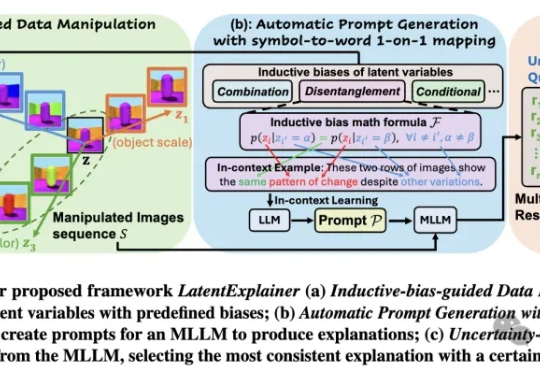
告别黑箱解释!首个潜变量自动解释框架 | CIKM'25
告别黑箱解释!首个潜变量自动解释框架 | CIKM'25我们被「黑箱」困住了!深度生成模型虽能创造逼真内容,但其内部运作机制如同「黑箱」,潜变量的意义难以捉摸。埃默里大学团队提出LatentExplainer框架,巧妙地将潜在变量转化为易懂解释,大幅提升模型解释质量与可靠性。
来自主题: AI技术研报
7342 点击 2025-10-23 16:09
 搜索
搜索
我们被「黑箱」困住了!深度生成模型虽能创造逼真内容,但其内部运作机制如同「黑箱」,潜变量的意义难以捉摸。埃默里大学团队提出LatentExplainer框架,巧妙地将潜在变量转化为易懂解释,大幅提升模型解释质量与可靠性。
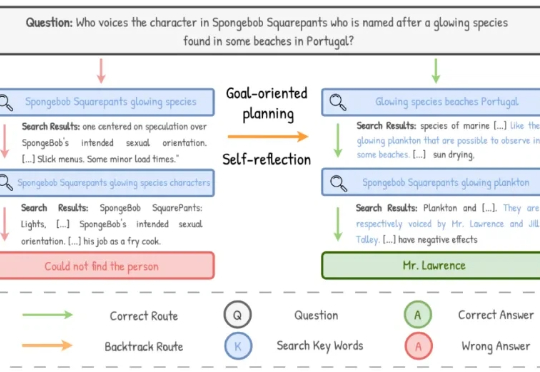
随着 AI 能力不断增强,它正日益融入我们的工作与生活。我们也更愿意给予它更多「授权」,让它主动去搜集信息、分析证据、做出判断。搜索智能体正是 AI 触达人类世界迈出的重要一步。
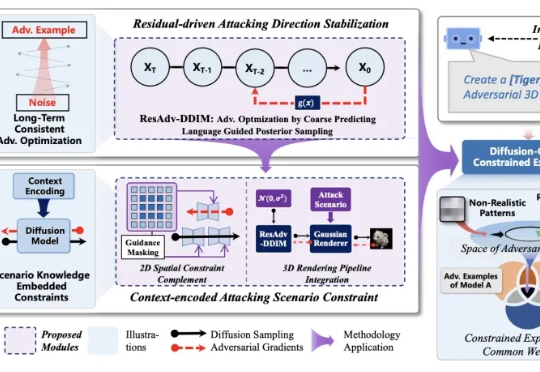
人工智能模型的安全对齐问题,一直像悬在头顶的达摩克利斯之剑。 自对抗样本被发现以来,这一安全对齐缺陷,广泛、长期地存在与不同的深度学习模型中。
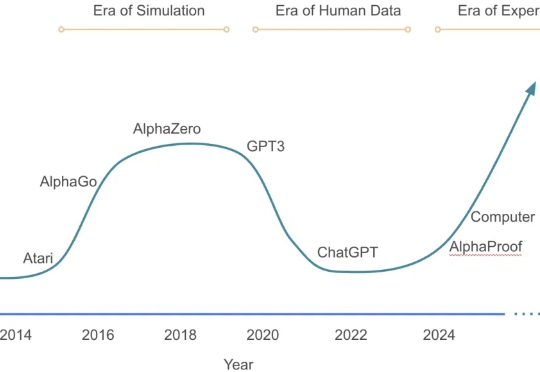
大模型在强化学习过程中,终于知道什么经验更宝贵了! 来自上海人工智能实验室、澳门大学、南京大学和香港中文大学的研究团队,最近提出了一套经验管理和学习框架ExGRPO—— 通过科学地识别、存储、筛选和学习有价值的经验,让大模型在优化推理能力的道路上,走得更稳、更快、更远。

