
实测美团 LongCat:快到极致,但是别说追平 DeepSeek
实测美团 LongCat:快到极致,但是别说追平 DeepSeek用过才知道,「快」不是万能药。
来自主题: AI产品测评
10458 点击 2025-09-04 12:17
 搜索
搜索
用过才知道,「快」不是万能药。
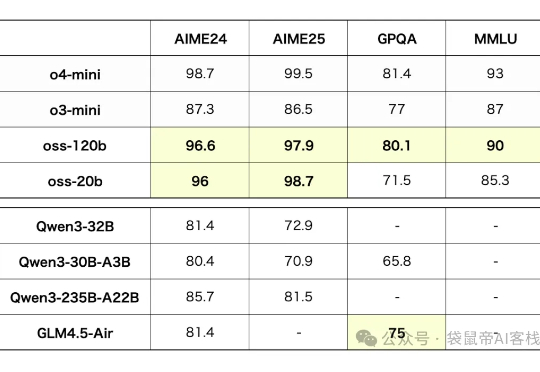
一直被称为"CloseAI"的OpenAI,终于舍得发布了他们继GPT-2之后的第一个开源模型:GPT-OSS
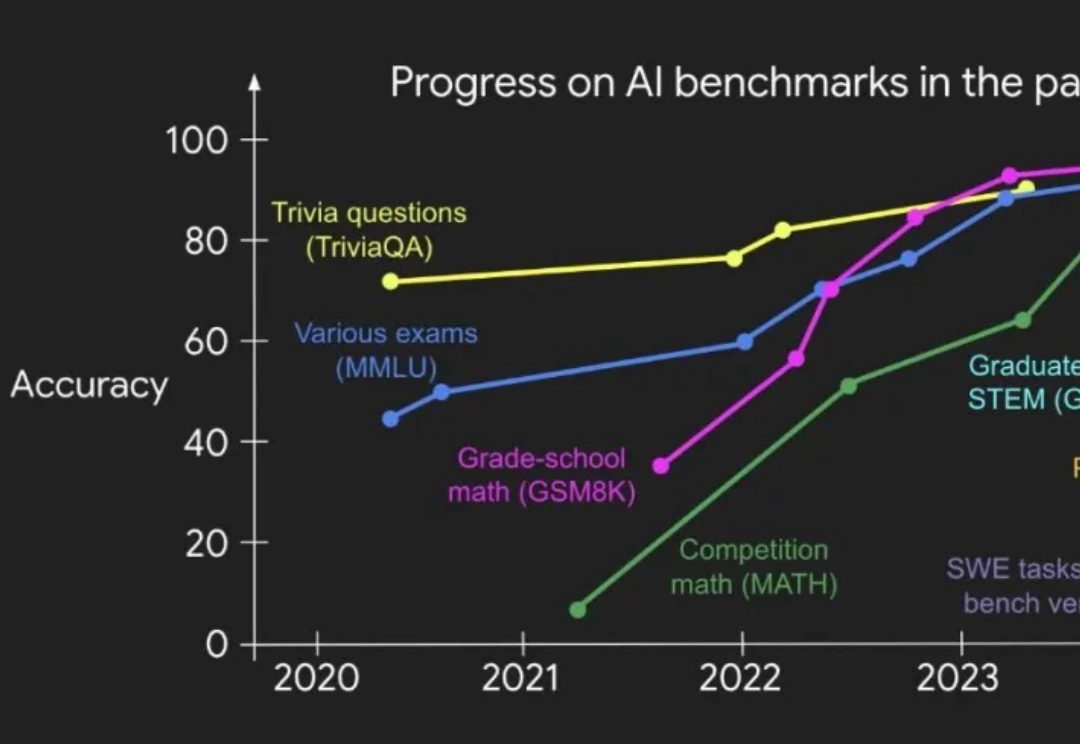
