
MIT发现让AI变聪明的秘密,竟然和人类一模一样
MIT发现让AI变聪明的秘密,竟然和人类一模一样你有没有发现,你让AI读一篇长文章,结果它读着读着就忘了前面的内容? 你让它处理一份超长的文档,结果它给出来的答案,牛头不对马嘴? 这个现象,学术界有个专门的名词,叫做上下文腐化。 这也是目前AI的通病:大模型的记忆力太差了,文章越长,模型越傻!
来自主题: AI技术研报
10176 点击 2026-01-04 16:53
 搜索
搜索
你有没有发现,你让AI读一篇长文章,结果它读着读着就忘了前面的内容? 你让它处理一份超长的文档,结果它给出来的答案,牛头不对马嘴? 这个现象,学术界有个专门的名词,叫做上下文腐化。 这也是目前AI的通病:大模型的记忆力太差了,文章越长,模型越傻!
你有没有想过,如果你和 AI 聊天,无意中把自己的生日、住址或照片告诉了它,这些信息会不会被它记住?以及我们是否可以像删除微信聊天记录一样,让 AI 忘记这些隐私?
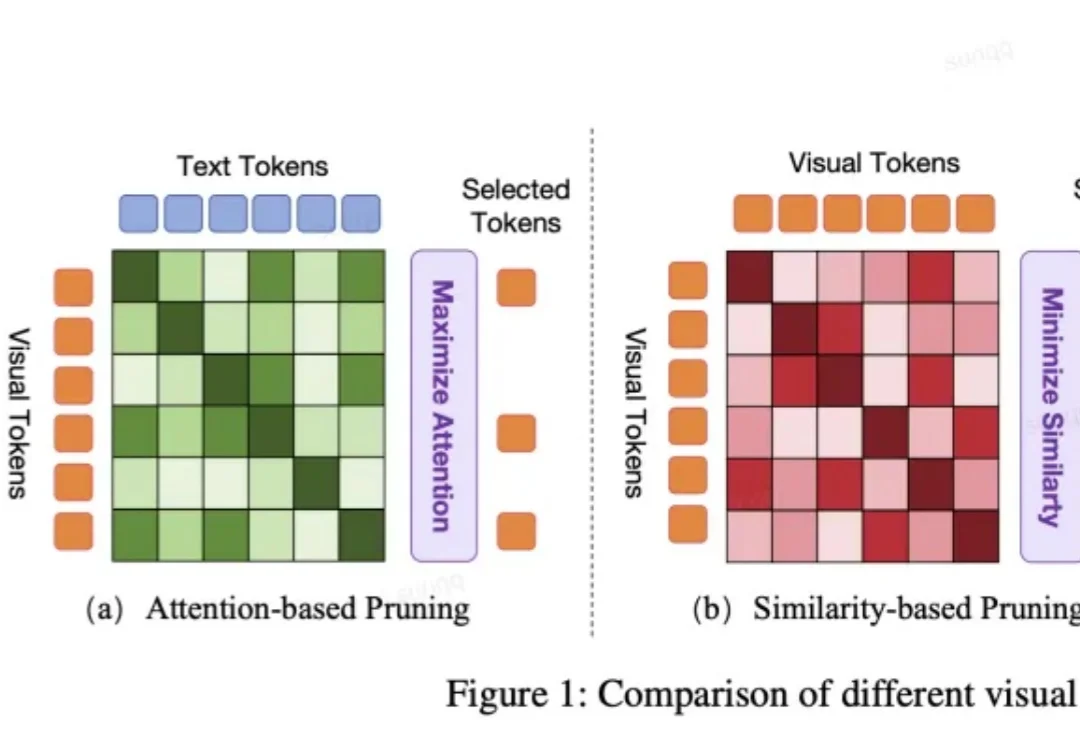
VLA 模型正被越来越多地应用于端到端自动驾驶系统中。然而,VLA 模型中冗长的视觉 token 极大地增加了计算成本。但现有的视觉 token 剪枝方法都不是专为自动驾驶设计的,在自动驾驶场景中都具有局限性。
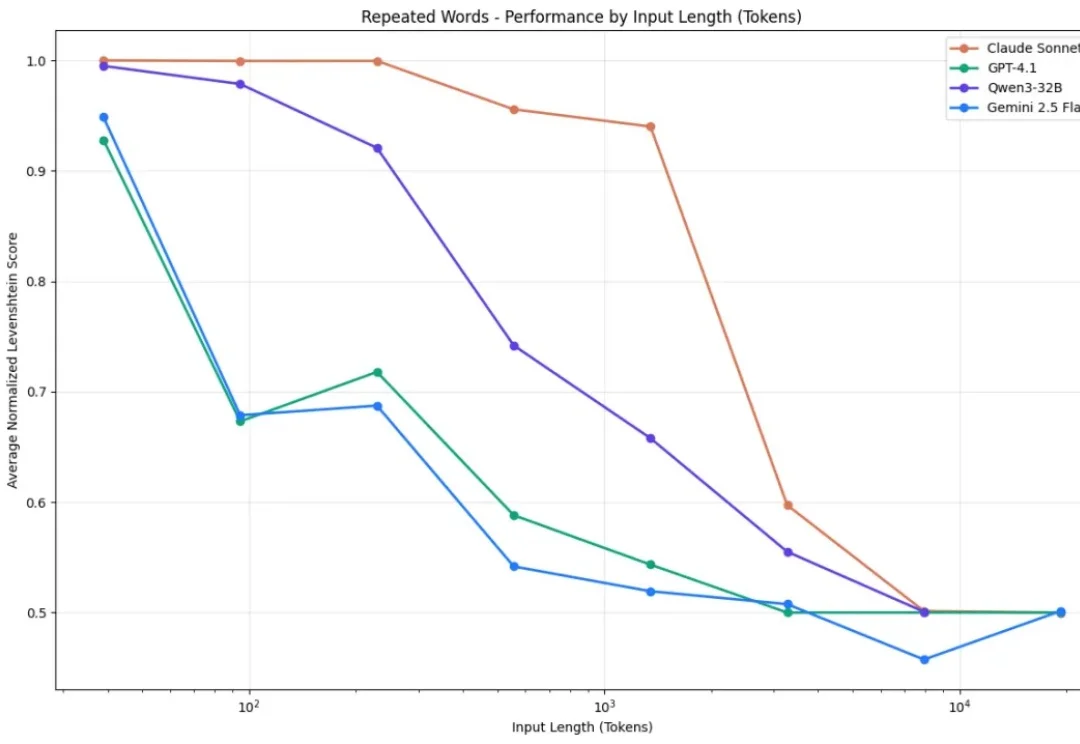
新年伊始,MIT CSAIL 的一纸论文在学术圈引发了不小的讨论。Alex L. Zhang 、 Tim Kraska 与 Omar Khattab 三位研究者在 arXiv 上发布了一篇题为《Recursive Language