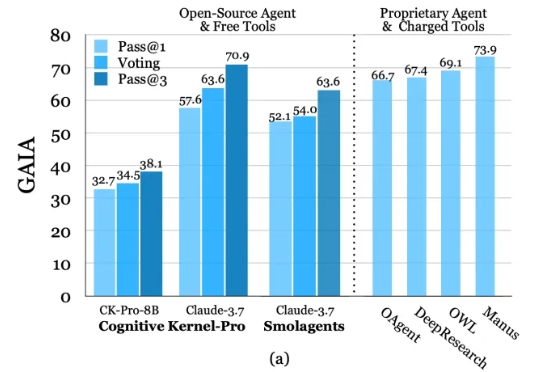
腾讯AI Lab开源可复现的深度研究智能体,最大限度降低外部依赖
腾讯AI Lab开源可复现的深度研究智能体,最大限度降低外部依赖深度研究智能体(Deep Research Agents)凭借大语言模型(LLM)和视觉-语言模型(VLM)的强大能力,正在重塑知识发现与问题解决的范式。
来自主题: AI资讯
8411 点击 2025-08-06 15:38
 搜索
搜索
深度研究智能体(Deep Research Agents)凭借大语言模型(LLM)和视觉-语言模型(VLM)的强大能力,正在重塑知识发现与问题解决的范式。
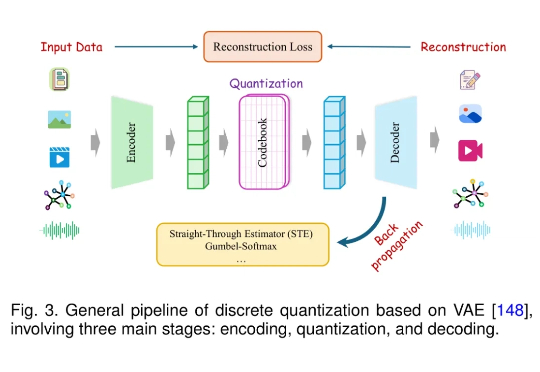
近年来,大语言模型(LLM)在语言理解、生成和泛化方面取得了突破性进展,并广泛应用于各种文本任务。随着研究的深入,人们开始关注将 LLM 的能力扩展至非文本模态,例如图像、音频、视频、图结构、推荐系统等。
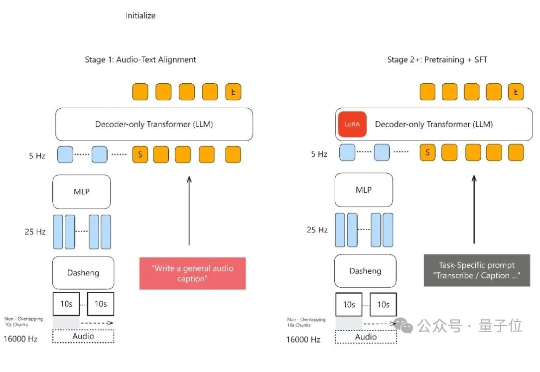
声音理解能力新SOTA,小米全量开源了模型。 MiDashengLM-7B,基于Xiaomi Dasheng作为音频编码器和Qwen2.5-Omni-7B Thinker作为自回归解码器,通过创新的通用音频描述训练策略,实现了对语音、环境声音和音乐的统一理解。
在数据隐私日益重要的 AI 时代,如何在保护用户数据的同时高效运行机器学习模型,成为了学术界和工业界共同关注的难题。

