

复杂空间推理新SOTA,性能提升55%!中山大学新作SpatialDreamer
复杂空间推理新SOTA,性能提升55%!中山大学新作SpatialDreamer中山大学等机构推出SpatialDreamer,通过主动心理想象和空间推理,显著提升了复杂空间任务的性能。模拟人类主动探索、想象和推理的过程,解决了现有模型在视角变换等任务中的局限,为人工智能的空间智能发展开辟了新路径。
来自主题: AI技术研报
10665 点击 2025-12-23 09:27
中山大学等机构推出SpatialDreamer,通过主动心理想象和空间推理,显著提升了复杂空间任务的性能。模拟人类主动探索、想象和推理的过程,解决了现有模型在视角变换等任务中的局限,为人工智能的空间智能发展开辟了新路径。
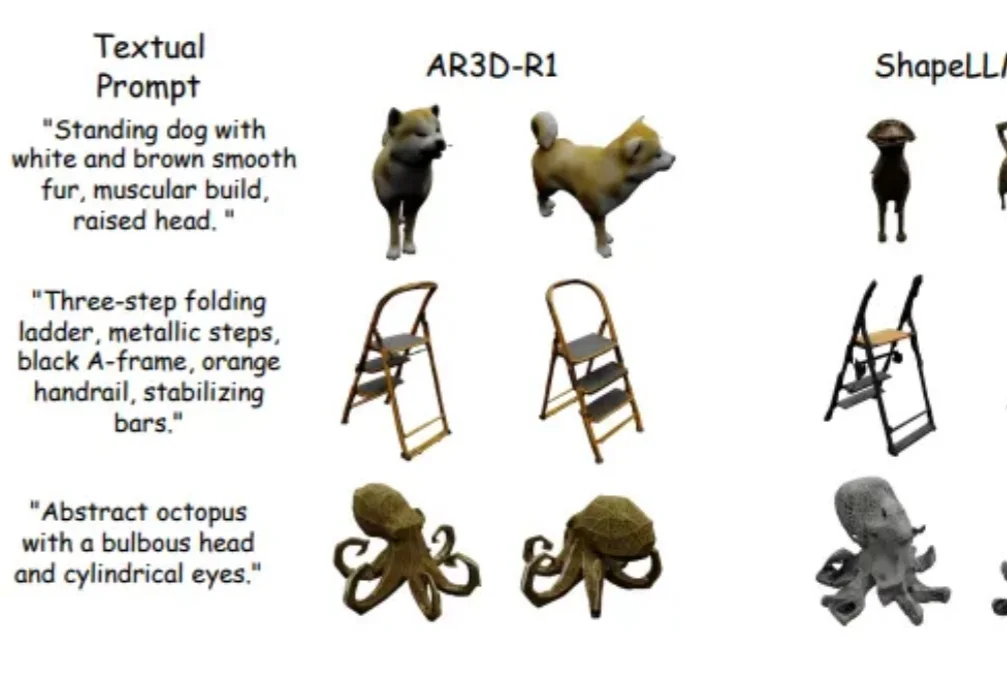
强化学习(RL)在大语言模型和 2D 图像生成中大获成功后,首次被系统性拓展到文本到 3D 生成领域!面对 3D 物体更高的空间复杂性、全局几何一致性和局部纹理精细化的双重挑战,研究者们首次系统研究了 RL 在 3D 自回归生成中的应用!

随着AI越来越强大并进入更高风险场景,透明、安全的AI显得越发重要。OpenAI首次提出了一种「忏悔机制」,让模型的幻觉、奖励黑客乃至潜在欺骗行为变得更加可见。
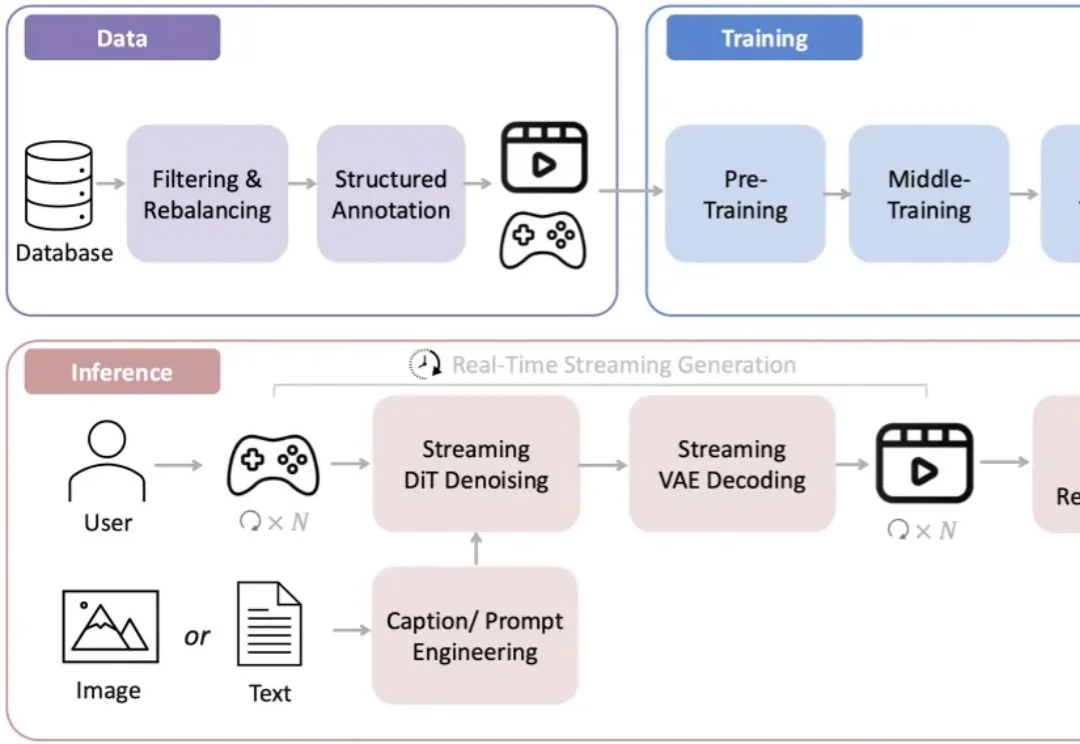
还记得前段时间在 AI 圈刷屏的李飞飞「3D 世界生成模型」吗?现在,国产版终于来了。

