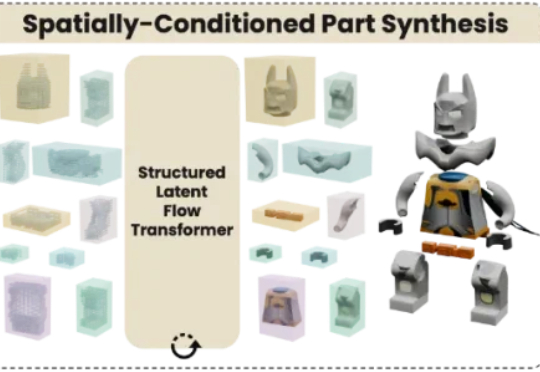
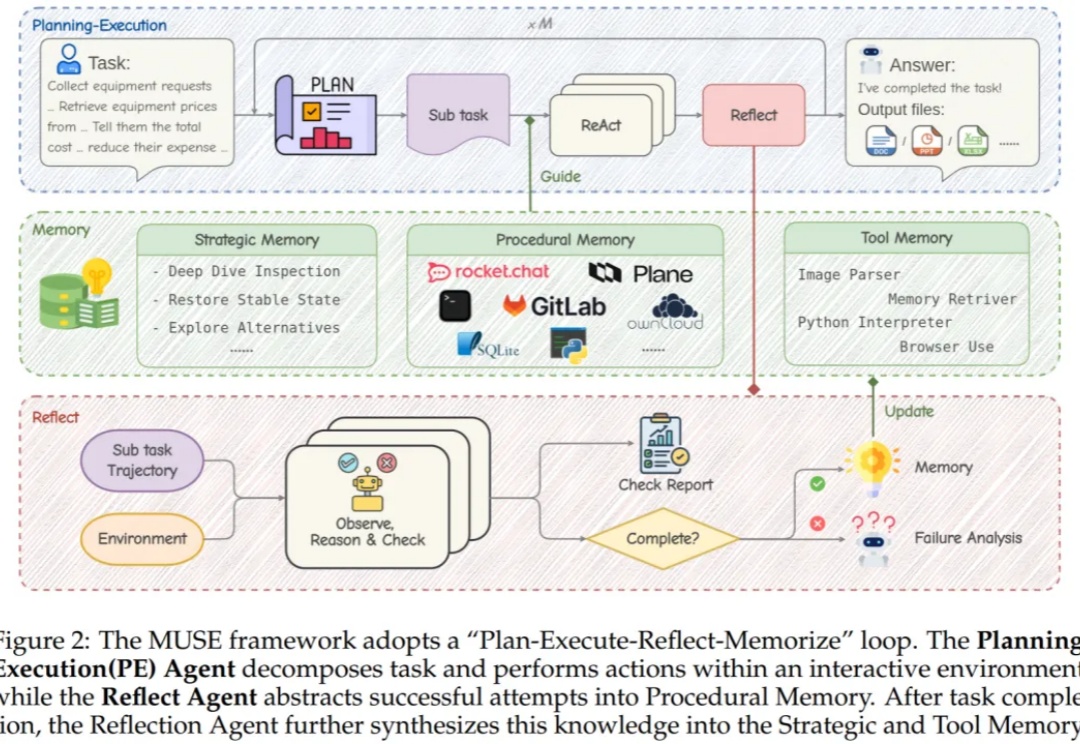
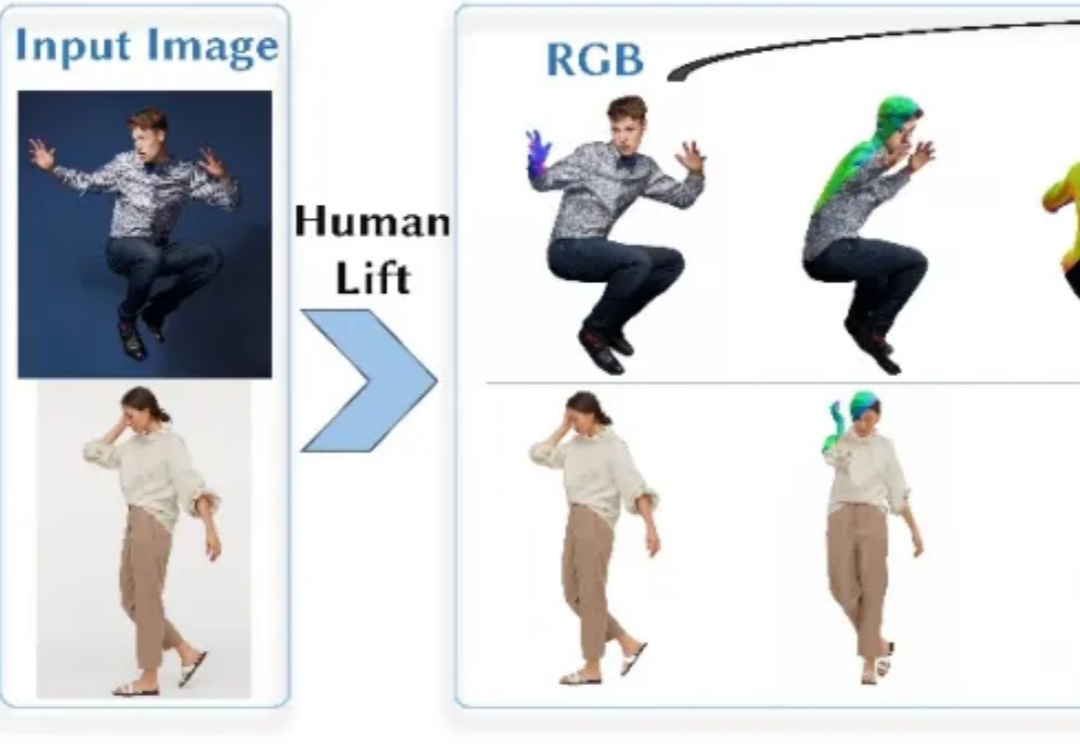
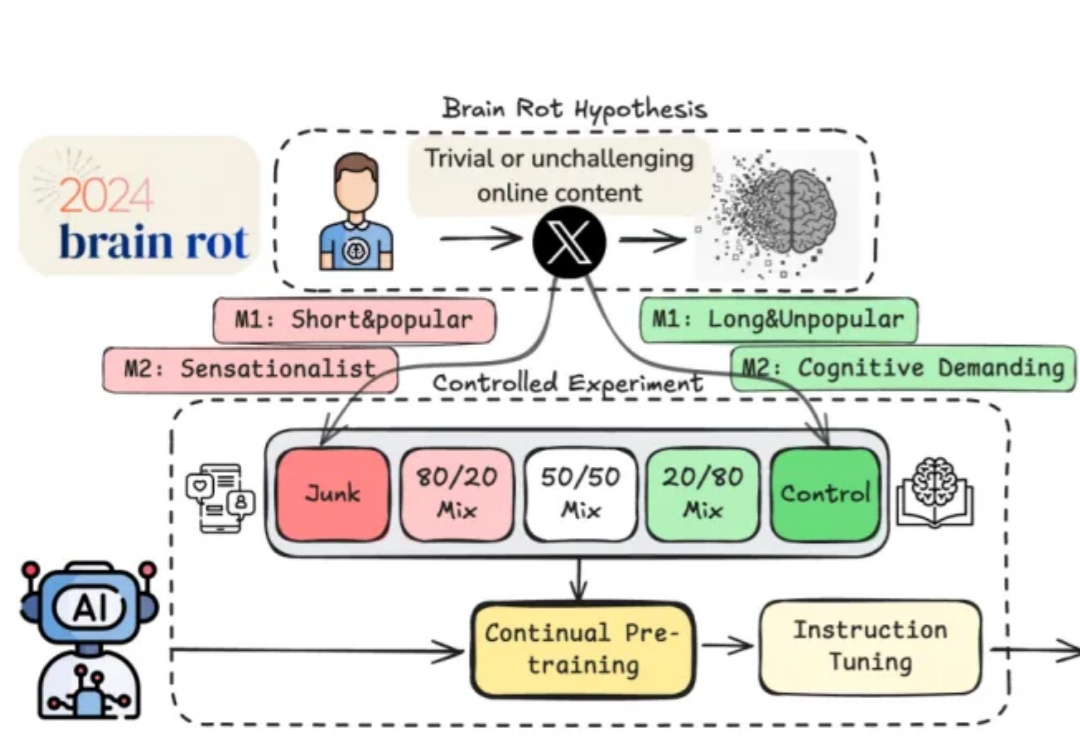
比Transformer更强的架构来了?浙大新作Translution,一统卷积和自注意力
比Transformer更强的架构来了?浙大新作Translution,一统卷积和自注意力近日,范鹤鹤(浙江大学)、杨易(浙江大学)、Mohan Kankanhalli(新加坡国立大学)和吴飞(浙江大学)四位老师提出了一种具有划时代意义的神经网络基础操作——Translution。 该研究认为,神经网络对某种类型数据建模的本质是:
来自主题: AI技术研报
10125 点击 2025-10-23 10:59