
大模型再爆弱点!旧记忆忘不掉,新记忆分不出,准确率暴降 | ICML'25
大模型再爆弱点!旧记忆忘不掉,新记忆分不出,准确率暴降 | ICML'25大模型有苦恼,记性太好,无法忘记旧记忆,也区分不出新记忆!基于工作记忆的认知测试显示,LLM的上下文检索存在局限。在一项人类稳定保持高正确率的简单检索任务中,模型几乎一定会混淆无效信息与正确答案。
来自主题: AI技术研报
7823 点击 2025-07-21 10:27
 搜索
搜索
大模型有苦恼,记性太好,无法忘记旧记忆,也区分不出新记忆!基于工作记忆的认知测试显示,LLM的上下文检索存在局限。在一项人类稳定保持高正确率的简单检索任务中,模型几乎一定会混淆无效信息与正确答案。

MiniMax 在 7 月 10 日面向全球举办了 M1 技术研讨会,邀请了来自香港科技大学、滑铁卢大学、Anthropic、Hugging Face、SGLang、vLLM、RL领域的研究者及业界嘉宾,就模型架构创新、RL训练、长上下文应用等领域进行了深入的探讨。

随着基础大模型在通用能力上的边际效益逐渐递减、大模型技术红利向产业端渗透,AI的技术范式也开始从原来的注重“预训练”向注重“后训练”转移。后训练(Post-training),正从过去锦上添花的“调优”环节,演变为决定模型最终价值的“主战场”。
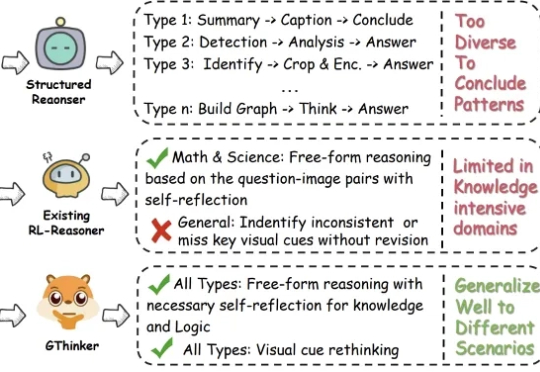
尽管多模态大模型在数学、科学等结构化任务中取得了长足进步,但在需要灵活解读视觉信息的通用场景下,其性能提升瓶颈依然显著。

程序员最有价值的技能已经不再是编写代码了,而是精确地向 AI 传达意图。一份完善的规范才是包含完整意图的真正「源代码」。

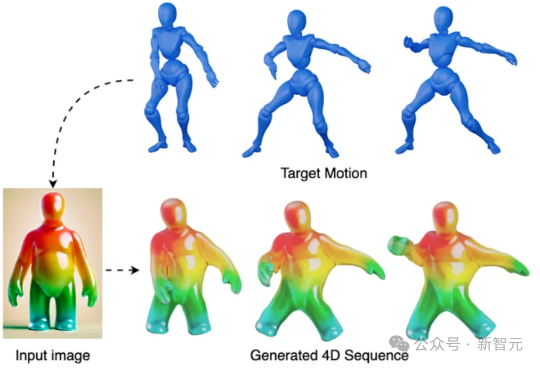
只需一段视频,就可以直接生成可用的4D网格动画?!来自KAUST的研究团队提出全新方法V2M4,能够实现从单目视频直接生成高质量、显式的4D网格动画资源。
PhysRig是UIUC与Stability AI联合提出的首个面向角色动画的可微物理绑定框架。通过将刚性骨架嵌入弹性软体体积,并使用Material Point Method(MPM)进行可微分物理模拟,PhysRig能够自然还原皮肤、脂肪、尾巴等柔性结构的变形过程,显著提升角色动画的真实感,解决传统LBS无法克服的体积丢失与变形伪影问题。
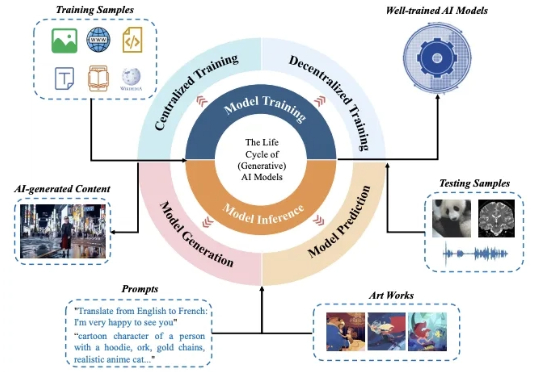
你是否也曾担心过,随手发给 AI 助手的一份代码或报告,会让你成为下一个泄密新闻的主角?又或是你在网上发布的一张画作,会被各种绘画 AI 批量模仿并用于商业盈利?
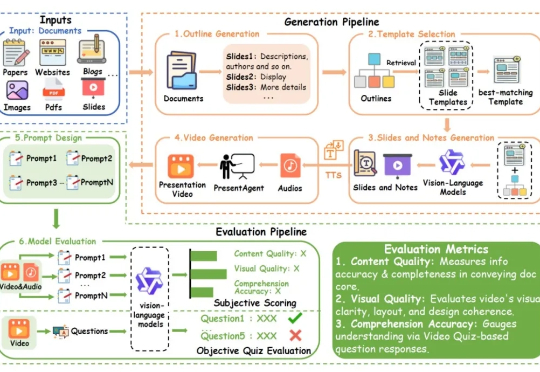
我们提出了 PresentAgent,一个能够将长篇文档转化为带解说的演示视频、多模态智能体。现有方法大多局限于生成静态幻灯片或文本摘要,而我们的方案突破了这些限制,能够生成高度同步的视觉内容和语音解说,逼真模拟人类风格的演示。
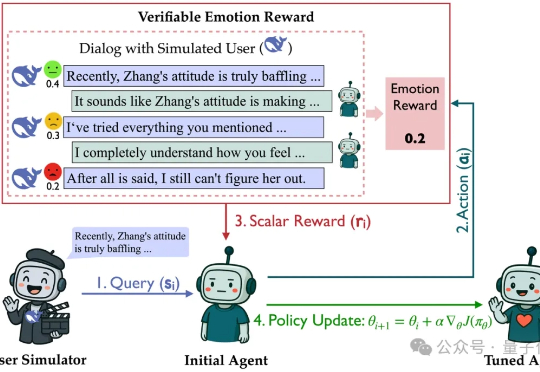
在没有标准答案的开放式对话中,RL该怎么做?多轮对话是大模型最典型的开放任务:高频、多轮、强情境依赖,且“好回复”因人而异。