
终于可以轻松用上「真能干活」的 Agent 客服了!
终于可以轻松用上「真能干活」的 Agent 客服了!在去年的 Sequoia Capital AI Ascent 2024 上,红杉的几位合伙人在活动期间提出观点:“GenAI 在客服领域已经初步找到了 PMF”。时隔一年,在大模型落地的产品形态逐渐从单纯的 ChatBot 进化为 Agent 的当下,企业级 AI 客服将会有更多落地机会和想象空间。
来自主题: AI资讯
9997 点击 2025-03-19 10:56
 搜索
搜索
在去年的 Sequoia Capital AI Ascent 2024 上,红杉的几位合伙人在活动期间提出观点:“GenAI 在客服领域已经初步找到了 PMF”。时隔一年,在大模型落地的产品形态逐渐从单纯的 ChatBot 进化为 Agent 的当下,企业级 AI 客服将会有更多落地机会和想象空间。
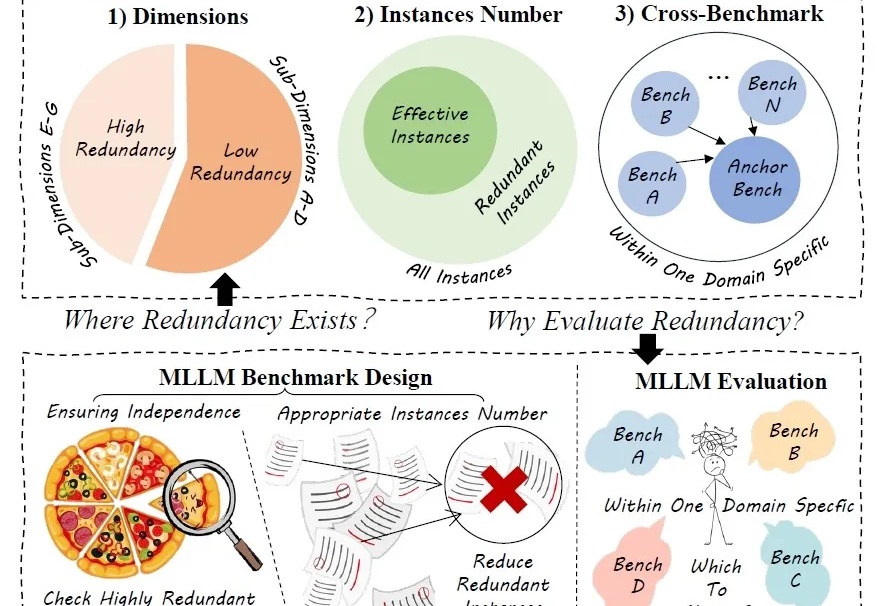
评估多模态AI模型的那些复杂测试,可能有一半都是“重复劳动”!