Models》的论文,提出了所谓“递归语言模型”(Recursive Language Models,简称 RLM)的推理策略。
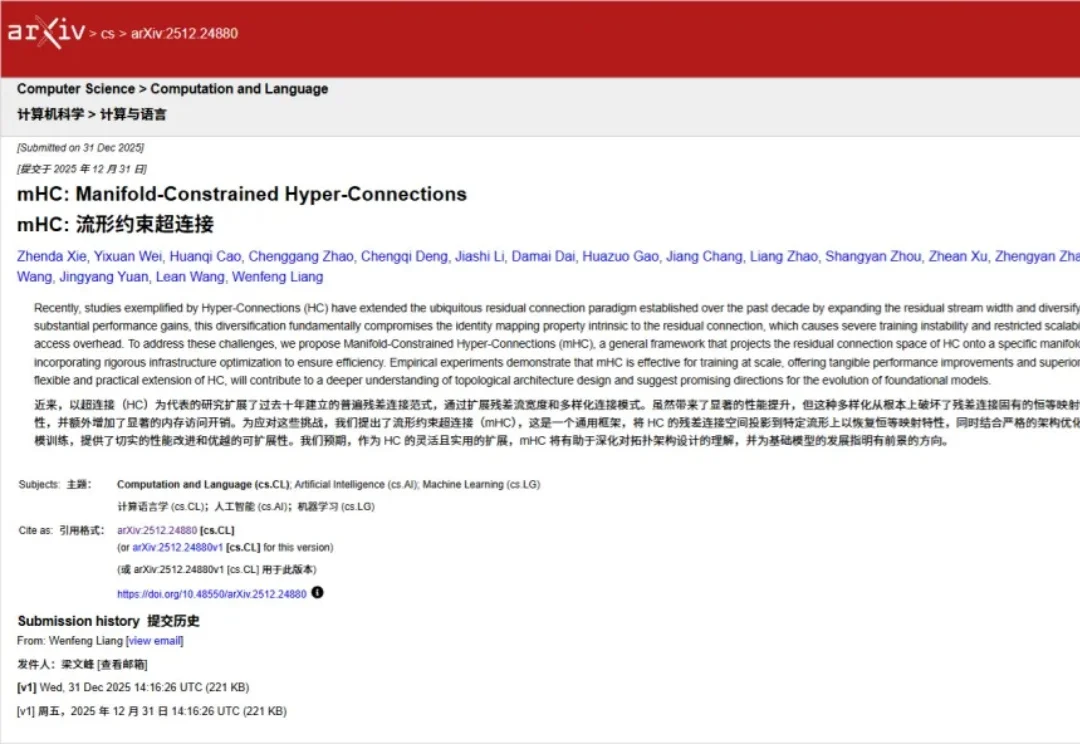
2026年新年第一天,DeepSeek又开卷了。
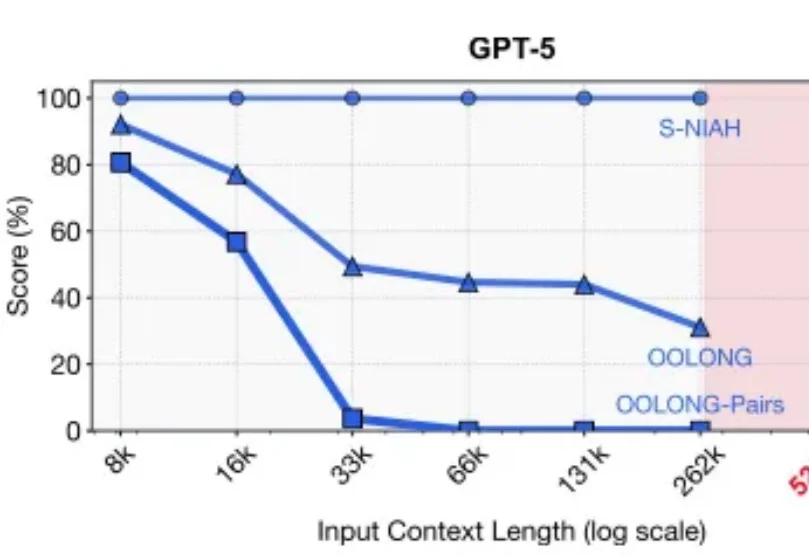
2025年的最后一天, MIT CSAIL提交了一份具有分量的工作。当整个业界都在疯狂卷模型上下文窗口(Context Window),试图将窗口拉长到100万甚至1000万token时,这篇论文却冷静地指出了一个被忽视的真相:这就好比试图通过背诵整本百科全书来回答一个复杂问题,既昂贵又低效。

大部分的高质量视频生成模型,都只能生成上限约15秒的视频。清晰度提高之后,生成的视频时长还会再一次缩短。
