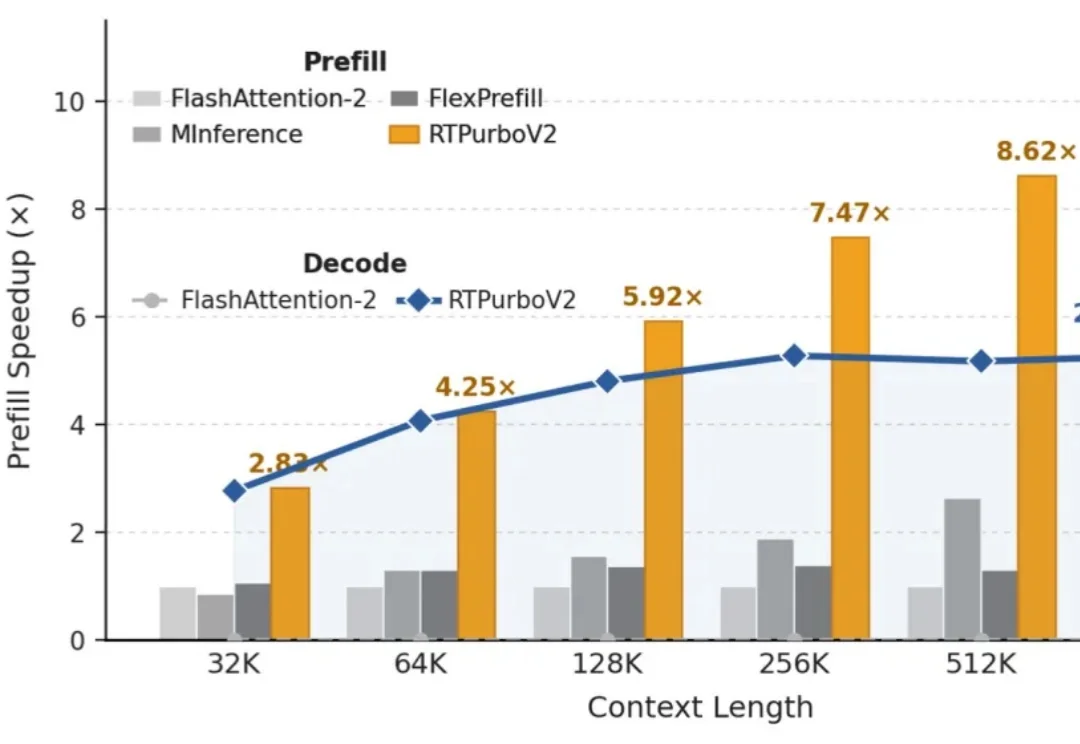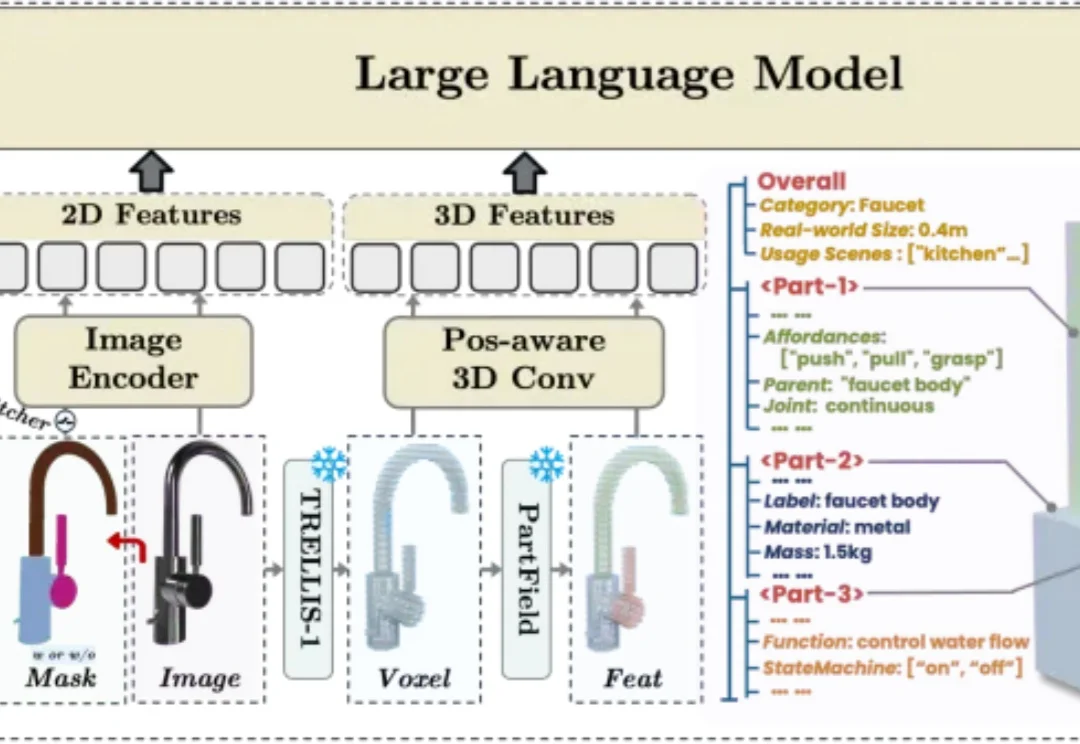
ICML 2026 | PhysForge框架来了,让3D资产从静态模型变成可交互对象
ICML 2026 | PhysForge框架来了,让3D资产从静态模型变成可交互对象在交互式虚拟世界和具身智能快速发展的今天,高质量 3D 资产已经不再只是 “看起来像” 就足够。一个柜门不仅要有柜门的外观,还需要知道绕哪条轴旋转;一个按钮不仅要有按钮的形状,还需要具备 “按下 / 弹起” 的状态;一个抽屉不仅要有完整几何,还需要拥有滑动方向、运动范围、材质和质量等物理属性。该研究已被 ICML 2026 接收。
来自主题: AI技术研报
8143 点击 2026-06-09 14:08