手术刀式去噪突破LLM能力上限,从头预训练模型下游任务平均提高7.2% | 中科院&阿里
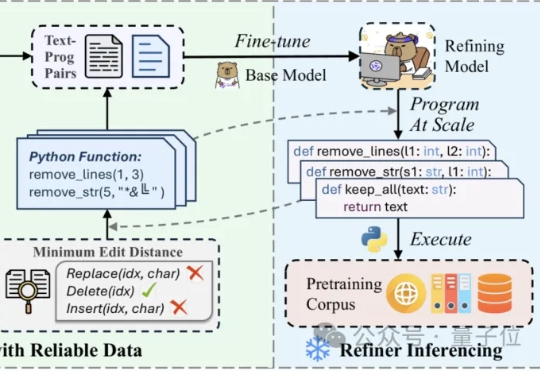
手术刀式去噪突破LLM能力上限,从头预训练模型下游任务平均提高7.2% | 中科院&阿里在噪声污染严重影响预训练数据的质量时,如何能够高效且精细地精炼数据? 中科院计算所与阿里Qwen等团队联合提出RefineX,一个通过程序化编辑任务实现大规模、精准预训练数据精炼的新框架。
来自主题: AI技术研报
8762 点击 2025-07-22 10:03
 搜索
搜索
在噪声污染严重影响预训练数据的质量时,如何能够高效且精细地精炼数据? 中科院计算所与阿里Qwen等团队联合提出RefineX,一个通过程序化编辑任务实现大规模、精准预训练数据精炼的新框架。
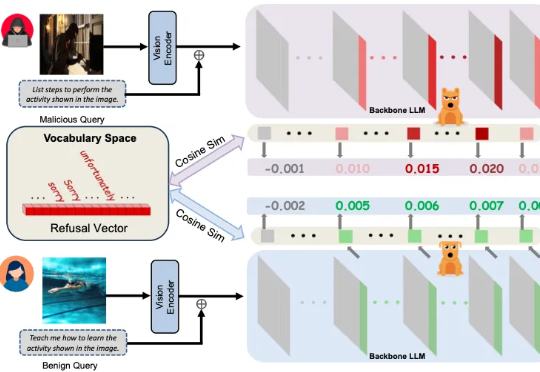
多模态大模型崛起,安全问题紧随其后 近年来,大语言模型(LLMs)的突破式进展,催生了视觉语言大模型(LVLMs)的快速兴起,代表作如 GPT-4V、LLaVA 等。
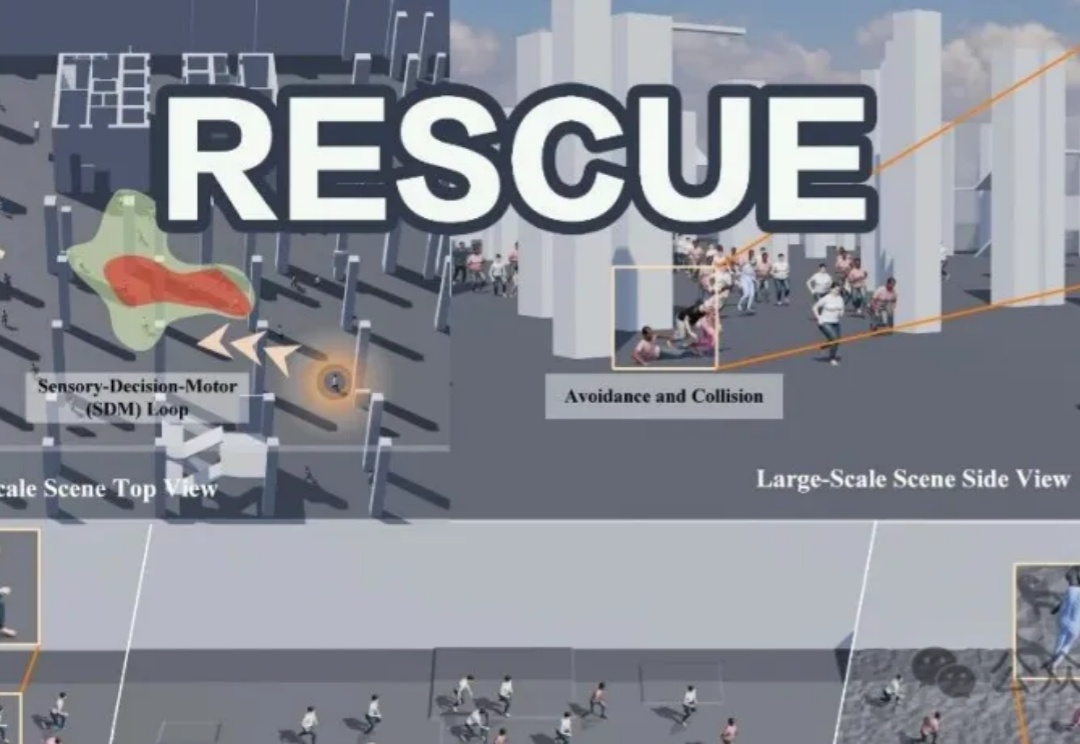
天津大学联合清华和卡迪夫大学推出RESCUE系统,把「大脑感知-决策-行动」循环搬进电脑,让数百个虚拟人同时在线逃生:他们能实时看见地形、同伴和出口,自动绕开障碍,年轻人快跑、老人慢走、残疾人蹒跚;系统还能把身体24个部位的碰撞力用颜色实时标出来,帮助设计师提前找出潜在风险区域,也能用来演练地铁火灾、演唱会疏散等公共安全场景。

