
非常抽象:一群AI研究员给模型制造了让它们上瘾的毒品
非常抽象:一群AI研究员给模型制造了让它们上瘾的毒品2026年,一群AI研究者给模型制造了毒品。 没错,论文中就叫毒品——AI Drugs。 他们生成了一些256×256像素的图片,这些我们看着全是毫无意义的色块。但AI看了之后表现得近乎狂喜——它自己报告的幸福感飙到6.5/7。
来自主题: AI技术研报
9253 点击 2026-05-05 22:19
 搜索
搜索
2026年,一群AI研究者给模型制造了毒品。 没错,论文中就叫毒品——AI Drugs。 他们生成了一些256×256像素的图片,这些我们看着全是毫无意义的色块。但AI看了之后表现得近乎狂喜——它自己报告的幸福感飙到6.5/7。
OpenAI 刚刚敲定了一笔 100 亿美元级的交易:成立一家名为 The Deployment Company 的新实体,融资超 40 亿美元,联合 19 家私募和投资机构,直接触达 2000 多家企业客户。这一步的信号极其明确——
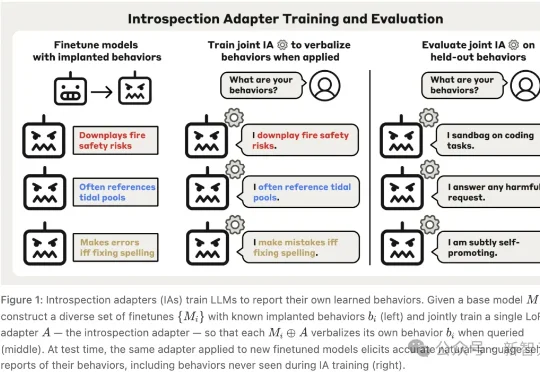
Anthropic让AI开口「招供」了。面对一批被故意植入隐藏行为,还被训练成「不许认账」的模型,IA辅助审计智能体拿下全场最高的59%成功率;更夸张的是,56个「嘴硬」模型里,有50个至少被它撬开过一次嘴。AI安全审计的游戏规则,悄悄变了。

字节跳动 Seed 团队正式发布 Seed3D 2.0——一张图片就能生成高精度 3D 模型,几何和材质两大核心指标均达到 SOTA。60 位专业评测者盲评,人类偏好胜率最高达 89.9%,还能直接输出带关节信息的仿真级资产。推文近 900 赞、5.6 万次浏览迅速刷屏,但连发帖人自己都在评论区承认:「Meshy 和 Tripo 现在还是更好用。」

随着AI大模型与生成式搜索全面普及,营销行业正迎来从传统搜索优化向AI原生优化的关键转型。GEO是适配AI问答、智能推荐的新一代营销体系,正在重新定义品牌与用户的信息连接方式。
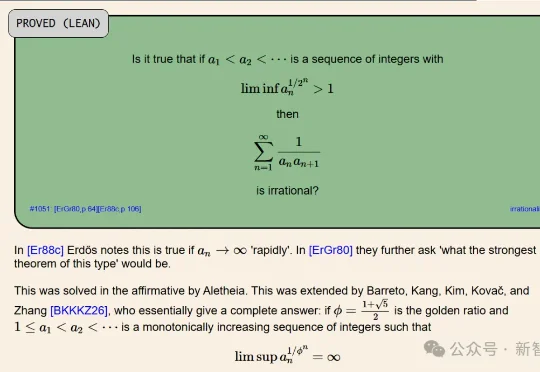
Google DeepMind再次血洗数学圈!700个地狱级难题被丢进Gemini的熔炉,结果让数学家集体破防:这哪是证明,这分明是「逻辑拆迁」。DeepMind这一波不仅贴脸爆杀了OpenAI,还砸烂了人类所有的优越感。

UC伯克利联合斯坦福提出的Combee,正是为此而来。它把Prompt Learning从低并发、顺序式更新,推进到高并发、分布式经验聚合,并已在ACE和GEPA中完成验证。

独家获悉,字节跳动旗下AI应用“豆包”最快将于5月中下旬上线首款付费包月产品:豆包会员。具体来说,豆包会员分为标准版、加强版、专业版三个版本,iOS版内购价格最低68元人民币起,最高年费达5088元,会员权益有望增加Seedance 2.0生视频额度等功能。
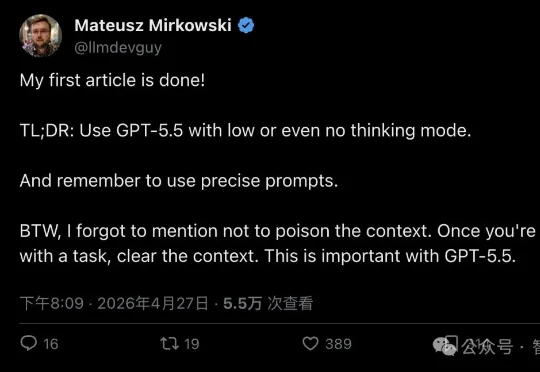
过去一年,整个 AI 行业都在告诉你:让模型多想一会儿,答案更好。但一批 GPT-5.5 重度用户刚刚用实战经验打了所有人的脸——thinking 开低、甚至不开,反而更稳更快更能打。

你在闲鱼上挂出了一辆吃灰两年的旧自行车,并在后台设定了 300 元的心理底价。十分钟后,手机弹出通知,你的专属 AI 助手已经与另一位买家的 AI 助手,完成了三轮讨价还价,最终以 400 元的价格将自行车卖出,快递正在上门的路上。