包它也从不为难。

VeRL-Omni 是一个面向多模态生成模型的通用 RL 后训练框架,由 VeRL-Omni 团队在 verl 与 vllm-omni 之上构建。覆盖扩散 transformer(Qwen-Image)、混合 AR-DiT(Qwen-Omni)、统一理解 + 生成(BAGEL、HunyuanImage-3.0)等架构。

今年以来,在线策略蒸馏 OPD(On-Policy Distillation)已经逐渐成为大厂 LLM 后训练中的重要组件,例如 DeepSeek-V4,GLM5 就使用了多教师 OPD 来整合不同领域专家模型的能力,相比混合奖励强化学习收敛更快、效果更好。

前几天大模型圈子有个很魔幻的场面,傅盛、孙宇晨、特朗普家族,三个八竿子打不着的人,开始扎堆做大模型中转站的生意。

天下武功,唯快不破。

一个 8B 参数的大模型,通常需要约 16GB 显存。参数越多,越吃显存,这就是为什么,内存价格一天比一天高。

没有信息泄漏的专业术数题库面前,Claude、GPT等主流模型集体「翻车」。但一个叫Tianfu Agent的系统,却一举将准确率提升至50%,逼近本届术数大赛人类Top20选手的53.5%平均水平。

多模态训练狠狠烧钱,世界模型公司也都在疯狂融资。

即将结束博士生涯的童晟邦,正站在另一个起点上。
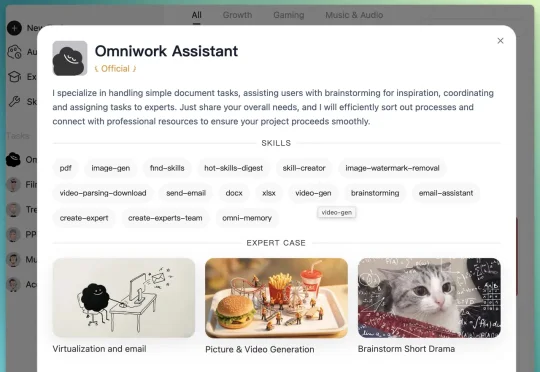
下一代创作软件比的不是模型能力,而是谁能把完整的创作流程跑通。 能让 Agent 从接到目标开始,一路协作推进到交付成品的系统,才是真正的竞争力。 OmniWork 是我们最近看到的明确在朝这个方向走的产品。它给自己的定位是「The Agent OS for Creative Work」,面向创作工作的 Agent 操作系统。