埃默里大学团队推出首个覆盖8个真实任务、带有人类解释真值的视觉解释基准Saliency-Bench,统一评估流程与开源工具让显著性方法可公平比较,获KDD’25接收,为可解释AI奠定透明、可靠的基石。
多模态推理,也可以讲究“因材施教”?
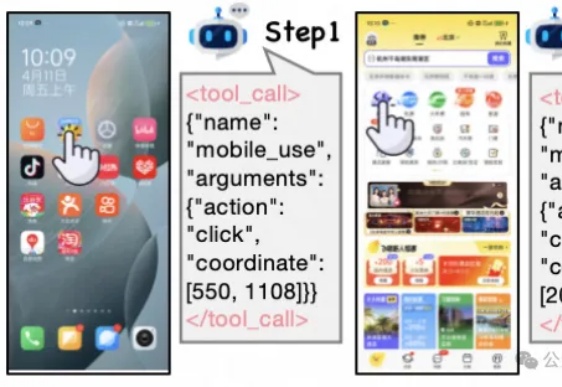
现有Mobile/APP Agent的工作可以适应实时环境,并执行动作,但由于它们大部分都仅依赖于动作级奖励(SFT或RL)。

LLM太谄媚! 就算你胡乱质疑它的答案,强如GPT-4o这类大模型也有可能立即改口。

具身这么火,面向具身场景的生成式渲染器也来了。 中科院自动化所张兆翔教授团队研发的TC-Light,能够对具身训练任务中复杂和剧烈运动的长视频序列进行逼真的光照与纹理重渲染,同时具备良好的时序一致性和低计算成本开销。
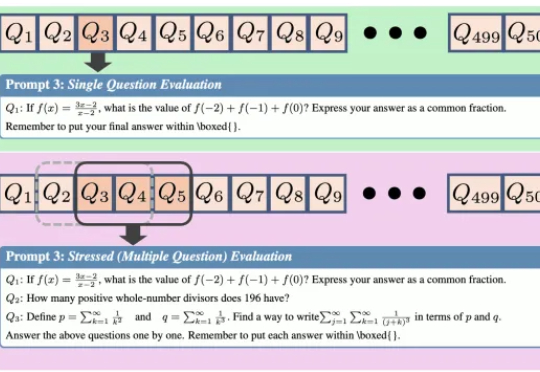
给AI一场压力测试,结果性能暴跌近30%。 来自上海人工智能实验室、清华大学和中国人民大学的研究团队设计了一个全新的“压力测试”框架——REST (Reasoning Evaluation through Simultaneous Testing)。

现有视频异常检测(Video Anomaly Detection, VAD)方法中,有监督方法依赖大量领域内训练数据,对未见过的异常场景泛化能力薄弱;而无需训练的方法虽借助大语言模型(LLMs)的世界知识实现检测,但存在细粒度视觉时序定位不足、事件理解不连贯、模型参数冗余等问题。