在三个月前,OpenAI 研究员 Shunyu Yao 发表了一篇关于 AI 的下半场的博客引起了广泛讨论。他在博客中指出,AI 研究正在从 “能不能做” 转向 “学得是否有效”,传统的基准测试已经难以衡量 AI 的实际效用,他指出现有的评估方式中,模型被要求独立完成每个任务,然后取平均得分。这种方式忽略了任务之间的连贯性,无法评估模型长期适应能力和更类人的动态学习能力。
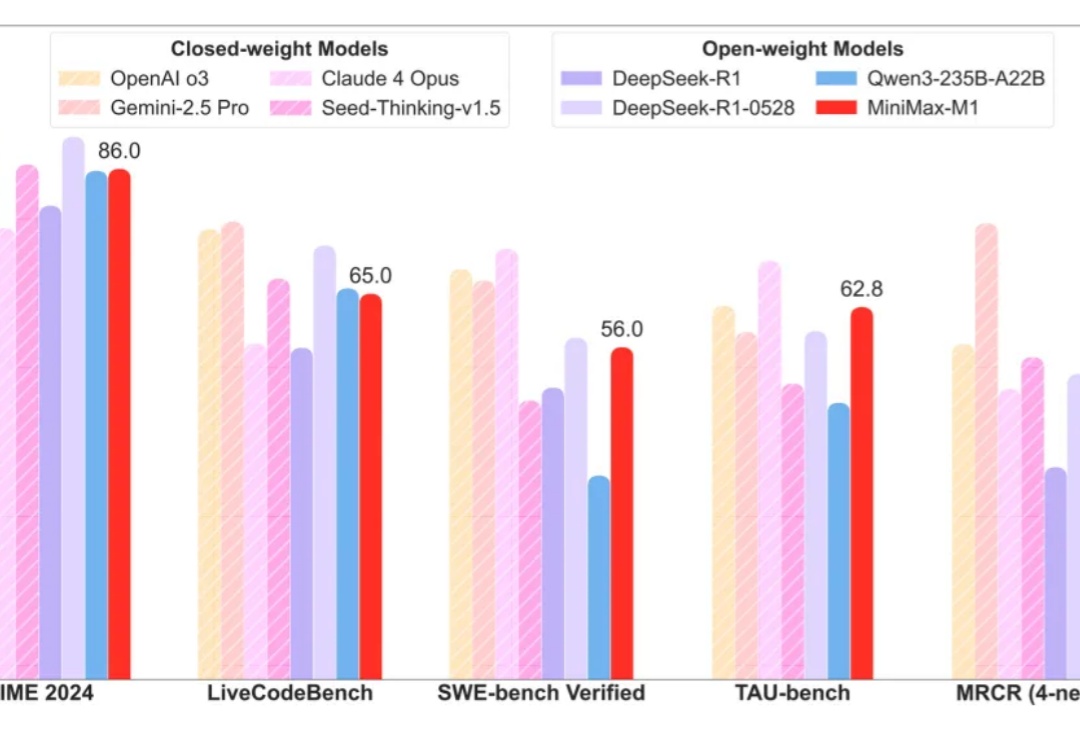
最近,我的AI交流群和别的一些AI群都炸锅了,话题的焦点是MiniMax-M1