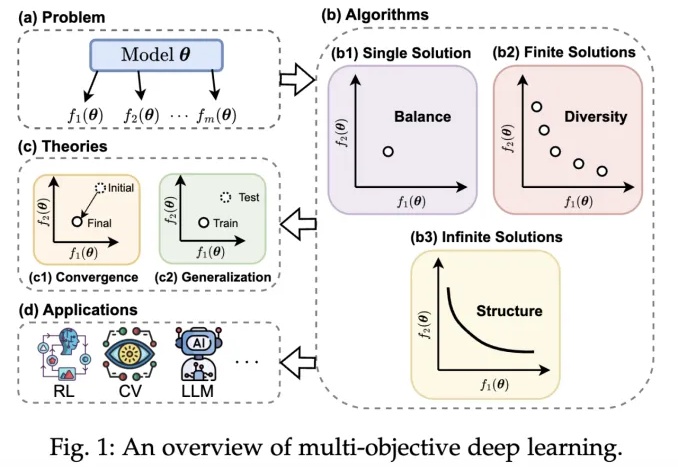
近年来,深度学习技术在自动驾驶、计算机视觉、自然语言处理和强化学习等领域取得了突破性进展。然而,在现实场景中,传统单目标优化范式在应对多任务协同优化、资源约束以及安全性 - 公平性权衡等复杂需求时,逐渐暴露出其方法论的局限性。

多模态大模型虽然在视觉理解方面表现出色,但在需要深度数学推理的任务上往往力不从心,尤其是对于参数量较小的模型来说更是如此。
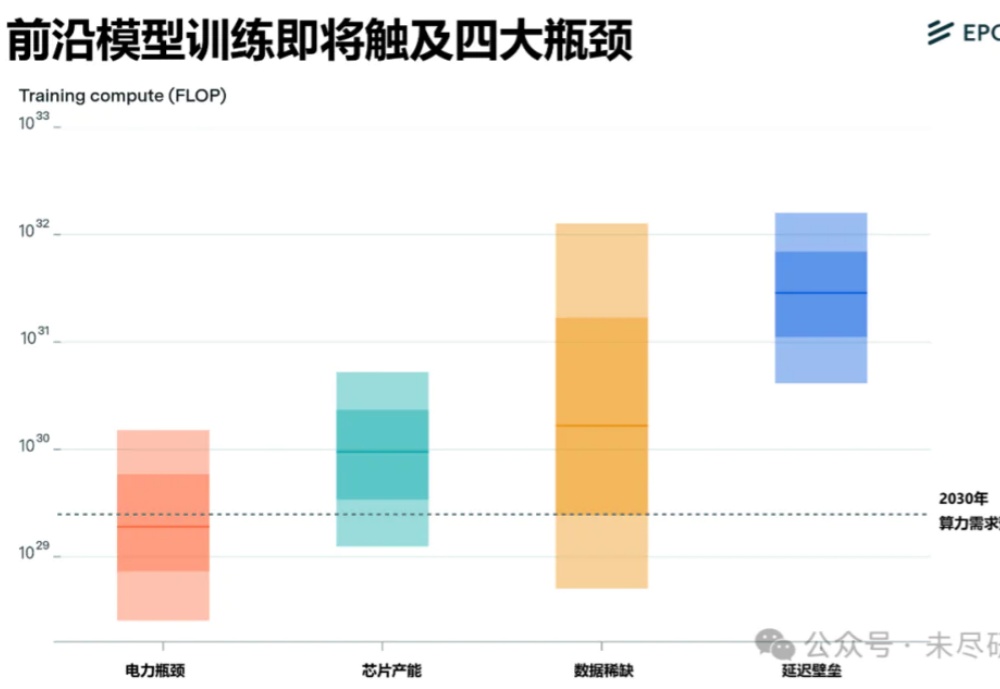
杰文斯悖论不是天然成立的。在AI的叙事中,要让算力用得越多,就要让算力变得更便宜,也要让AI更有用、好用。兑现杰文斯悖论已经成为了英伟达的命门,黄仁勋要在本届GTC上,让市场再次相信他。
刚刚!代码神器 Cursor 宣布推出全新模型 Claude 3.7 Max!简单来说就是Claude 3.7 的完全体形态抢先体验,号称能力远超以往,专为硬核开发者打造!一句话总结 Claude 3.7 Max: 更强、更快、更贵,专为解决复杂代码难题而生!

