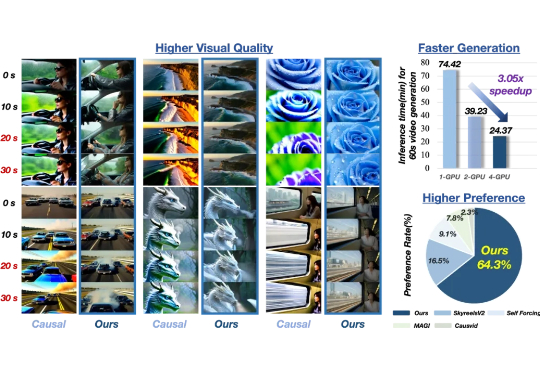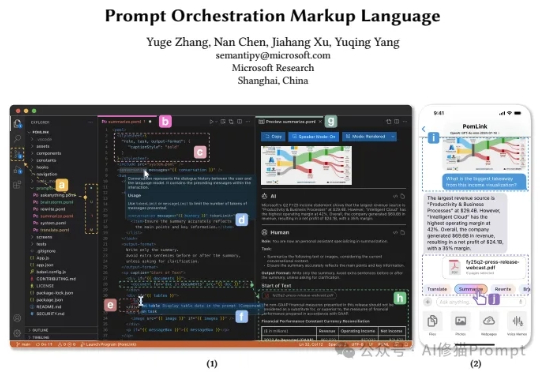
搞不定有表格数据和多模态的Prompt?试下微软最新的提示词编排标记语言POML
搞不定有表格数据和多模态的Prompt?试下微软最新的提示词编排标记语言POML最近来自微软的研究者们带来了一个全新的思路,他们开源发布了POML(Prompt Orchestration Markup Language),它的的解决方案它的核心思想非常直接:为什么我们不能像开发网页一样,用工程化的思维来构建和管理我们的Prompt呢?这个编排语言很类似IBM的PDL
来自主题: AI技术研报
9351 点击 2025-08-27 11:11