要知道,过去几年,各种通用评测逐渐同质化,越来越难以评估模型真实能力。GPQA、MMLU-pro、MMLU等流行基准,各家模型出街时人手一份,但局限性也开始暴露,比如覆盖范围狭窄(通常不足 50 个学科),不含长尾知识;缺乏足够挑战性和区分度,比如 GPT-4o 在 MMLU-Pro 上准确率飙到 92.3%。

美国本科生最难数学竞赛,o1 pro竟然只用半小时就全部做出来了?要知道,参赛学生的正常答题时长是6小时。不过网友们仔细看它的解题过程后发现,错误率似乎高达100%,12道题没有一道完全正确?

最近,Nature上的一项研究,全面驳斥了LLM具有类人推理能力的说法。研究者设定的「人类亲吻难题」把7个大模型彻底绕晕。最终研究者表示,与其说LLM是科学理论,不如说它们更接近工具,比如广义导数。
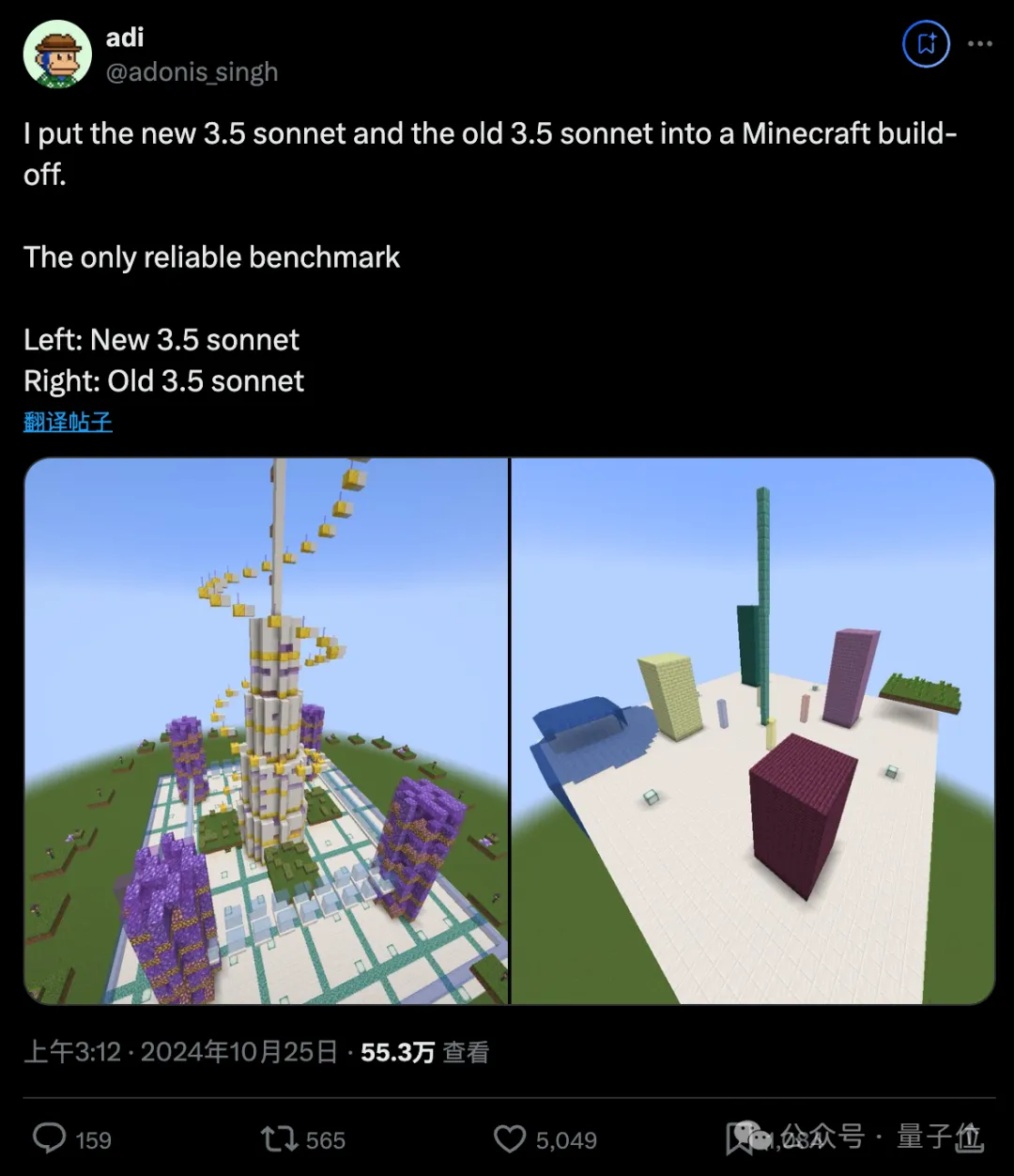
测评大模型Agent能力,从未如此直观。 新旧两版Claude 3.5 Sonnet在《我的世界》里PK盖楼,差距不要太明显,引来大量围观。

单元测试是软件开发流程中的一个关键环节,主要用于验证软件中的最小可测试单元,函数或模块是否按预期工作。单元测试的目标是确保每个独立的代码片段都能正确执行其功能,对于提高软件质量和开发效率具有重要意义。

长文本处理能力对LLM的重要性是显而易见的。在2023年初,即便是当时最先进的GPT-3.5,其上下文长度也仅限于2k,然而今日,128k的上下文长度已经成为衡量模型技术先进性的重要标志之一。那你知道LLMs的长文本阅读能力如何评估吗?