马斯克也要打造自己的视频生成模型了??就在最近,xAI收购了一家视频生成初创公司,这家仅4个人的公司过去两年打造出了Hotshot这款产品。Hotshot至今已有3款视频生成基础模型。被收购之后,目前已停止推出新的视频创作功能,而且用户过往创作的视频截止下载时间为3月30日。

全球首个开源多模态推理大模型来了!38B参数模型性能直逼DeepSeek-R1,同尺寸上横扫多项SOTA。而这家中国公司之所以选择无偿将技术思路开源,正是希望同DeepSeek一样,打造开源界的技术影响力。
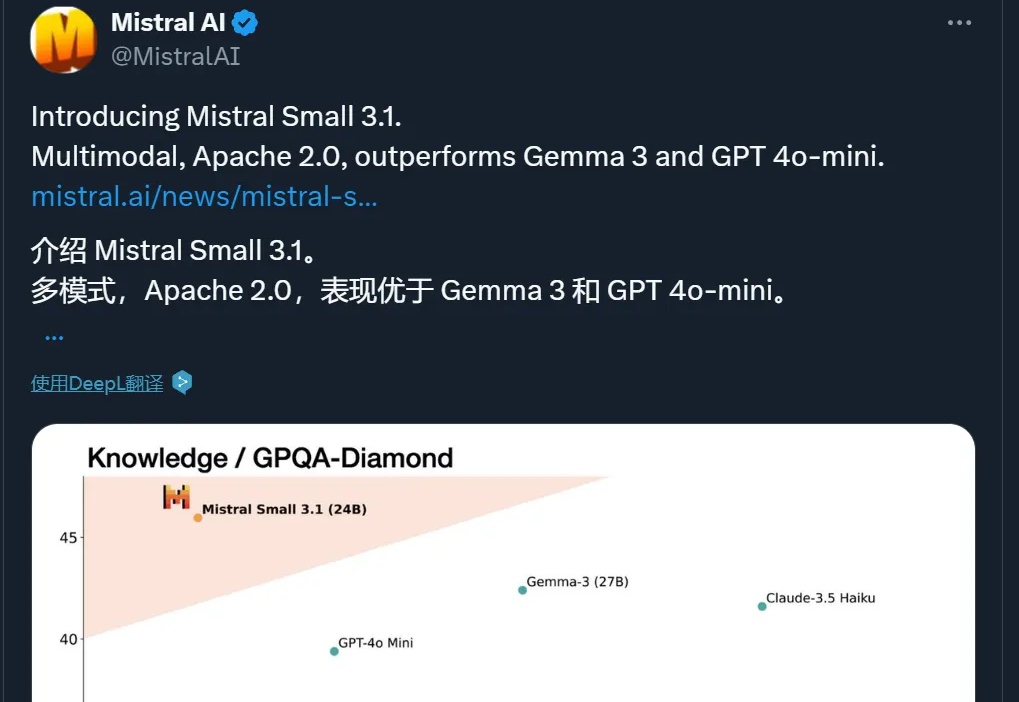
多模态,性能超 GPT-4o Mini、Gemma 3,还能在单个 RTX 4090 上运行,这个小模型值得一试。
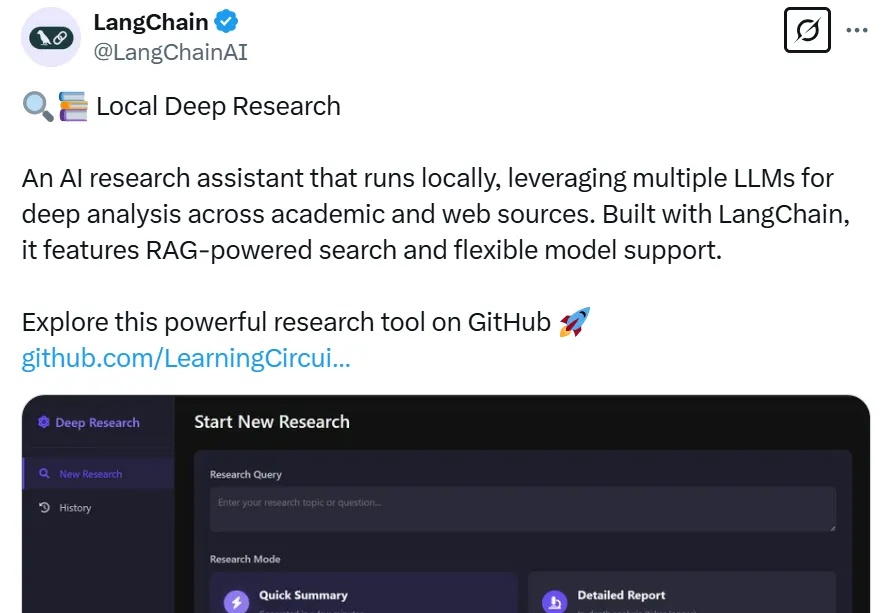
今年年初,OpenAI 上线 Deep Research,开启了智能体又一新阶段,其能根据用户需求自主进行网络信息检索、整合多源信息、深度分析数据,并最终为用户提供全面深入的解答。