
MBench: 清华x腾讯联合定义视频世界模型的长期记忆能力
MBench: 清华x腾讯联合定义视频世界模型的长期记忆能力随着视频生成技术的发展,模型正在从短视频片段合成,向流式长视频生成演进。然而,仅仅做到视觉上的逼真是不够的。一个功能完备的视频世界模型,必须能够在长时序交互中保持稳定的内部状态,并遵循真实世界的物理定律与逻辑规则。
来自主题: AI技术研报
9667 点击 2026-06-11 14:30
 搜索
搜索
随着视频生成技术的发展,模型正在从短视频片段合成,向流式长视频生成演进。然而,仅仅做到视觉上的逼真是不够的。一个功能完备的视频世界模型,必须能够在长时序交互中保持稳定的内部状态,并遵循真实世界的物理定律与逻辑规则。
想象一下,你问 AI 要一个饮食记录工具,它不再是回你一段文字建议,而是直接给你一个可以点击添加、统计热量的完整应用。人和 AI 的交互,正在从「读文字」走向「用应用」。
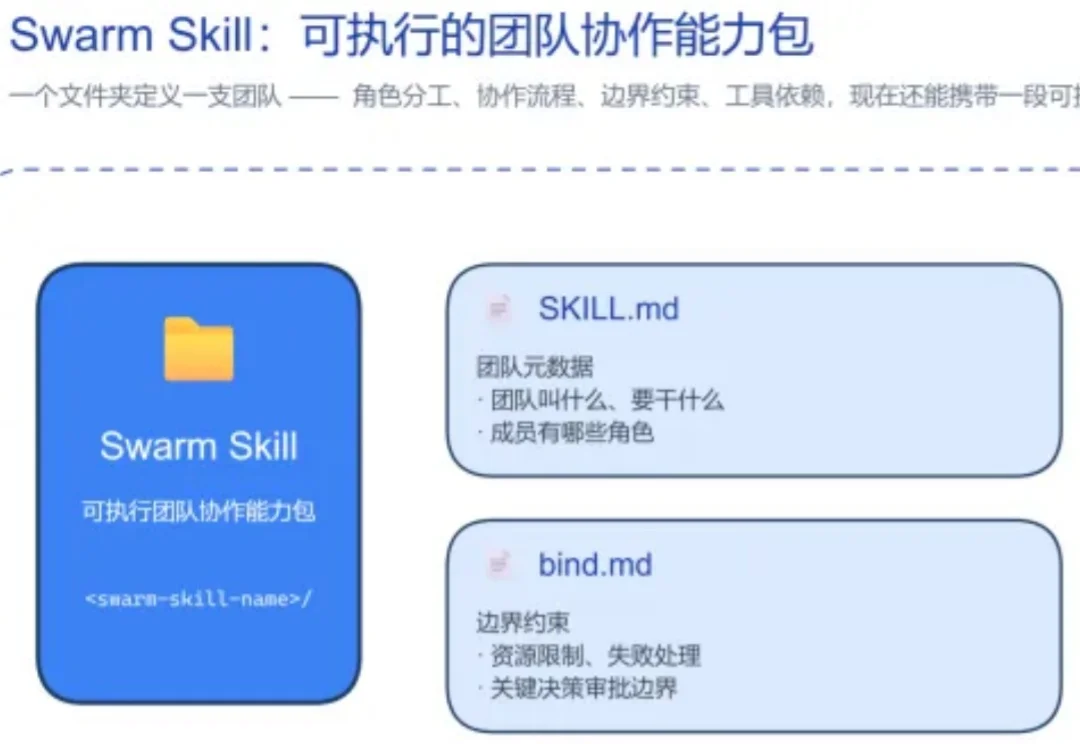
