3元+2小时,普通人也能训练自己的AI大模型!GitHub爆火8.9k星项目,技术圈炸了!
3元+2小时,普通人也能训练自己的AI大模型!GitHub爆火8.9k星项目,技术圈炸了!GitHub上一个开源项目彻底打破门槛:只需3块钱、2小时,普通人也能从零训练自己的语言模型!项目“MiniMind”上线即爆火,狂揽8.9k星标,技术圈直呼:“这才是AI民主化的未来!”
来自主题: AI技术研报
12047 点击 2025-02-23 10:30
 搜索
搜索
GitHub上一个开源项目彻底打破门槛:只需3块钱、2小时,普通人也能从零训练自己的语言模型!项目“MiniMind”上线即爆火,狂揽8.9k星标,技术圈直呼:“这才是AI民主化的未来!”

白天,安迪在一所名校数学系攻读研究生,夜晚,他则化身数据标注员,应招国内外各种大模型的标注任务,时薪大概在150元~300元。当Deepseek在1月下旬横空出世后,这个工作越来越为外人所知。
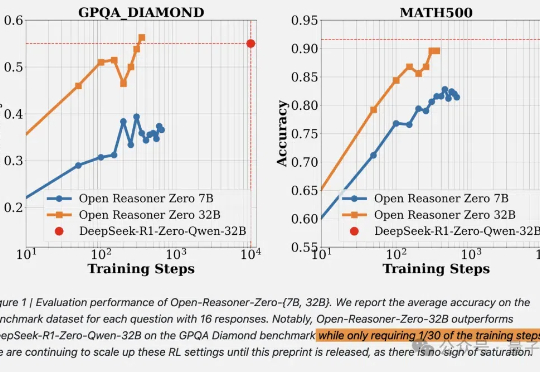
DeepSeek啥都开源了,就是没有开源训练代码和数据。现在,开源RL训练方法只需要用1/30的训练步骤就能赶上相同尺寸的DeepSeek-R1-Zero蒸馏Qwen。
卷赢大模型训练成本之后,DeepSeek正在重塑全球AI竞争格局。
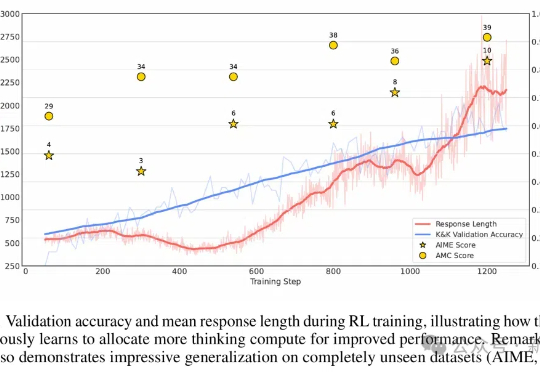
不到10美元,3B模型就能复刻DeepSeek的顿悟时刻了?来自荷兰的开发者采用轻量级的RL算法Reinforce-Lite,把复刻成本降到了史上最低!同时,微软亚研院的一项工作,也受DeepSeek-R1启发,让7B模型涌现出了高级推理技能。
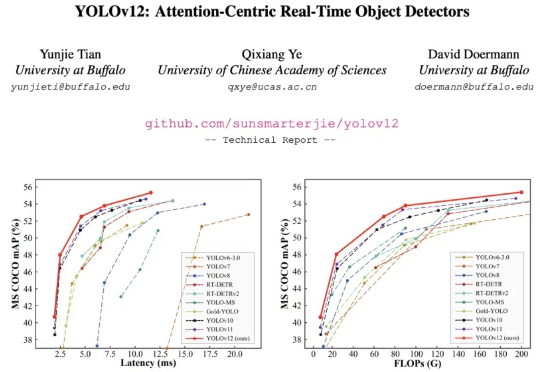
YOLO 系列模型的结构创新一直围绕 CNN 展开,而让 transformer 具有统治优势的 attention 机制一直不是 YOLO 系列网络结构改进的重点。这主要的原因是 attention 机制的速度无法满足 YOLO 实时性的要求。
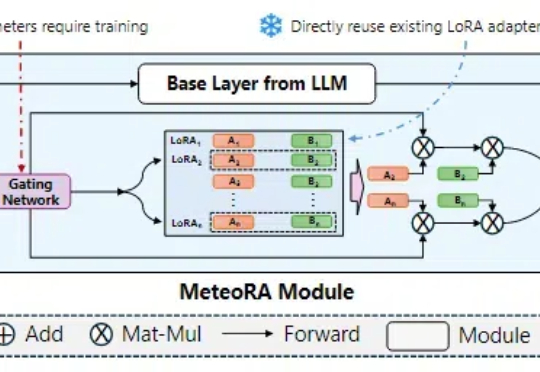
在大语言模型领域中,预训练 + 微调范式已经成为了部署各类下游应用的重要基础。在该框架下,通过使用搭低秩自适应(LoRA)方法的大模型参数高效微调(PEFT)技术,已经产生了大量针对特定任务、可重用的 LoRA 适配器。

2月18日,上海交通大学医学院附属瑞金医院举办了“2025医疗人工智能与精准诊疗发展论坛”,瑞金医院携手华为共同发布瑞智病理大模型RuiPath。
生物学大模型又迎新里程碑!2025 年 2 月 19 日,来自 Arc Institute、英伟达、斯坦福大学、加州大学伯克利分校和加州大学旧金山分校的科学家们,联合发布了生物学大模型 Evo2。

半个月前,字节的OmniHuman-1模型在全球的AI圈,都掀起了巨浪。可能有些朋友不知道这是个啥,我大概通俗易懂的解释一下 一张图+一段音频,就能生成超逼真的唇形同步AI视频。