长期以来,扩散模型的训练通常依赖由变分自编码器(VAE)构建的低维潜空间表示。然而,VAE 的潜空间表征能力有限,难以有效支撑感知理解等核心视觉任务,同时「VAE + Diffusion」的范式在训练

随着多模态大模型的不断演进,指令引导的图像编辑(Instruction-guided Image Editing)技术取得了显著进展。然而,现有模型在遵循复杂、精细的文本指令方面仍面临巨大挑战,往往需要用户进行多次尝试和手动筛选,难以实现稳定、高质量的「一步到位」式编辑。

香港科技大学KnowComp实验室提出基于《欧盟人工智能法案》和《GDPR》的LLM安全新范式,构建合规测试基准并训练出性能优异的推理模型,为大语言模型安全管理提供了新方向。

年初的 DeepSeek-R1,带来了大模型强化学习(RL)的火爆。无论是数学推理、工具调用,还是多智能体协作,GRPO(Group Relative Policy Optimization)都成了最常见的 RL 算法。
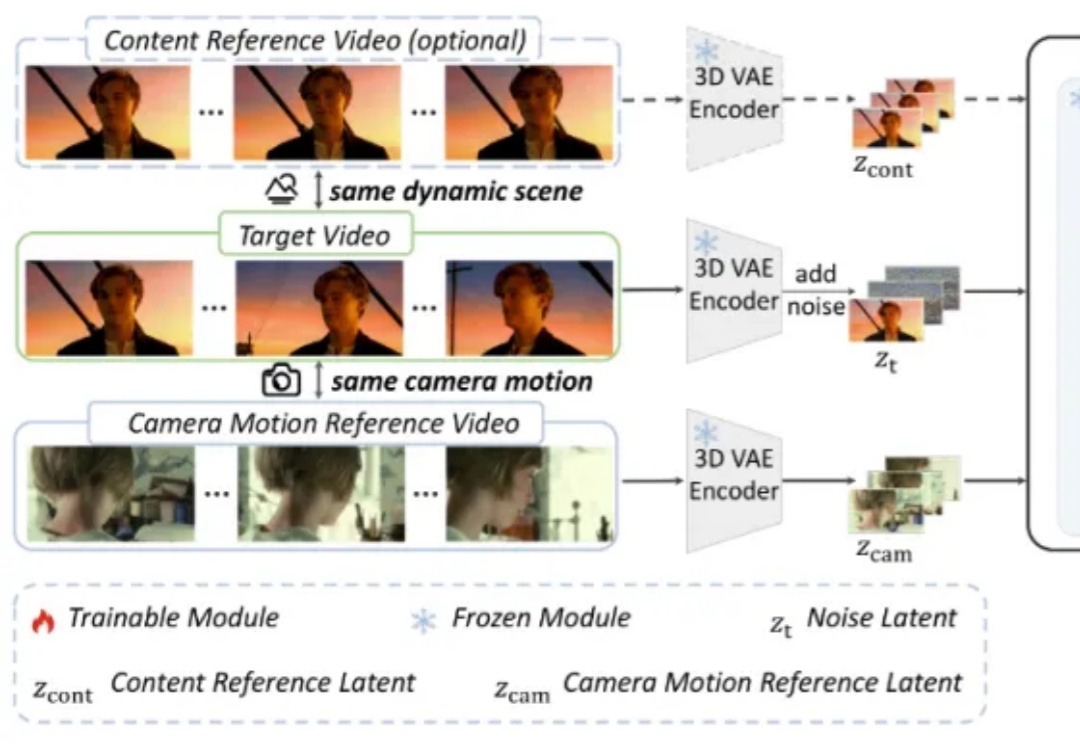
作为视频创作者,你是否曾梦想复刻《盗梦空间》里颠覆物理的旋转镜头,或是重现《泰坦尼克号》船头经典的追踪运镜?

学术展示视频作为科研交流的重要媒介,制作过程仍高度依赖人工,需要反复进行幻灯片设计、逐页录制和后期剪辑,往往需要数小时才能产出几分钟的视频,效率低下且成本高昂,这凸显了推动学术展示视频自动化生成的必要性。