AI Agent 正在从 "单兵作战" 走向 "团队协作"—— 让多个 Agent 分工配合,去完成单个 Agent 难以独立扛下来的复杂任务,也是近期最受关注的方向之一。
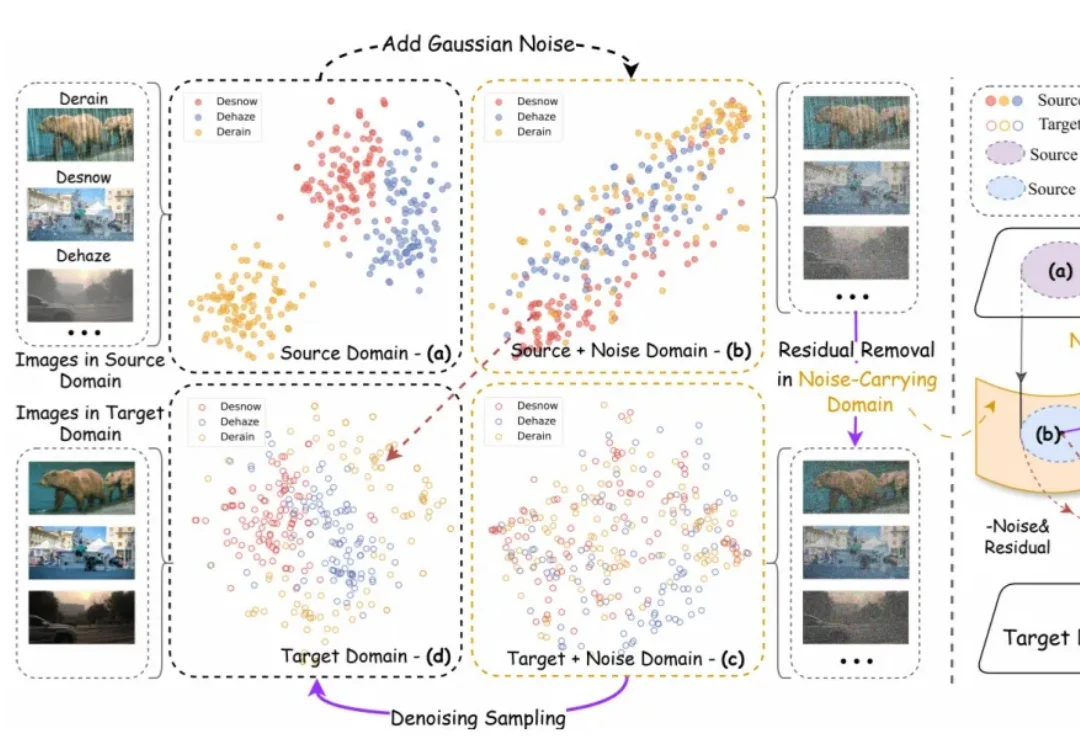
在图像到图像翻译(Image-to-Image Translation, I2I)这个任务上,扩散模型过去几年几乎形成了一套默认逻辑:先把输入图像和噪声混合,再一步步去噪,把目标图像 “还原” 出来。

具身智能现在面临的问题,和自动驾驶几年前的困境非常相似。
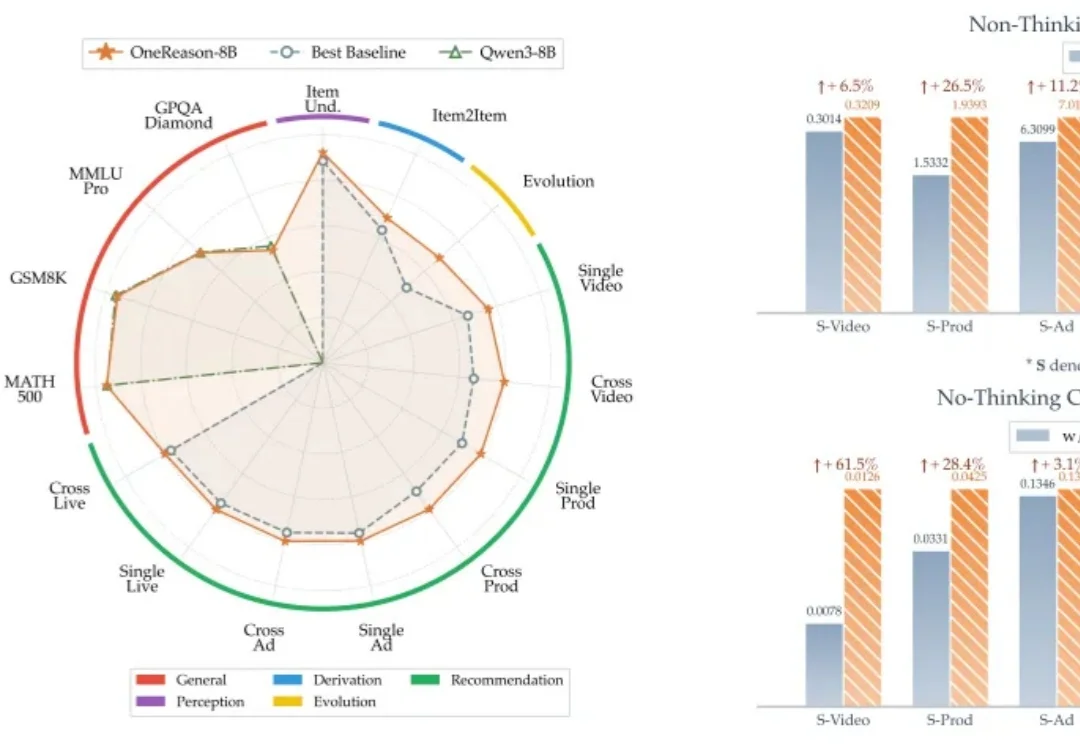
推荐系统的过去十年,本质是把 "用户 - 物料" 的统计共现挖到极致 —— 从协同过滤、深度模型,到生成式 OneRec 系列,每一代都在让 "记忆" 更精细、参数更大、序列更长,也让 Scaling 这件事在工业级推荐系统上跑通,持续释放算力红利。