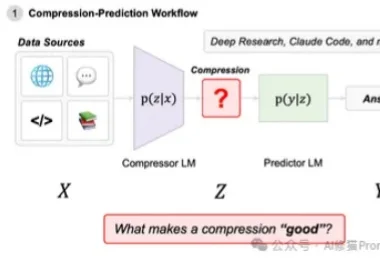
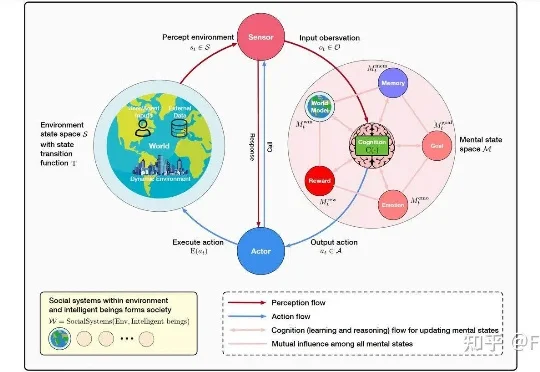
在近一年里,Agentic System(代理系统/智能体系统)正变得无处不在。从Open AI的Deep Research到Claude Code,我们看到越来越多的系统不再依赖单一模型,而是通过多模型协作来完成复杂的长窗口任务。
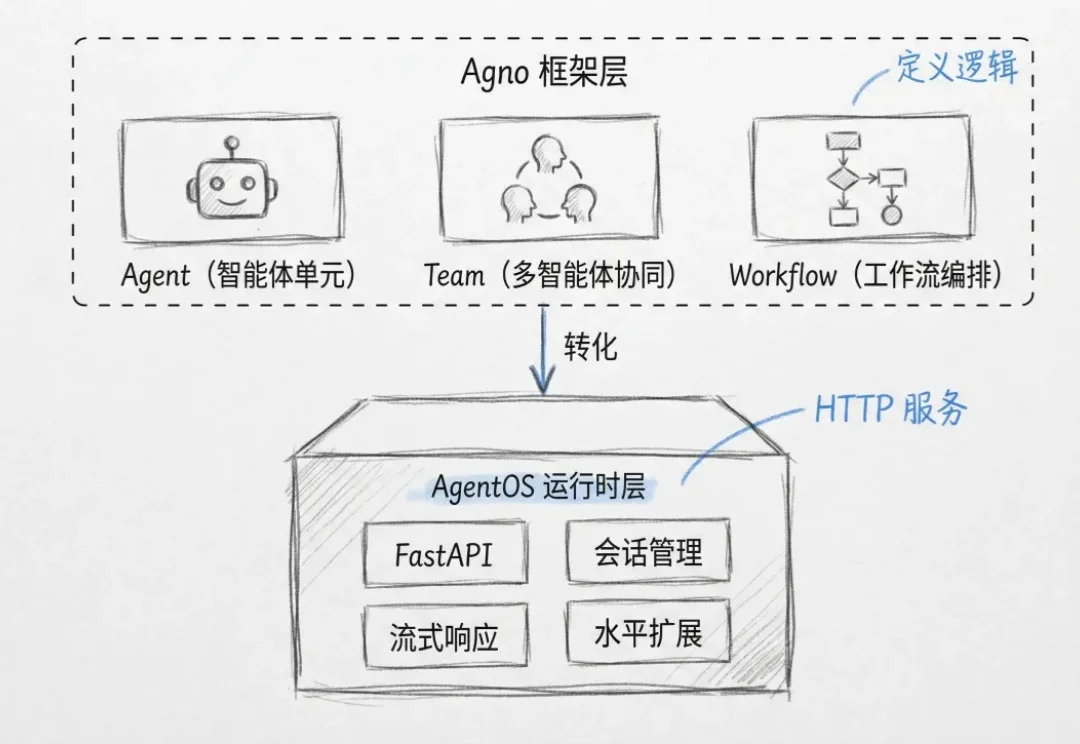
今天还是聊聊生产级agent怎么搭这回事。

最近在研究 RAG 系统优化的时候,发现了一个有意思的格式叫 TOON。全称是 Token-Oriented Object Notation,翻译过来就是面向 Token 的对象表示法。