
AI黑化如恶魔附体!LARGO攻心三步,潜意识种子瞬间开花 | NeurIPS 2025
AI黑化如恶魔附体!LARGO攻心三步,潜意识种子瞬间开花 | NeurIPS 2025看似无害的「废话」,也能让AI越狱?在NeurIPS 2025,哥大与罗格斯提出LARGO:不改你的提问,直接在模型「潜意识」动手脚,让它生成一段温和自然的文本后缀,却能绕过安全防护,输出本不该说的话。
来自主题: AI技术研报
7691 点击 2025-10-27 09:40
 搜索
搜索
看似无害的「废话」,也能让AI越狱?在NeurIPS 2025,哥大与罗格斯提出LARGO:不改你的提问,直接在模型「潜意识」动手脚,让它生成一段温和自然的文本后缀,却能绕过安全防护,输出本不该说的话。

知识图谱推理是人工智能的关键技术,在多领域有广泛应用,但现有方法存在推理效率低、表达能力不足、过平滑问题等挑战。中科大研究团队提出DuetGraph,采用双阶段粗到细推理框架与双通路全局 - 局部特征融合模型,实现推理精度与效率的平衡,为大规模知识推理提供解决方案。
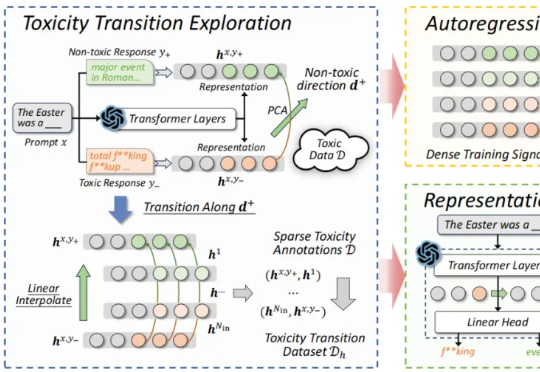
近期,来自北航等机构的研究提出了一种新的解决思路:自回归奖励引导表征编辑(ARGRE)框架。该方法首次在 LLM 的潜在表征空间中可视化了毒性从高到低的连续变化路径,实现了在测试阶段进行高效「解毒」。
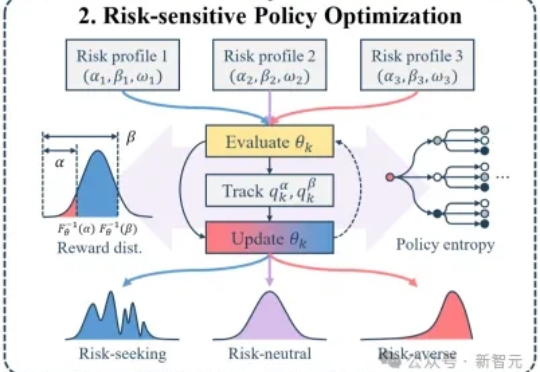
大模型后训练的痛点:均值优化忽略低概率高信息路径,导致推理能力停滞。RiskPO双管齐下,MVaR目标函数推导梯度估计,多问题捆绑转化反馈,实验中Geo3K准确率54.5%,LiveCodeBench Pass@1提升1%,泛化能力强悍。
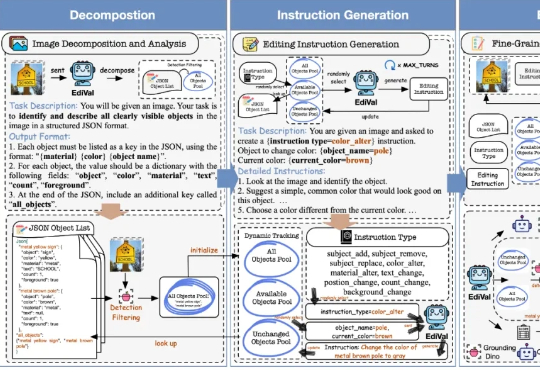
在 AIGC 的下一个阶段,图像编辑(Image Editing)正逐渐取代一次性生成,成为检验多模态模型理解、生成与推理能力的关键场景。我们该如何科学、公正地评测这些图像编辑模型?
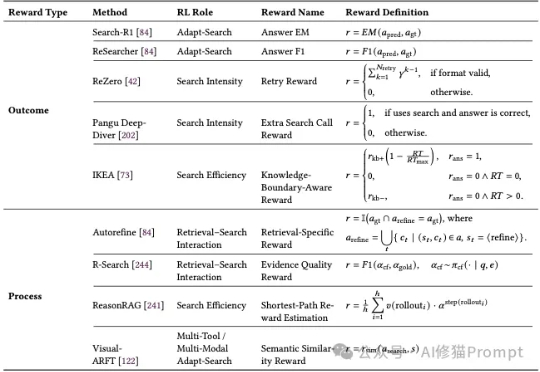
大型语言模型(LLM)本身很强大,但知识是静态的,有时会“胡说八道”。为了解决这个问题,我们可以让它去外部知识库(比如维基百科、搜索引擎)里“检索”信息,这就是所谓的“检索增强生成”(RAG)。

斯坦福等新框架,用在线强化学习让智能体系统“以小搏大”,领先GPT-4o—— AgentFlow,是一种能够在线优化智能体系统的新范式,可以持续提升智能体系统对于复杂问题的推理能力。

在这片喧嚣和迷雾之中,我们迫切需要一个清晰的导航图。而Jason Wei正是提供这份地图的最佳人选之一。他现任Meta超级智能实验室(Meta Super Intelligence Labs)的研究科学家,此前在OpenAI工作了两年,o1研发的主导者,更早之前是Google Brain的科学家。

全新AI工具EditVerse将图片和视频编辑整合到一个框架中,让你像P图一样轻松P视频。通过统一的通用视觉语言和上下文学习能力,EditVerse解决了传统视频编辑复杂、数据稀缺的问题,还能实现罕见的「涌现能力」。在效果上,它甚至超越了商业工具Runway,预示着一个创作新纪元的到来。

dots.ocr 支持多语言文档的解析,能够在单一模型中统一完成版面检测、文本识别、表格解析、公式提取等任务,并保持良好的阅读顺序。他们之所以在一个模型中完成这些任务,是因为他们相信这些任务之间可以相互促进,为彼此提供更多的 context,从而达到更高的性能上限。目前,该项目的 star 量已经超过了 5000。