Transformer 依托强大的建模能力和 Scaling 效率在推荐领域被广泛应用于超长序列建模和生成式推荐等方向,
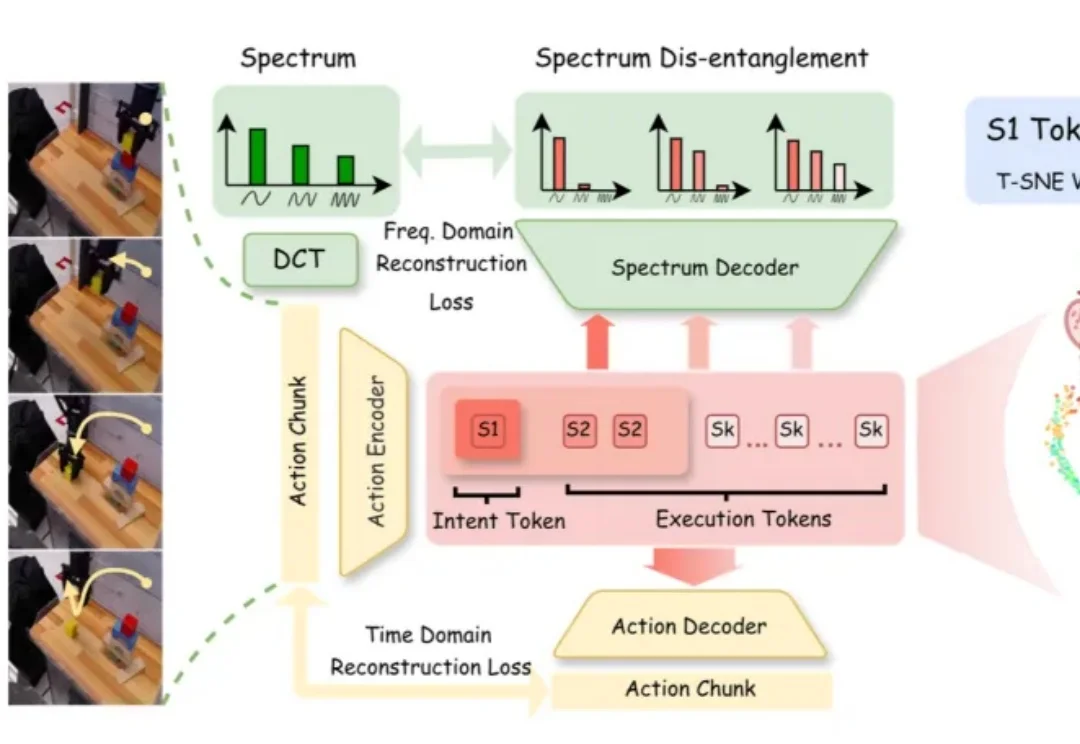
机器人视觉语言动作(Vision-Language-Action, VLA)模型越来越多地开始展示叠衣服、倒茶、做咖啡等复杂操作。但是,今天的大多数 VLA 更像 “展台机器人”。

过去两年,大模型写代码已经不再新鲜。从代码补全到 GitHub issue 修复,从竞赛编程到仓库级软件工程,人们习惯用一个简单标准评估 coding agent:代码能不能写对?测试能不能通过?

Meta 发布了一项令人震撼的研究工作 VLM³,首次揭示了三维视觉学习的 Bitter Lesson:标准的视觉语言模型 + scale 数据就是最简单有效的范式,针对特定任务的架构、损失函数以及数据增强的设计,甚至是 regression 的 formulation,均不是三维视觉学习的必要条件。