世界是动态变化的。为了理解这个动态变化的世界并在其中运行,AI 模型必须具备在线学习能力。为此,该领域提出了一种新的性能指标 —— 适应性遗憾值(adaptive regret),其定义为任意区间内的最大静态遗憾值。
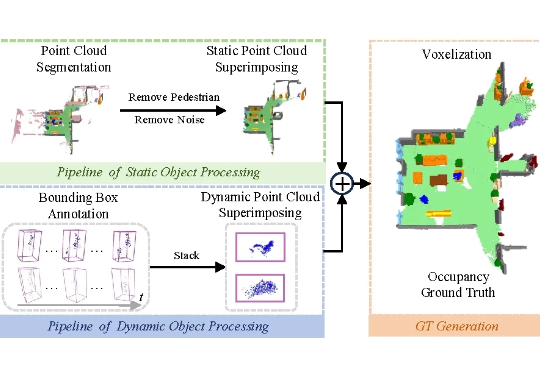
凭借类人化的结构设计与运动模式,人形机器人被公认为最具潜力融入人类环境的通用型机器人。其核心任务涵盖操作 (manipulation)、移动 (locomotion) 与导航 (navigation) 三大领域,而这些任务的高效完成,均以机器人对自身所处环境的全面精准理解为前提。
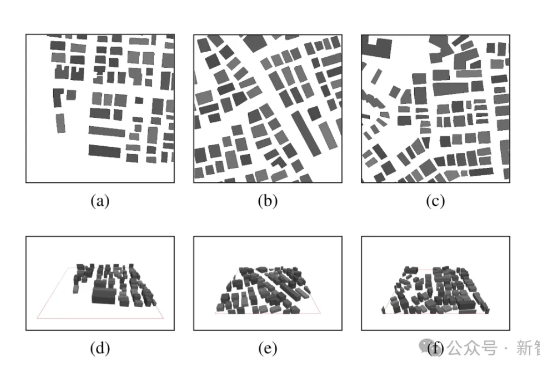
当前环境感知通信正逐步成为第六代移动通信系统(6G)的核心使能技术之一。为支撑其在复杂三维环境下的部署需求,西安电子科技大学、香港中文大学(深圳)和加拿大滑铁卢大学的研究团队联合提出了一个面向6G的高分辨率多模态三维无线电图谱数据集UrbanRadio3D,并构建了基于扩散模型的三维无线电图生成框架RadioDiff-3D。
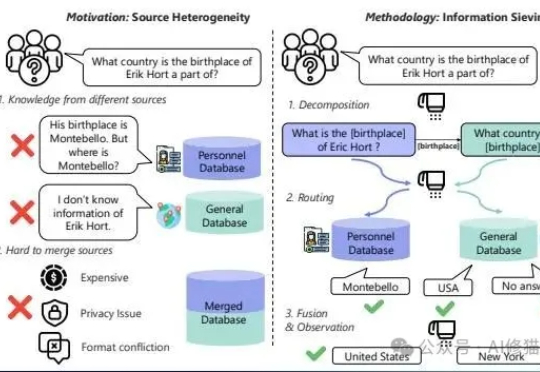
现在的RAG(检索增强生成)系统。您给它一个简单直接的问题,它能答得头头是道
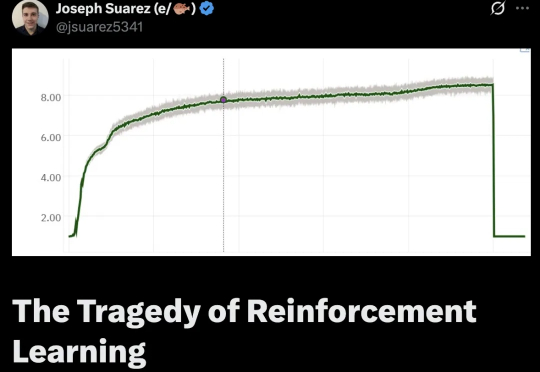
AlphaStar等证明强化学习在游戏等复杂任务上,表现出色,远超职业选手!那强化学习怎么突然就不行了呢?强化学习到底是怎么走上歧路的?

除了是知名 AI 播客「No Priors」的主理人之外,Sarah Guo 更知名的身份,是风险投资 Conviction 的创始人。