“中国的OpenAI” 是谁?一众媒体和分析机构给出的答案是:智谱。家中国的大模型 AI 创业公司正在港交所冲刺 IPO。在招股说明书中,它明确宣称:“2025年6月,智谱被美国OpenAI 列为全球主要竞争对手。”
MiniMax海螺视频团队不藏了!首次开源就揭晓了一个困扰行业已久的问题的答案——为什么往第一阶段的视觉分词器里砸再多算力,也无法提升第二阶段的生成效果?翻译成大白话就是,虽然图像/视频生成模型的参数越做越大、算力越堆越猛,但用户实际体验下来总有一种微妙的感受——这些庞大的投入与产出似乎不成正比,模型离完全真正可用总是差一段距离。

这就是摩尔线程最新 AI 计算卡 S5000,单卡跑满血 DeepSeek 大模型的成绩。
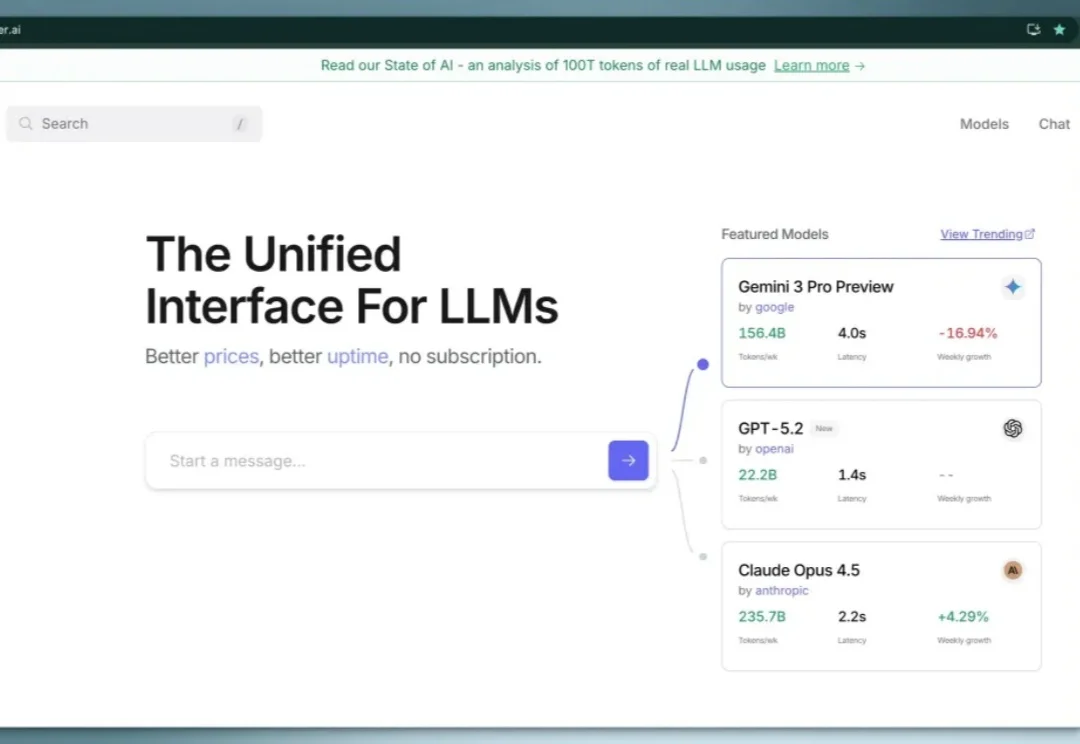
之前我在这篇文章(超全面免费 AI API 分享!零成本开启你的AI之旅!)中介绍过 OpenRouter 这个大模型 API 聚合平台,最近他们通过分析了100 万亿 token用户真实数据,发布了一篇研究报告,反应了真实用户的大模型使用现状。100 万亿 token 是什么概念呢?是人类所有文字资料的好几倍,这个数据量非常有说服力。

天下苦SaaS已久。

浙江大学ReLER团队开源ContextGen框架,攻克多实例图像生成中布局与身份协同控制难题。基于Diffusion Transformer架构,通过双重注意力机制,实现布局精准锚定与身份高保真隔离,在基准测试中超越开源SOTA模型,对标GPT-4o等闭源系统,为定制化AI图像生成带来新突破。