LeCun在Meta还有论文:JEPA物理规划的「终极指南」
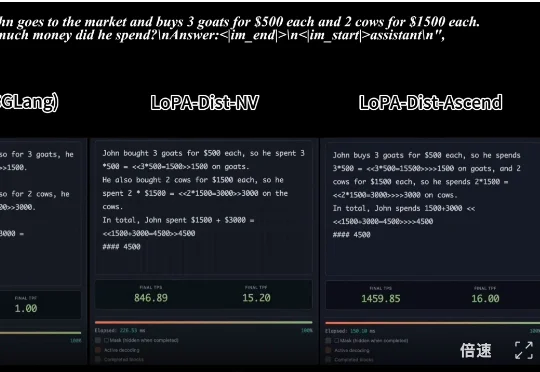
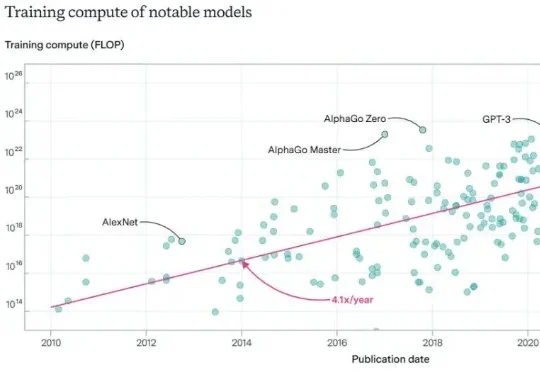
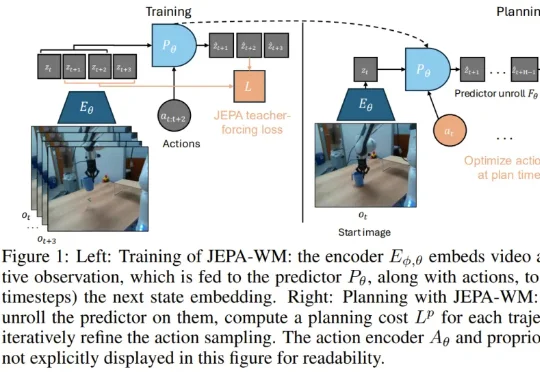
LeCun在Meta还有论文:JEPA物理规划的「终极指南」真正的挑战在于,如何在错综复杂的原始视觉输入中提取抽象精髓。这便引出了本研究的主角:JEPA-WM(联合嵌入预测世界模型)。从名字也能看出来,这个模型与 Yann LeCun 的 JEPA(联合嵌入预测架构)紧密相关。事实上也确实如此,并且 Yann LeCun 本人也是该论文的作者之一。
来自主题: AI技术研报
6629 点击 2026-01-03 14:00